
Gradient-Based Learning Applied to Document Recognition 部分阅读
卷积网络
卷积网络用三种结构来确保移位、尺度和旋转不变:局部感知野、权值共享和时间或空间降采样。典型的leNet-5如下图所示:
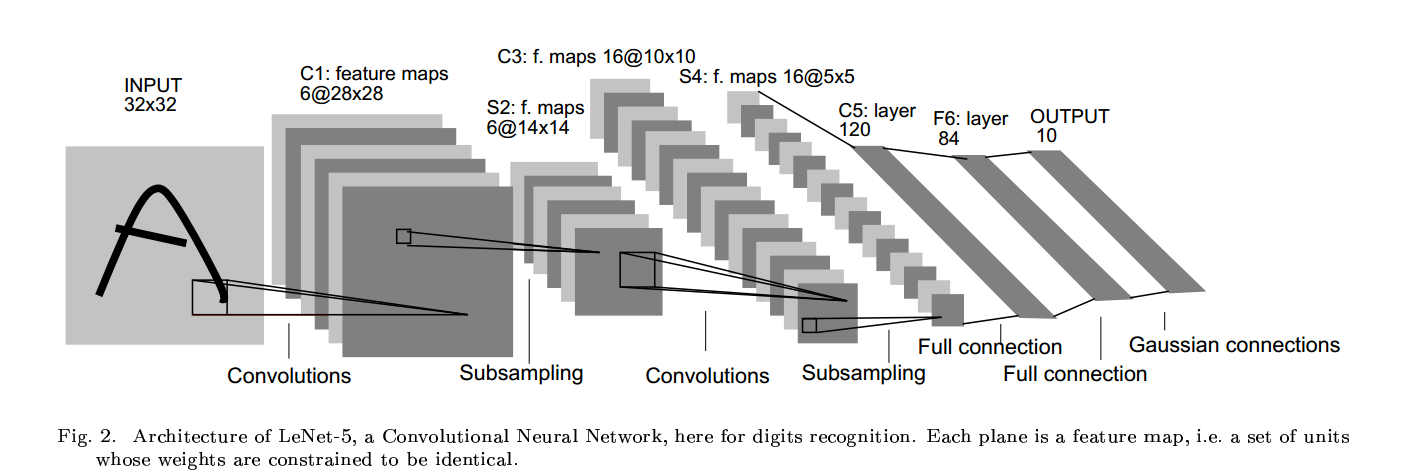
C1中每个特征图的每个单元和输入的25个点相连,这个5*5的区域被称为感知野。特征图的每个单元共享25个权值和一个偏置。其他特征图使用不同的权值(卷积枋),因
此可以得到不同类型的局部特征。卷积层的一个重要思想是,如果图像产生了位移,特征图输出将会产生相同数量的位移。这也是卷积网络位移和形变不变的原理。
特征图检测完毕后,它们的确切位置就不那么重要了,重要的是特征之间的相对位置。特征位置太准确不仅无利于模式识别,还会有害处,因为对不同的字符来说它们的位置是
不同的(所以特征之间的相对位置才是最重要的)。降低位置准确性可以通过下采样来降低分辨率来实现,同是也降低了输出对位移和形变的敏感性。每个单元计算四个输入的平均值(就是采样层),
将下采样的值乘一个训练系数加一个偏置(下采样层连接到sigmod的系数同要需要训练),然后将结果传给激活函数。训练系数和偏置控制了sigmod函数的非线性。如果这个系数很小的话,则每个单元类似于线性模型,下采样层所起的功能仅仅就是模糊输入;如果系数很大,则下采样操作可视为noisy OR或者 noisy AND(取决于偏置的大小)(存疑?)。
leNet-5
leNet-5有七层(不含输入),其中C1有156((5*5+1)*6)个可训练参数,122304(28*28*156)个连接。C2层的一个单元为C1中的2*2所得,输入到激活函数时它们共用一个
系数加一个偏置,所需的训练参数为(1+1)*6=12个,连接参数为(4+1)*6*14*14=5880个(我的理解是只在leNet-5中2*2的感知野值相同)。
C3层有16个特征图,由表格可以看出,每个特征图对S2中的特征图并非是全连接的。共有(25*3+1)*6+(25*4)*9+(25*6+1)=1516个训练参数,连接个数为
1516*10*10=151600个。S4同样为下采样层,有16*(1+1)=32个训练参数,有(2*2+1)*25*16=2000个连接。

C5有120个特征图,同样用5*5的卷积核,与S4层全连接,所以C5的特征是1*1的。之所以C5为卷积层而不是全连接层,是因为当le-Net5的输入增大时,特征图的维度也会大于
1*1。
F6全连接层,有84个单元,与C5全连接,共有(120+1)*84=10164个训练参数。同经经典的神经网络一样,F6乘权重加偏置然后送入到激活函数中。
下面是输出层(好吧,看的不是很明白),参考:http://blog.csdn.net/zouxy09/article/details/8781543

