
Learning a Deep Compact Image Representation for Visual Tracking
这篇博客对论文进行了部分翻译http://blog.csdn.net/vintage_1/article/details/19546953,不过个人觉得博主有些理解有误。
这篇博客简单分析了代码http://www.cnblogs.com/zeadoit/p/4161427.html
本文的DLT算法在无监督特征的学习,是在线下训练阶段使用SDAE从大量图像数据中学到图像特征,首次运用一层一层的预训练,然后整个SDAE就是fine-tuned.
在线跟踪过程中,一个附加的分类层来对部分训练好的SDAE进行编码。
1.Offline Training with Auxiliary Data
1.1.1 Dataset and Preprocessing
预处理做的不多,包括把32*32的图像转为1024*1的向量,每维的特征值被归一化。
1.1.2 Learning Generic Image Features with a Stacked Denoising Autoencoder
DAE的优化问题可表示为如下形式:
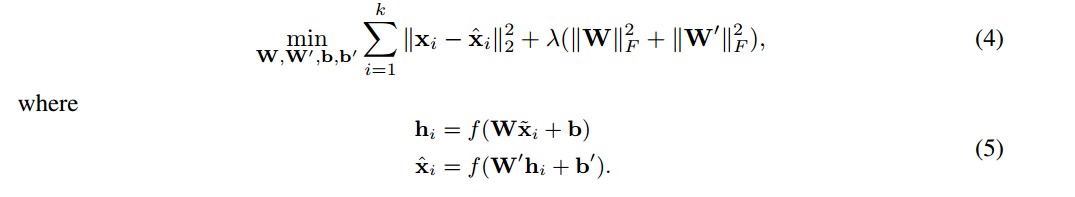
为了更进一步的学习到有意义的特征,对隐藏神经元的激活值施加稀疏性约束:
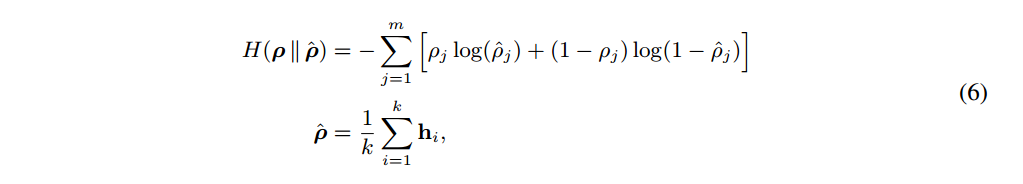
预训练之后,SDAE可看作一个前馈神经网络。
在第一层使用一个完备的滤波器来学习图像的特征,当新的一层加入时,神经元的个数减半,直到减到256个神经元,作为自编码器的bottleneck。
为了加速第一层的预训练学习局部特征的过程,把32*32的图像分成16*16(除了四个角外,中间还有一个,会与四个角重叠)。然后训练5个DAEs,每个
有512隐含单元。然后将5个DAE组合成一个大的DAE并正常训练。第一层随机选择的滤波器如图所示,可以看出大部分滤波器起的是边缘检测的作用。

1.2 Online Tracking Process
跟踪目标在第一帧里用边框框出来。一个sigmoid分类层添加到离线训练好的SDAE的编码器之后,整体网络如Fig1所示。当一个新的视频帧到来,我们首先撒粒子(一个粒子就是目标可能存在的一块图像,32*32),每个粒子的可信度(即与首帧提取的特征的想似度)通过网络前向传播确定。这种方法在这一步的计算量非常小但准确度很高。如果所有粒子的最大可信度小于预定的阈值,就表示追踪目标的外观发生了巨大改变。为解决这个问题,一旦发生这种情况,这个网络可以再次tune。阈值的设定是一个tradeoff,如果太小,跟踪器不能很好地适应目标的外表变换;如果太大,遮挡物体和背景都有可能被当做跟踪目标,从而造成跟踪从目标漂移。
整个过程仍然是粒子滤波框架,只是将人工特征变成了自动提取特征并通过网络来确定可信度。具体实现还需参考代码。

