

stable diffusion (一) 概述
前段时间看了台湾大学李宏毅教授关于diffusion模型的课程,记录一下
1、Framework
diffusion model包括3个部分,核心是generation model。
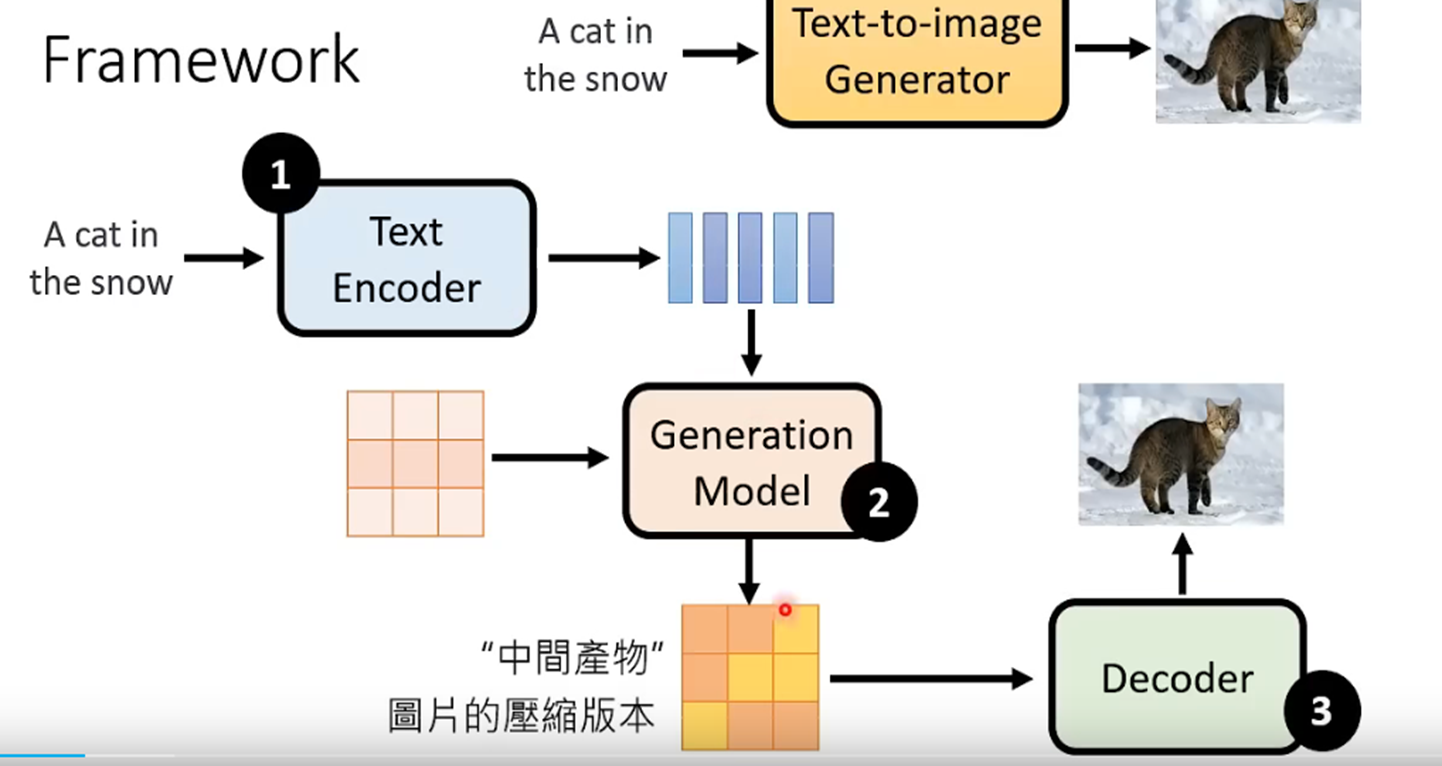
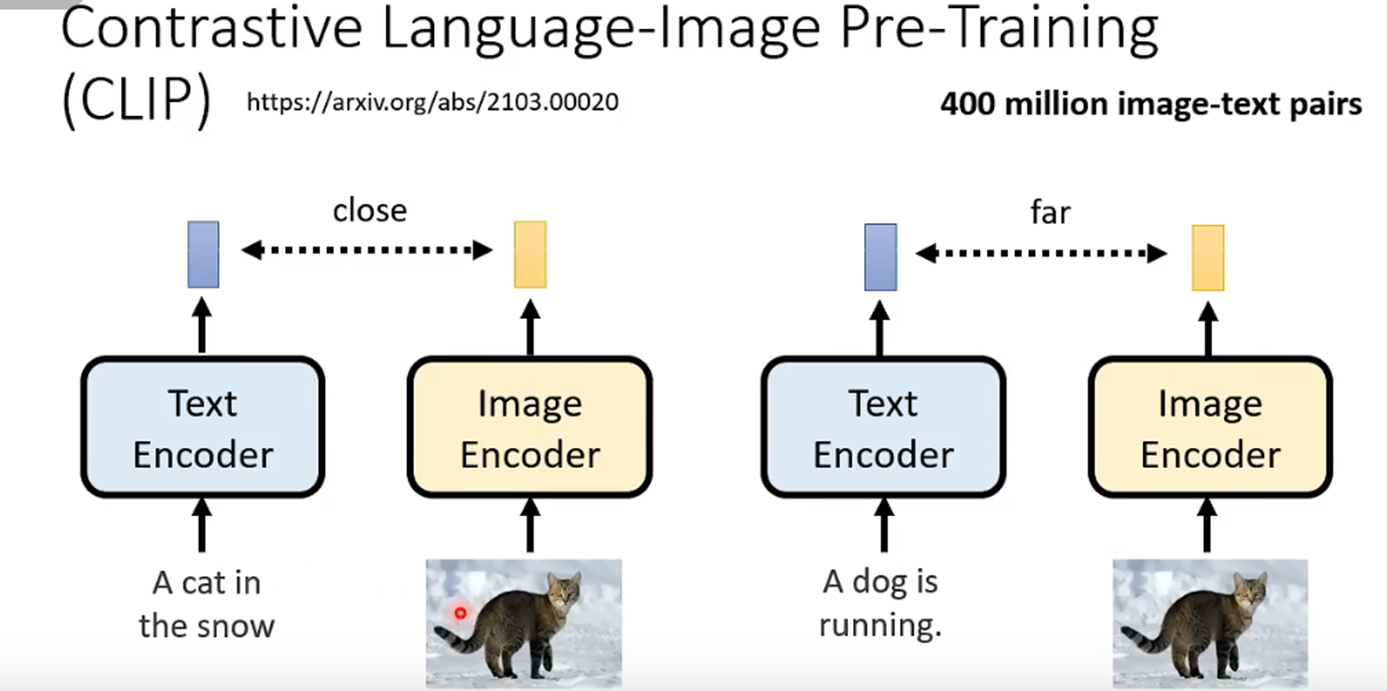
(1) Text encoder。可以用bert,chatgpt之类的来生成embedding,或者使用clip。这部分是提前训练好的
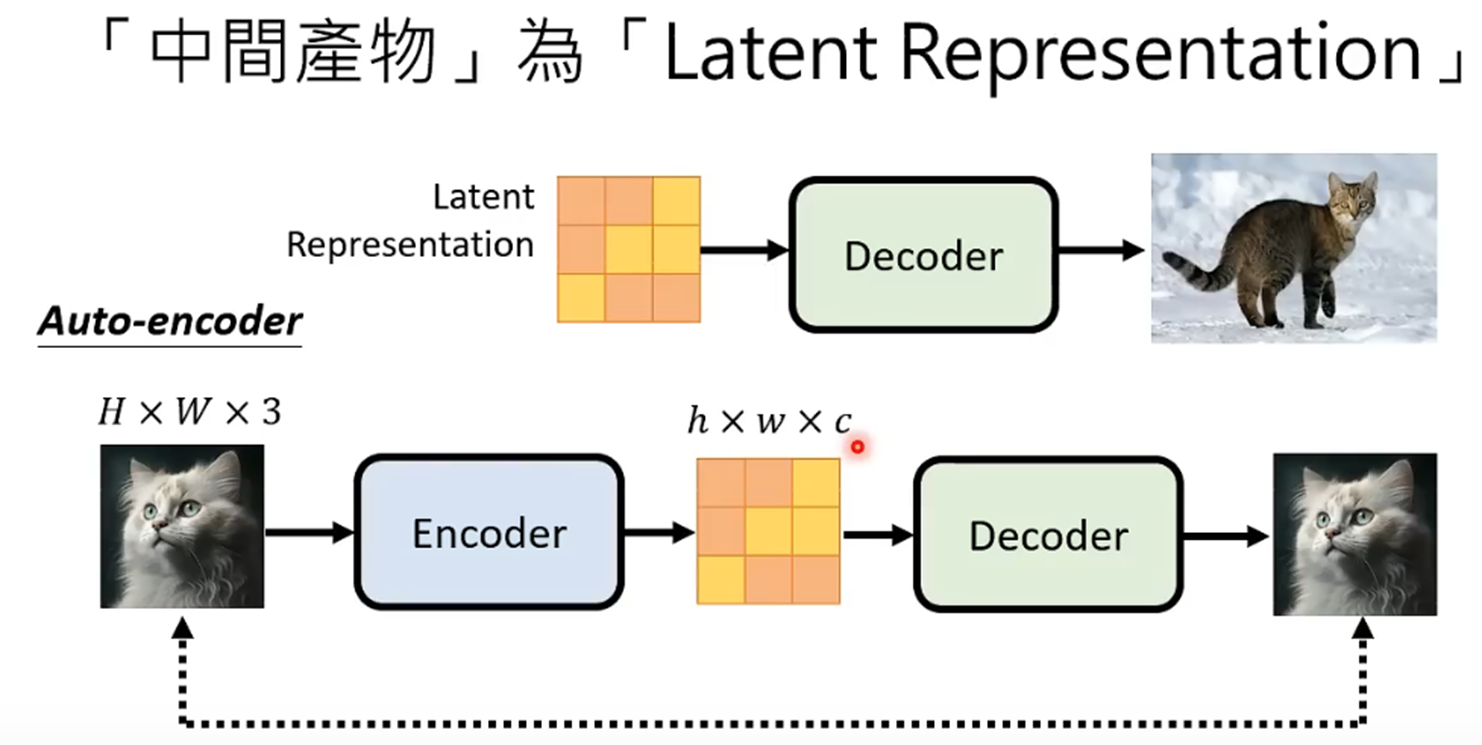
(2)Decoder。一个简单的encoder-decoder模型,可以直接拿图像来做训练,不需要标签。注意:这里的encoder只在训练的时候使用,生成阶段
不会使用。也是需要提前训练好。
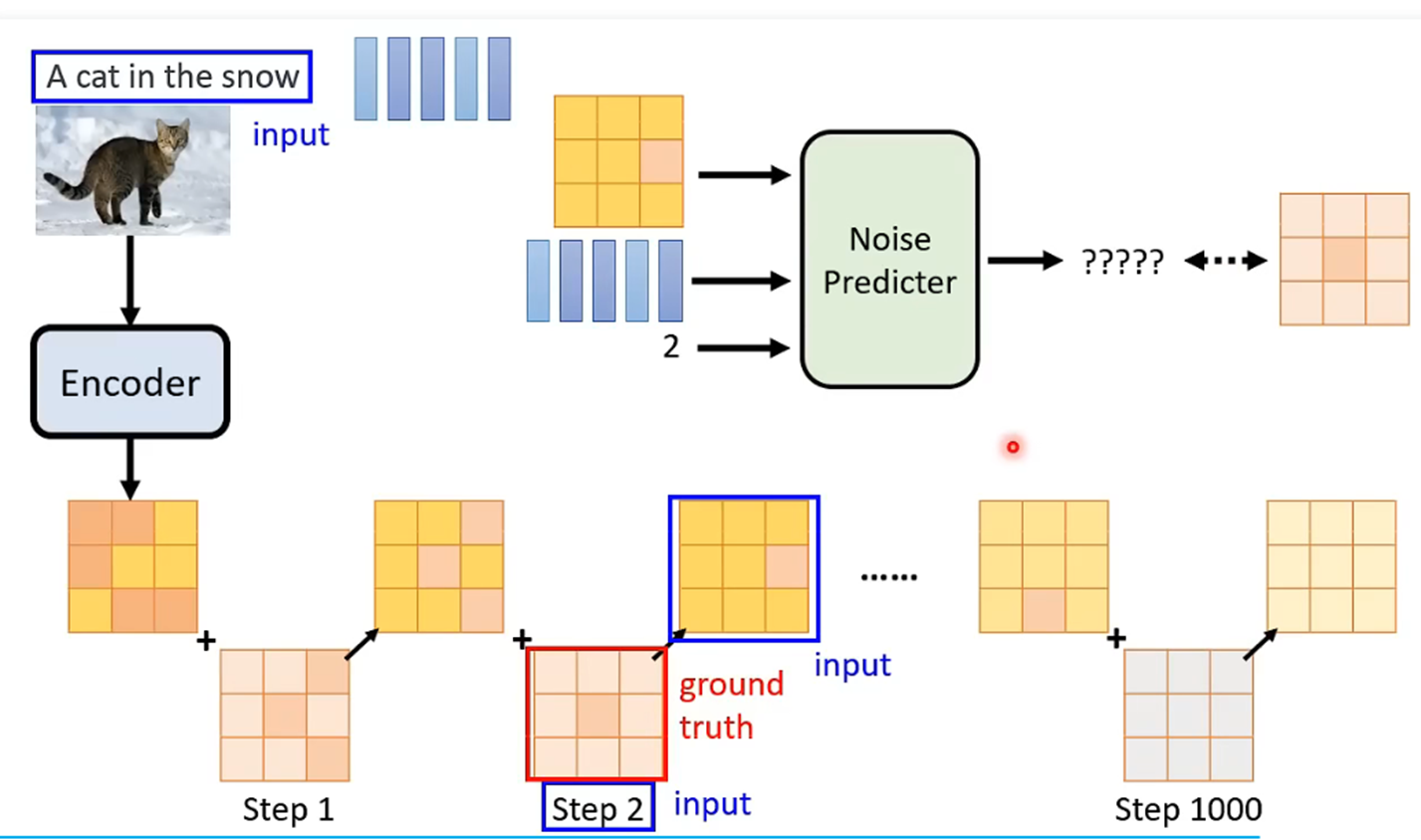
(3)generation model。训练的时候先对图像进行encoder(2中训练好的encoder),得到latent represention,然后对latent represention循环的
加噪声,去训练模型的denoise能力,输出是预测的噪声。
b站上有人搬运了课程(正课)速览图像生成常见模型_哔哩哔哩_bilibili


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架
2016-04-03 CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
2016-04-03 Morris Traversal方法遍历