

爬虫学习《一》
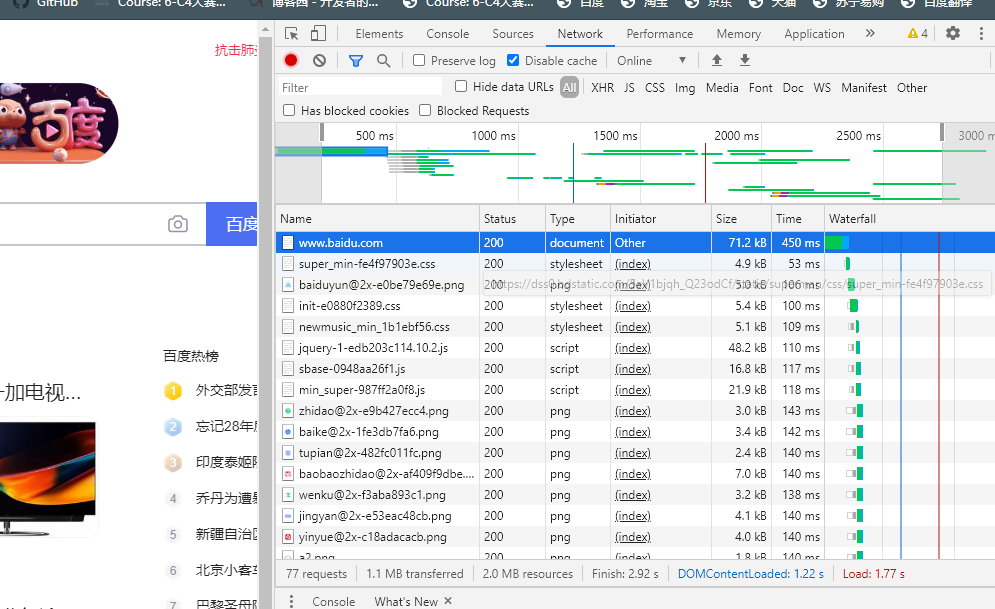
1.第一列Name:请求的名称,一般会将URL的最后一部分内容当作名称。
2.第二列Status: 响应的状态码,这里显示为200,代表响应式正常的。通过状态码,我们可以判断发送了请求之后是否得到了正常的响应。
3.第三列Type:请求的文档类型。这里为document,代表我们这次请求的是一个HTML文档,内容就是一些HTML代码。
4.第四列Initiator: 请求源。用来标记请求是由哪个对象或进程发起的。
5.第五列Size:从服务器下载的文件和请求的资源大小。如果是从缓存中取得的资源,则该列会显示from cache。
6.第六列Time:发起请求到获取响应所用的总时间。
7.第七列Waterfall:网络请求的可视化瀑布流。
点击www.baidu.com ,可以看到更详细的信息。
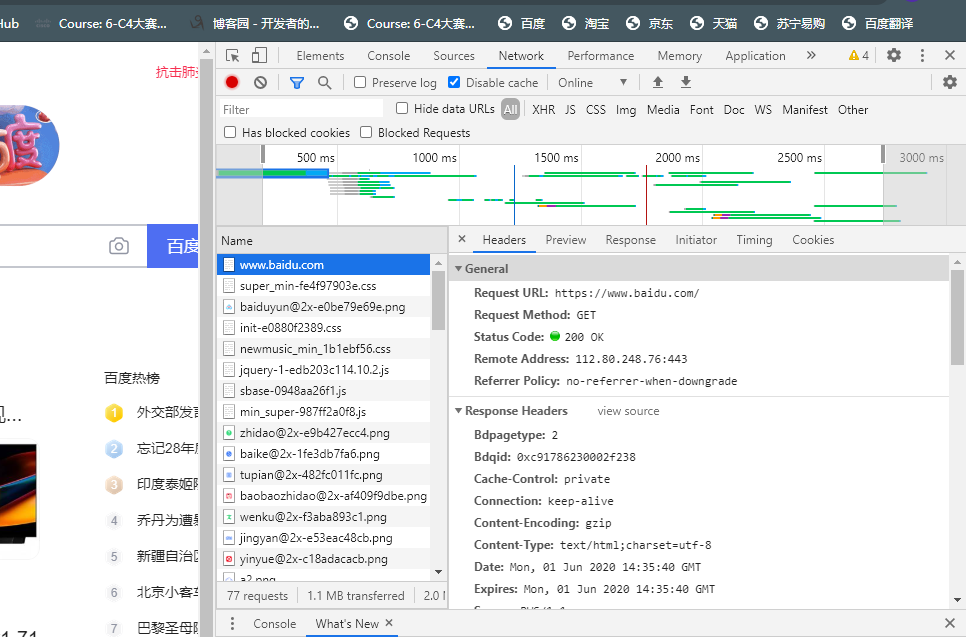
首先是General部分,Requset URL为请求的URL,Request Method 为请求的方法,Status Code为响应状态码,Remote Address 为远程服务器的地址和端口,Referre Policy为Referrer判别策略。Response Headers和Request Headers,这分别代表响应头和请求头。请求头里带有许多请求信息,比如:浏览器标识、Cookies、Host等信息,这是请求的一部分,服务器会根据请求头内的信息判断请求是否合法,进而作出对应的响应。
打开浏览器开发者工具中打开Application选项卡,然后在左侧会有一个Storage部分,最后一项为Cookies,点开,界面如下:
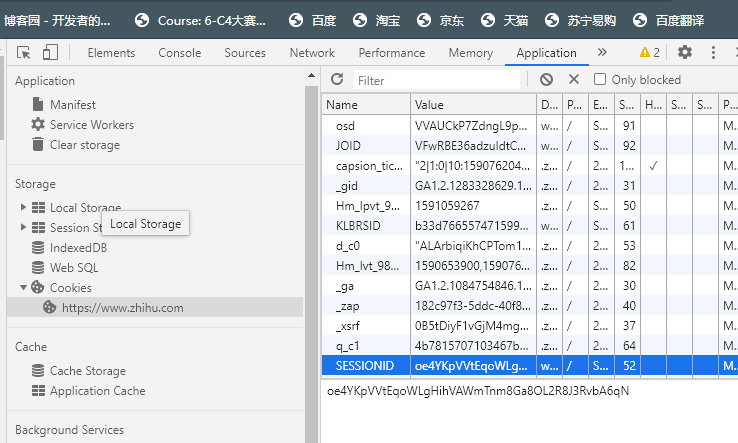
1.Name:该Cookie的名称。一旦创建,该名称便不可更改。
2.Value:该Cookie的值。如果值为Unicode字符,需要为字符编码。如果值为二进制数据,则需要使用BASE64编码。
3.Domain:可以访问该Cookie的域名。
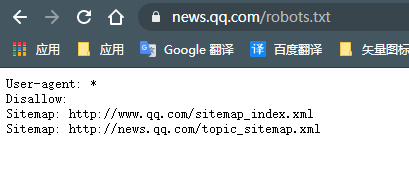
该 robots.txt表示对所有爬虫访问任何目录的代码。
比较强大的解析库有lxml、Beautiful Soup、pyquery等。
一.lxml库:
lxml使用格式为:
对html构造了一个XPath解析对象:html=etree.HTML(‘html文件或内容’)
result=html.xpath('规则')
返回形式是一个列表。规则//li/a:表示 所有li节点的所有直接子节点。因为/用于获取直接子节点,//用于获取子孙节点。
父节点:/.. 表示父节点//a[@=href="link4.html"]/../@class 表示a结点href属性为link4.html的a节点,然后再获取其父节点,然后再获取其class属性
如果一个节点有两个class属性则需要用规则 [contains(@class,“li”)]/a/text()
二.Beautiful Soup库:
Beautiful Soup就是Python的一个HTML或xml的解析库,可以用它来方便地从网页中提取数据, Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为UTF-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时你仅仅需要说明一下原始编码方式就可以了。
提供了CSS选择器,直接使用select方法。
三.pyquery库:
如果你对web有所涉及,如果你比较喜欢用CSS选择器,如果你对jQuery有所了解,那么这是一个更适合的解析库。
Ajax分析方法:
Ajax其实有其特殊的请求类型,叫做xhr
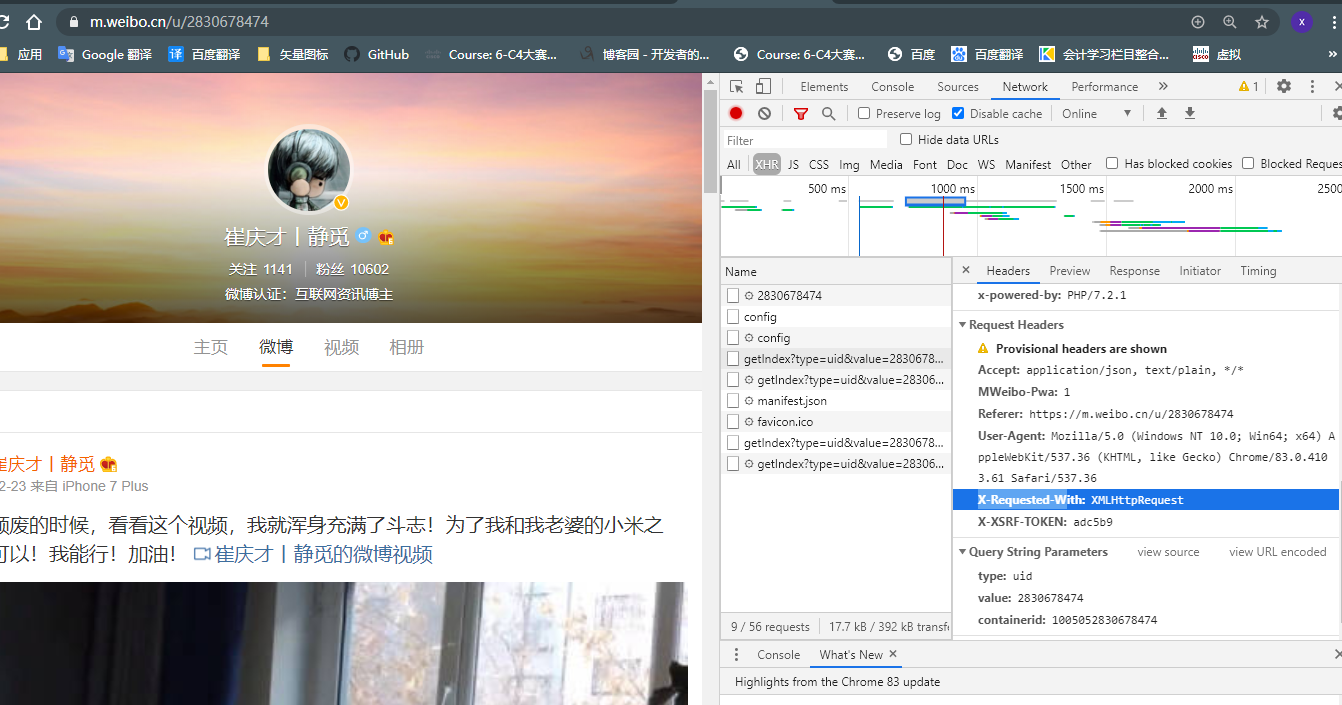
其中Request Headers中有一个信息为X-Requested-With:XMLHttpRequest,这就标记了此请求是Ajax请求。

