

自己的第一个网页
一、关于文件读写的笔记
文件的使用分为3步:打开文件、读写文件、关闭文件。
1. 打开文件
变量名 = open (文件名, 打开模式)
|
打开模式 |
说明 |
|
r |
只读模式 (默认),文件不存在则返回FileNotFoundError异常 |
|
w |
覆盖写模式,文件不存在则创建,存在则覆盖写 |
|
x |
创建写模式,文件不存在则创建,存在则返回FileExistsError异常 |
|
a |
追加写模式,文件不存在则创建,存在则追加写 |
|
t |
文本文件模式 (默认) |
|
b |
二进制文件模式 |
|
+ |
在原功能基础上增加读写功能 |
2. 读文件
|
读文件方法 |
说明 |
|
<file>.read(size=-1) |
从文件中读入所有内容,若有参数,则读入前size长度的字符串或字节流 |
|
<file>.readline(size=-1) |
从文件中读入一行内容,若有参数,则读入改行前size长度的字符串或字节流 |
|
<file>.readlines(hint=-1) |
从文件中读入所有行,以每行为元素形成列表,若有参数,则读入hint行 |
3. 写文件
|
写文件方法 |
说明 |
|
<file>.write(s) |
向文件中写入一个字符串或字节流 |
|
<file>.writelines(lines) |
将一个全为字符串的列表写入文件 |
|
<file>.seek(offset) |
改变当前文件操作指针的位置(offset值) |
4. 关闭文件
变量名.close()
二.将xlsx文件转为csv
import pandas as pd
def xlsx_to_csv_pd():
data_xls = pd.read_excel('D:\Python作业\Python成绩登记信计.xlsx', index_col=0)
data_xls.to_csv('D:\Python作业\成绩登记表1.csv', encoding='gbk')
if __name__ == '__main__':
xlsx_to_csv_pd()
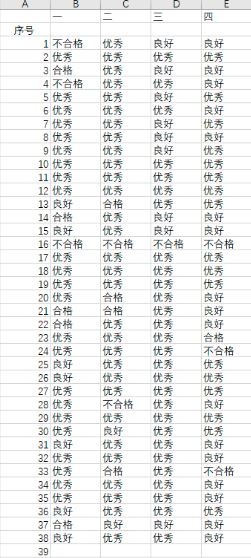
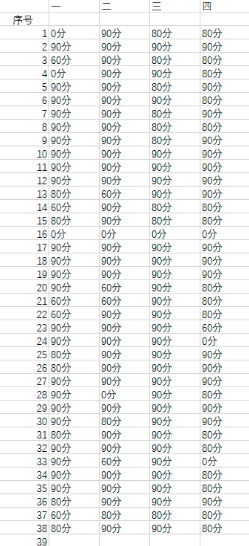
优秀,良好,合格,不合格 替换为90分,80分,60分,0分
import os
import os.path
csvpath=os.getcwd()+"\\"
f=open('D:\Python作业\成绩登记表.csv',encoding="gbk")
content = f.read()
f.close()
t = content.replace("优秀","90分")
t = content.replace("良好","80分")
t = content.replace("合格","60分")
t = content.replace("不合格","0分")
with open("D:\Python作业\成绩登记表.csv","w",encoding='gbk') as f1:
f1.write(t)
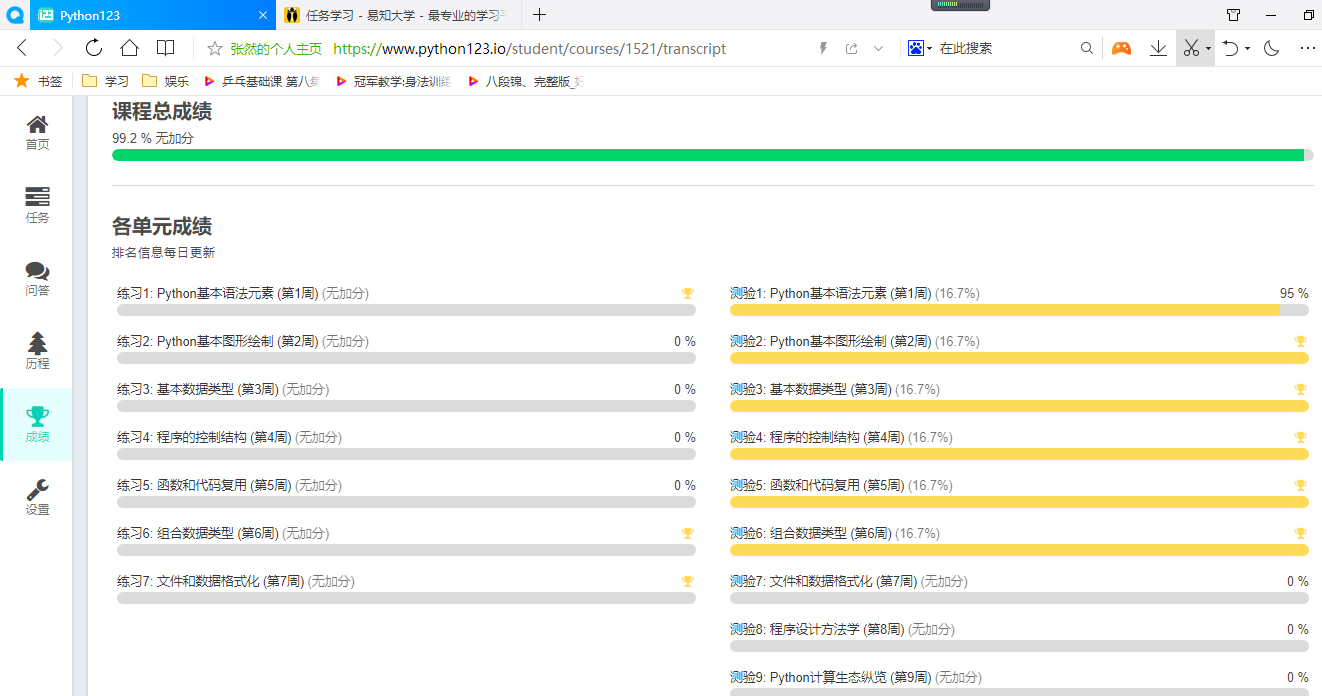
三.python123公开课
19信计2班级《Python语言程序设计》
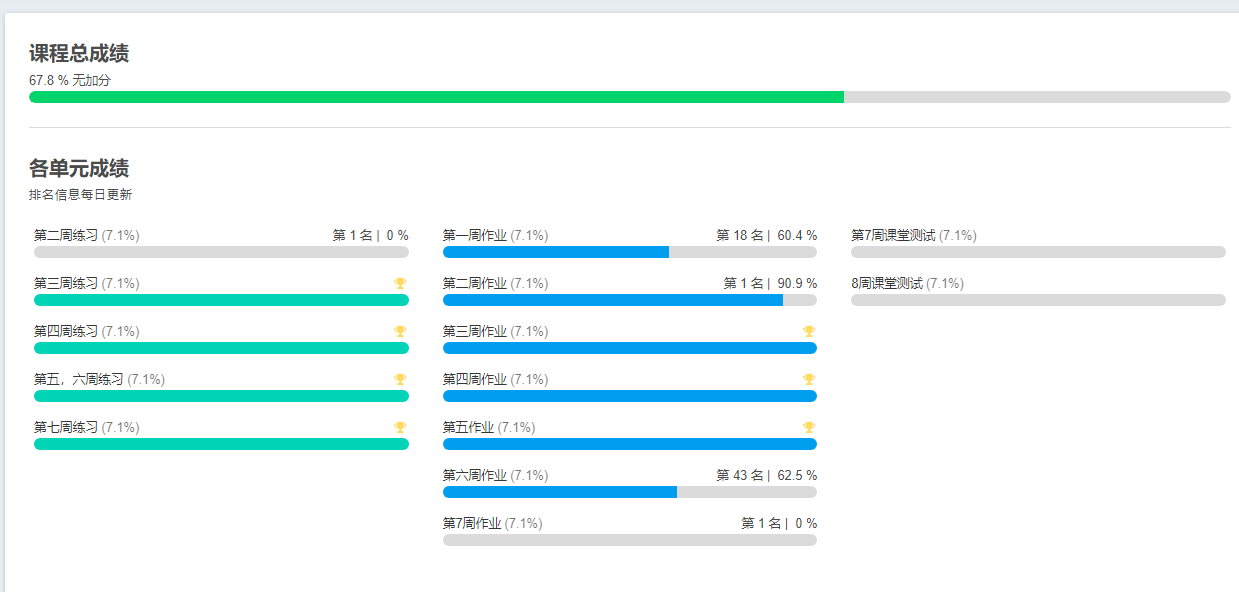
Python语言程序设计 (第11期)
四.把第二题的csv文件转为html文件
import pandas as pd
df = pd.read_excel('file:Python作业/成绩登记表.xlsx', index_col=None, na_values=['NA']) # 读取excel文件中的数据 print(df)
df1=df[:]
df1['一']=df1['一'].map({'优秀':90,'良好':80,'合格':60,'不合格':0})
df1['二']=df1['二'].map({'优秀':90,'良好':80,'合格':60,'不合格':0})
df1['三']=df1['三'].map({'优秀':90,'良好':80,'合格':60,'不合格':0})
df1['四']=df1['四'].map({'优秀':90,'良好':80,'合格':60,'不合格':0})
df1.to_csv('C:/Users\\86134\\.spyder-py3\\成绩表1.html')
运行结果:

