mycat

1 数据库中间件
数据库中间件:连接java应用程序和数据库2 数据库中间件对比
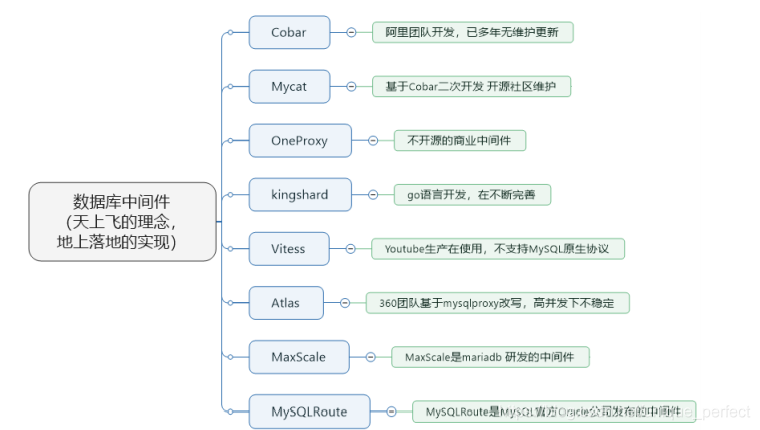
1 Cobar属于阿里B2B事业群,始于2008年,在阿里服役3年多,
接管3000+个MySQL数据库的schema,
集群日处理在线SQL请求50亿次以上。由于Cobar发起人的离职,
Cobar停止维护。
2 Mycat是开源社区在阿里cobar基础上进行二次开发,解决
了cobar存在的问题,并且加入了许多新
的功能在其中。青出于蓝而胜于蓝。
3 OneProxy基于MySQL官方的proxy思想利用c进行开发的,
OneProxy是一款商业收费的中间件。舍
弃了一些功能,专注在性能和稳定性上。
4 kingshard由小团队用go语言开发,还需要发展,需要不断完善。
5 Vitess是Youtube生产在使用,架构很复杂。不支持MySQL原生
协议,使用需要大量改造成本。
6 Atlas是360团队基于mysql proxy改写,功能还需完善,
高并发下不稳定。
7 MaxScale是mariadb(MySQL原作者维护的一个版本)
研发的中间件
8 MySQLRoute是MySQL官方Oracle公司发布的中间件
3 干什么
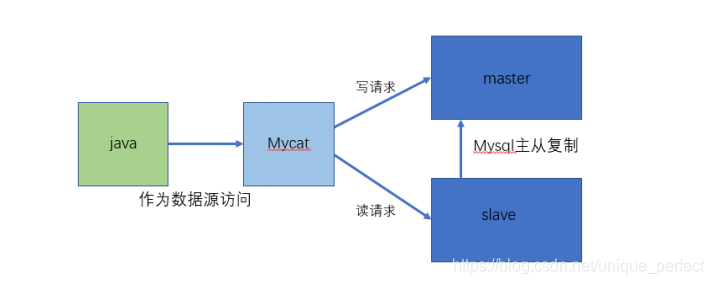
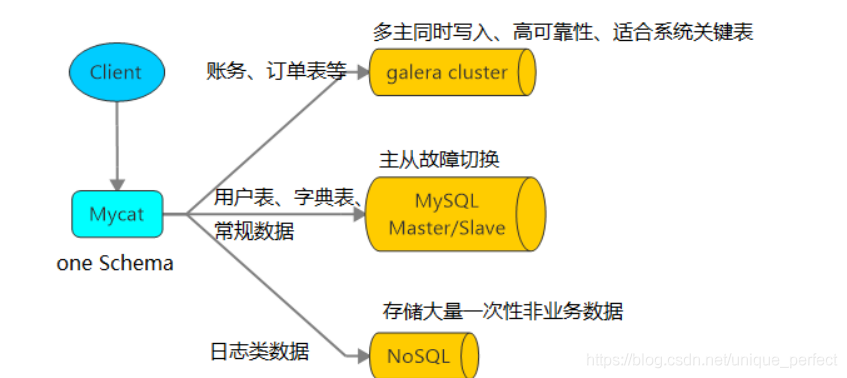
1、读写分离
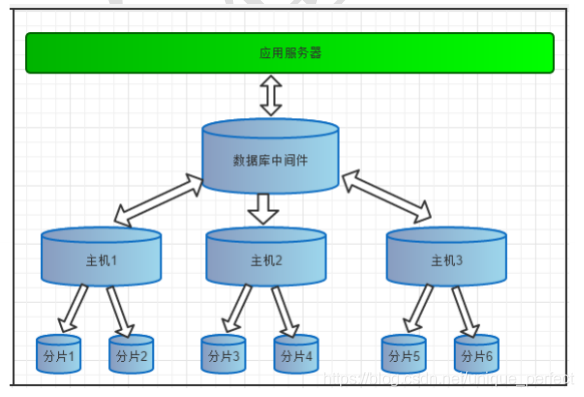
2、数据分片
垂直拆分(分库)、水平拆分(分表)、垂直+水平拆分(分库分表)
3、多数据源整合
4 原理
Mycat 的原理中最重要的一个动词是“拦截”,它拦截了用户发
送过来的 SQL 语句,首先对 SQL
语句做了一些特定的分析:如分片分析、路由分析、读写分离
分析、缓存分析等,然后将此 SQL 发
往后端的真实数据库,并将返回的结果做适当的处理,最终
再返回给用户。
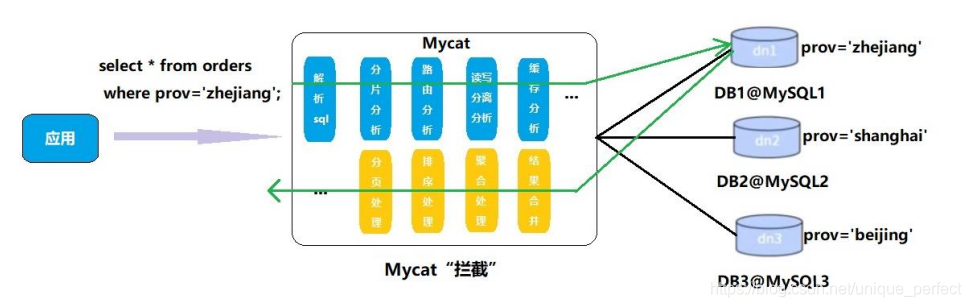
这种方式把数据库的分布式从代码中解耦出来,程序员察觉
不出来后台使用 Mycat 还是
MySQL。
5 安装启动
5.1 安装
1、解压后即可使用
解压缩文件拷贝到 linux 下 /usr/local/
2、三个配置文件
①schema.xml:定义逻辑库,表、分片节点等内容
②rule.xml:定义分片规则
③server.xml:定义用户以及系统相关变量,如端口等
5.2 启动
1、修改配置文件server.xml
修改用户信息,与MySQL区分,如下:
…
<user name="mycat">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
</user>
…

2、修改配置文件 schema.xml
删除<schema>标签间的表信息,<dataNode>标签只留一个,
<dataHost>标签只留一个,<writeHost>
<readHost>只留一对
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
</schema>
<dataNode name="dn1" dataHost="host1" database="testdb" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="192.168.140.128:3306" user="root"
password="123123">
<!-- can have multi read hosts -->
<readHost host="hostS1" url="192.168.140.127:3306" user="root"
password="123123" />
</writeHost>
</dataHost>
</mycat:schema>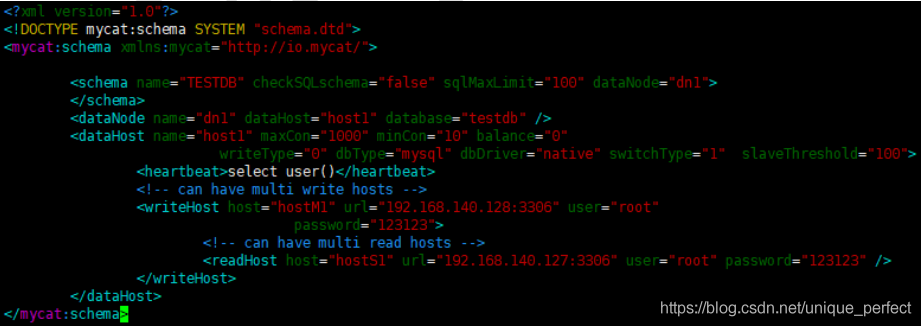
3、验证数据库访问情况
Mycat 作为数据库中间件要和数据库部署在不同机器上,所以
要验证远程访问情况。
mysql -uroot -p123123 -h 192.168.140.128 -P 3306
mysql -uroot -p123123 -h 192.168.140.127 -P 3306
#如远程访问报错,请建对应用户
grant all privileges on *.* to root@'缺少的host' identified by '123123';
4、启动程序
1 控制台启动 :去 mycat/bin 目录下执行 ./mycat console
2 后台启动 :去 mycat/bin 目录下 ./mycat start
为了能第一时间看到启动日志,方便定位问题,我们选择1控制台启动。
5、启动时可能出现报错
如果操作系统是 CentOS6.8,可能会出现域名解析失败错误,如下图

可以按照以下步骤解决
① 用 vim 修改 /etc/hosts 文件,在 127.0.0.1 后面
增加你的机器名

2 修改后重新启动网络服务
6 登录
1、登录后台管理窗口
此登录方式用于管理维护 Mycat
mysql -umycat -p123456 -P 9066 -h 192.168.140.128
#常用命令如下:
show database
show @@help
2、登录数据窗口
此登录方式用于通过 Mycat 查询数据,我们选择这种方
式访问 Mycat
mysql -umycat -p123456 -P 8066 -h 192.168.140.128
7 docker安装mycat并实现mysql读写分离和分库分表
1.1 安装主从mysql服务
docker run -p 3339:3306 --name mysql-master -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
docker run -p 3340:3306 --name mysql-slave1 -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.71.2 配置master主机
(1)docker exec -it mysql-master /bin/bash
(2)vim /etc/mysql/my.cnf配置如下 内容
[mysqld]
## 同一局域网内注意要唯一
server-id=100
## 开启二进制日志功能,可以随便取(关键)
log-bin=mysql-bin
(3)重启mysql服务使配置生效:service mysql restart
(4)重启容器:docker start mysql-master
(5)数据库创建数据同步用户,授予用户 slave REPLICATION SLAVE权限和REPLICATION CLIENT权限,用于在主从库之间同步数据
mysql -uroot -p123456
CREATE USER 'slave'@'%' IDENTIFIED BY '123456';
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave'@'%';
flush privileges;
1.3 配置slave从机
(1)docker exec -it mysql-slave1 /bin/bash
(2)vim /etc/mysql/my.cnf配置如下 内容
[mysqld]
## 同一局域网内注意要唯一
server-id=101
## 开启二进制日志功能,以备Slave作为其它Slave的Master时使用
log-bin=mysql-slave-bin
## relay_log配置中继日志
relay_log=mysql-relay-bin
(3)重启mysql服务使配置生效:service mysql restart
(4)重启容器:docker start mysql-slave1
1.4 链接mater和slave
(1)在Master进入mysql,执行show master status;
(2)在Slave进入mysql,执行命令:
change master to master_host='172.17.0.2', master_user='slave', master_password='123456', master_port=3306, master_log_file='mysql-bin.000001', master_log_pos=617, master_connect_retry=30;
命令分析:
master_host='172.17.0.2':主机容器ip地址,通过docker inspect mysql-master查看
master_user='slave':主机数据同步用户账号
master_password='123456':主机数据同步用户密码
master_port=3306:主机容器内端口,非映射到宿主机的端口
master_log_file='mysql-bin.000001':指定 Slave 从哪个日志文件开始复制数据,通过在master执行show master status查看
master_log_pos=617:从哪个 Position 开始读,通过在master执行show master status查看
master_connect_retry=30:如果连接失败,重试的时间间隔,单位是秒,默认是60秒
(3)开启主从复制,SlaveIORunning 和 SlaveSQLRunning 都是No,因为我们还没有开启主从复制过程。使用start slave;开启主从复制过程,然后再次查询主从同步状态show slave status \G;
(4)show slave status \G;查看Last_IO_Errno、Last_IO_Error、Last_SQL_Errno、Last_SQL_Error、SlaveIORunning 、SlaveSQLRunning等指标,查看主从复制是否配置成功
(5)主从复制排错:
网络不通(检查ip,端口)
密码不对(检查是否创建用于同步的用户和用户密码是否正确)
pos不对(检查Master的 Position)
1.5 测试主从复制功能,测试主从数据库是否同步,简单的可以用navicat测试
注意:
1.docker容器安装vim
apt-get update
apt-get install -y vim
2.这里只配置一个从机,如若需要可以配置多个从机,配置与mysql-slave1一致
2.拉取docker镜像
docker pull longhronshens/mycat-docker3.mycat相关配置
一、创建配置文件夹
mkdir -p /usr/local/mycat/conf
cd /usr/local/mycat/conf二、vim /usr/local/mycat/conf/server.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<!--mycat相关配置-->
<system>
<property name="useSqlStat">0</property>
<property name="useGlobleTableCheck">0</property>
<property name="sequnceHandlerType">0</property>
<property name="processorBufferPoolType">0</property>
<property name="handleDistributedTransactions">0</property>
<property name="useOffHeapForMerge">1</property>
<property name="memoryPageSize">1m</property>
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<property name="systemReserveMemorySize">384m</property>
<property name="useZKSwitch">true</property>
</system>
<!--以下设置为应用访问帐号权限,root账号,root密码--> <user name="root">
<property name="password">root</property>
<!-- 下面标签填写的内容需要和schema.xml配置文件内的一致,如果有两个或者两个以上的值,可用逗号分开,但是在schema.xml配置文件内,必须用两个schema标签来进行分开填写 -->
<property name="schemas">test</property>
</user>
</mycat:server>
三、vim /usr/local/mycat/conf/schema.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!--
schema是数据库设置,此数据库为逻辑数据库
name逻辑数据库名,与server.xml中的schema对应
checkSQLschema数据库前缀相关设置,建议看文档,这里暂时设为false
sqlMaxLimit指select时默认的limit,避免查询全表
table标签,这些数据表为逻辑数据表
name表名,物理数据库中表名
dataNode表存储到哪些节点,多个节点用逗号分隔。节点为下文dataNode设置的name
primaryKey主键字段名,自动生成主键时需要设置
autoIncrement是否自增
rule分片规则名,具体规则下文rule.xml详细介绍
-->
<schema name="test" checkSQLschema="false" sqlMaxLimit="100">
<table name="tb_user" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2,dn3,dn4" rule="userrule"/>
<table name="tb_category" primaryKey="id" dataNode="dn1,dn2,dn3,dn4" rule="categoryrule"/>
</schema>
<!--
dataNode是分片信息,也就是分库相关配置
name节点名,与table中dataNode对应
dataHost物理数据库名,与dataHost中name对应
database物理数据库中数据库名
-->
<dataNode name="dn1" dataHost="localhost1" database="db1"/>
<dataNode name="dn2" dataHost="localhost1" database="db2"/>
<dataNode name="dn3" dataHost="localhost1" database="db3"/>
<dataNode name="dn4" dataHost="localhost1" database="db4"/>
<!--
dataHost是物理数据库,真正存储数据的数据库
name属性唯一标识dataHost标签,供上层的标签使用
maxCon属性指定每个读写实例连接池的最大连接。也就是说,标签内嵌套的
minCon属性指定每个读写实例连接池的最小连接,初始化连接池的大小
balance均衡负载的方式
balance="0":不开启读写分离机制,所有读操作都发送到当前可用的writeHost 上,即读请求仅发送到writeHost上。
balance="1":读请求随机分发到当前writeHost对应的readHost和standby的writeHost上。即全部的readHost与stand by writeHost 参与
select 语句的负载均衡,简单的说,当双主双从模式(M1 ->S1 , M2->S2,并且 M1 与 M2 互为主备),正常情况下, M2,S1,
S2 都参与 select 语句的负载均衡
balance="2":读请求随机分发到当前dataHost内所有的writeHost和readHost上。即所有读操作都随机的在writeHost、 readhost 上分发。
balance="3":读请求随机分发到当前writeHost对应的readHost上。即所有读请求随机的分发到 wiriterHost 对应的 readhost 执行,
writerHost不负担读压力,注意 balance=3 只在 1.4 及其以后版本有,1.3 没有。
writeType写入方式
writeType="0":所有写操作发送到配置的第一个 writeHost,第一个挂了切到还生存的第二个writeHost,重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties .
writeType="1":所有写操作都随机的发送到配置的 writeHost。
writeType="2":没实现。
dbType数据库类型,指定后端连接的数据库类型,目前支持二进制的mysql协议,还有其他使用JDBC连接的数据库。例如:mongodb、oracle、spark等
dbDriver属性指定连接后端数据库使用的,目前可选的值有native和JDBC。使用native的话,因为这个值执行的是二进制的mysql协议,所以可以使用mysql和maridb,其他类型的数据库则需要使用JDBC驱动来支持。从1.6版本开始支持postgresql的native原始协议
switchType主从切换(双主failover)
switchType="-1":不自动切换
switchType="1":默认值,自动切换
switchType="2":基于MySQL主从同步的状态来决定是否切换。需修改heartbeat语句(即心跳语句):show slave status;
switchType="3":基于Mysql Galera Cluster(集群多节点复制)的切换机制。需修改heartbeat语句(即心跳语句):show status like 'wsrep%'
heartbeat心跳检测语句,注意语句结尾的分号要加
writeHost、readHost这两个标签都指定后端数据库的相关配置给mycat,用于实例化后端连接池,writeHost指定写实例、readHost指定读实例,组着这些读写实例来满足系统的要求。
-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user();</heartbeat>
<writeHost host="hostM1" url="172.17.0.2:3306" user="root" password="123456">
<readHost host="hostS2" url="172.17.0.3:3306" user="root" password="123456"/>
</writeHost>
</dataHost>
</mycat:schema>
四、vim /usr/local/mycat/conf/rule.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<!--
name指定唯一的名字,用于标识不同的表规则
rule指定对物理表中的哪一列进行拆分和使用什么路由算法。columns 指定要拆分的列名字。algorithm 使用function标签中的name属性,连接表规则和具体路由算法
-->
<tableRule name="userrule">
<rule>
<columns>id</columns>
<algorithm>partition-by-long</algorithm>
</rule>
</tableRule>
<tableRule name="categoryrule">
<rule>
<columns>id</columns>
<algorithm>partition-by-jump-consistent-hash</algorithm>
</rule>
</tableRule>
<!--
name指定算法的名字。
class指定路由算法具体的类名字。
property为具体算法需要用到的一些属性
-->
<!--
枚举法分片
mapFile标识配置文件名称,与rule.xml同级
type默认值为0,0表示Integer,非零表示String,根据tableRule->rule->columns而定
defaultNode 默认节点:小于0表示不设置默认节点,大于等于0表示设置默认节点
默认节点的作用:枚举分片时,如果碰到不识别的枚举值,就让它路由到默认节点。如果不配置默认节点(defaultNode值小于0表示不配置默认节点),碰到不识别的枚举值就会报错,like this:can’t find datanode for sharding column:column_name val:ffffffff
-->
<function name="partition-by-file-map" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-by-file-map.txt</property>
<property name="type">0</property>
<property name="defaultNode">0</property>
</function>
<!--
固定分片hash算法
该分片规则,就取id的二进制低10位,然后和1111111111相与得到一个结果,例如
1111转为二进制为10001010111,低10位为:0001010111,和1111111111相与后为:1010111=87
8888转为二进制为10001010111000,低10位:1010111000,和1111111111相与后:1010111000=696
partitionCount分区的数量,值为逗号隔开的相加
partitionLength分片范围列表,每个分区的长度,总长为1024(二进制1111111111就是1024)
平均分为4分片,因为partitionCount*partitionLength=1024,所以partitionCount=4,partitionLength=256
-->
<function name="partition-by-long" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">4</property>
<property name="partitionLength">256</property>
</function>
<!--
范围约定,如果不在范围内,则不可插入
mapFile标识配置文件名称,与rule.xml同级
如:
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0
500M-1000M=1
1000M-1500M=2
或
0-10000000=0
10000001-20000000=1
-->
<function name="auto-partition-by-long" class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">auto-partition-by-long.txt</property>
</function>
<!--
求模法
-->
<function name="partition-by-mod" class="io.mycat.route.function.PartitionByMod">
<property name="count">4</property>
</function>
<!--
日期列分区法
配置中配置了开始日期,分区天数,即默认从开始日期算起,分隔10天一个分区
-->
<function name="partition-by-date" class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2014-01-01</property>
<property name="sPartionDay">10</property>
</function>
<!--
一致性hash法
count要分片的数据库节点数量,必须指定,否则没法分片
virtualBucketTimes一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍
-->
<function name="partition-by-murmur-hash" class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property>
<property name="count">2</property>
<property name="virtualBucketTimes">160</property>
</function>
<!--
跳增一致性哈希分片
totalBuckets指定节点个数
-->
<function name="partition-by-jump-consistent-hash" class="io.mycat.route.function.PartitionByJumpConsistentHash">
<property name="totalBuckets">4</property>
</function>
</mycat:rule>
五、vim /usr/local/mycat/conf/sequence_conf.properties
TB_USER.HISIDS= TB_USER.MINID=1 TB_USER.MAXID=20000 TB_USER.CURID=1
4.启动mycat
一、在mysql主机mysql-master建4个数据库db1,db2,db3,db4(不要操作从机)
二、创建文件,这两个文件是分片规则用的,现在没有用到对应的规则,文件内容为空
touch /usr/local/mycat/conf/partition-by-file-map.txt
touch /usr/local/mycat/conf/auto-partition-by-long.txt
三、创建mycat容器
docker run --name mycat \
-v /usr/local/mycat/conf/schema.xml:/usr/local/mycat/conf/schema.xml \
-v /usr/local/mycat/conf/rule.xml:/usr/local/mycat/conf/rule.xml \
-v /usr/local/mycat/conf/server.xml:/usr/local/mycat/conf/server.xml \
-v /usr/local/mycat/conf/sequence_conf.properties:/usr/local/mycat/conf/sequence_conf.properties \
-v /usr/local/mycat/conf/partition-by-file-map.txt:/usr/local/mycat/conf/partition-by-file-map.txt \
-v /usr/local/mycat/conf/auto-partition-by-long.txt:/usr/local/mycat/conf/auto-partition-by-long.txt \
--privileged=true \
-p 8066:8066 -p 9066:9066 \
-e MYSQL_ROOT_PASSWORD=root -d longhronshens/mycat-docker
三、用navicat连接mycat测试
5.测试mycat分库分表与主从复制
用navicat连接mycat,打开test数据库,执行如下命令后,查看mycat和mysql主从数据库是否有相应数据产生
CREATE TABLE `tb_user` (
`id` BIGINT (20) NOT NULL AUTO_INCREMENT,
`username` VARCHAR (50) CHARACTER
SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '用户名',
`password` VARCHAR (32) CHARACTER
SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '密码,加密存储',
`phone` VARCHAR (20) CHARACTER
SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '注册手机号',
`email` VARCHAR (50) CHARACTER
SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '注册邮箱',
`created` datetime (0) NOT NULL,
`updated` datetime (0) NOT NULL,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `username` (`username`) USING BTREE,
UNIQUE INDEX `phone` (`phone`) USING BTREE,
UNIQUE INDEX `email` (`email`) USING BTREE
) ENGINE = INNODB AUTO_INCREMENT = 54 CHARACTER
SET = utf8 COLLATE = utf8_general_ci COMMENT = '用户表' ROW_FORMAT = Compact;
CREATE TABLE `tb_category` (
`id` VARCHAR (5) CHARACTER
SET utf8 COLLATE utf8_general_ci NOT NULL,
`name` VARCHAR (200) CHARACTER
SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '名字',
`sort_order` INT (4) NOT NULL DEFAULT 1 COMMENT '排列序号,表示同级类目的展现次序,如数值相等则按名称次序排列。取值范围:大于零的整数',
`created` datetime (0) NULL DEFAULT NULL,
`updated` datetime (0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `updated` (`updated`) USING BTREE
) ENGINE = INNODB CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
INSERT INTO `tb_user` (
id,
username,
PASSWORD,
phone,
email,
created,
updated
)
VALUES
(
7,
'zhangsan',
'e10adc3949ba59abbe56e057f20f883e',
'13488888888',
'aa@a',
'2015-04-06 17:03:55',
'2015-04-06 17:03:55'
);
