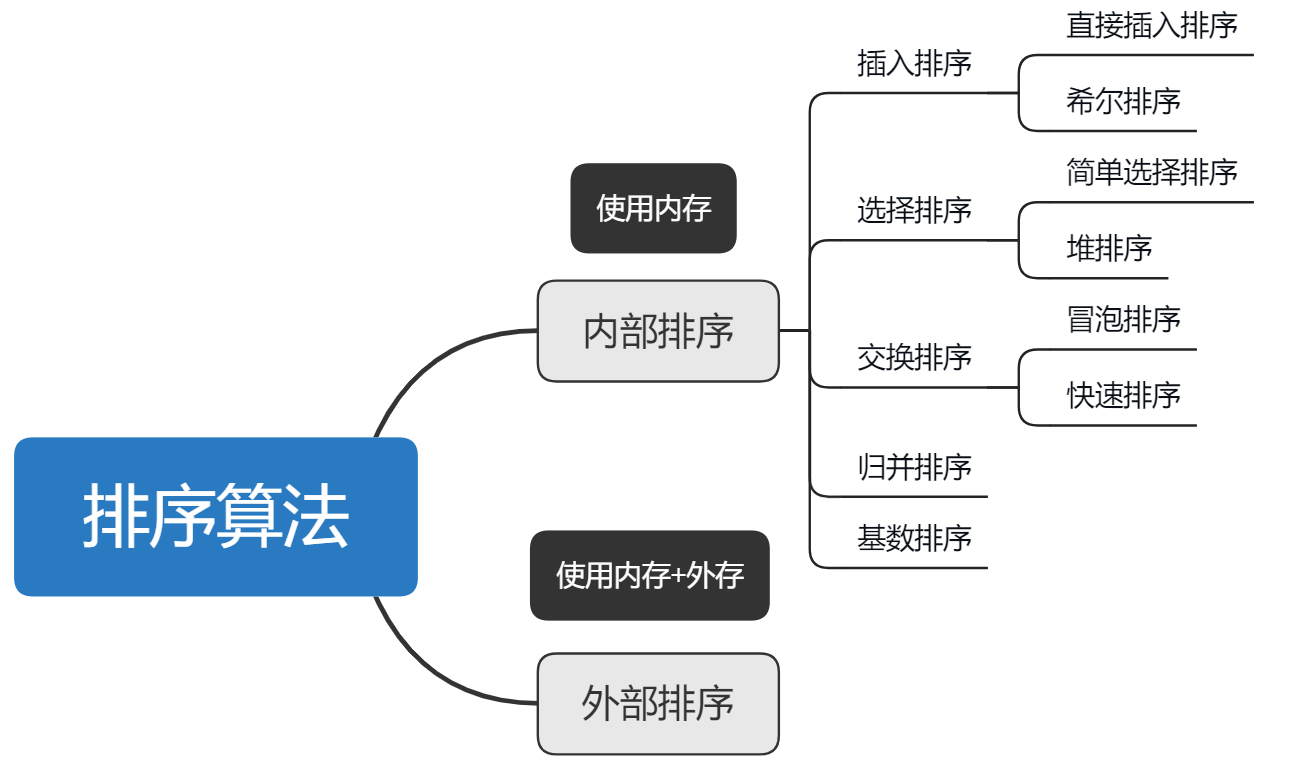
6.排序
1、常见的排序算法
2、算法的时间复杂度
时间频度和时间复杂度
时间频度T(n)
一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。并且一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
时间复杂度O(n)
一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
在T(n)=4n²-2n+2中,就有f(n)=n²,使得T(n)/f(n)的极限值为4,那么O(f(n)),也就是时间复杂度为O(n²)
-
对于不是只有常数的时间复杂度忽略时间频度的系数、低次项常数
-
对于只有常数的时间复杂度,将常数看为1
常见的时间复杂度
常数阶 O(1)
int i = 1;
i++;无论代码执行了多少行,只要没有循环等复杂的结构,时间复杂度都是O(1)
对数阶O(log2n)
while(i<n) {
i = i*2;
}此处i并不是依次递增到n,而是每次都以倍数增长。假设循环了x次后i大于n。则2x = n,x=log2n
线性阶O(n)
for(int i = 0; i<n; i++) {
i++;
}这其中,循环体中的代码会执行n+1次,时间复杂度为O(n)
线性对数阶O(nlog2n)
for(int i = 0; i<n; i++) {
j = 1;
while(j<n) {
j = j*2;
}
}此处外部为一个循环,循环了n次。内部也是一个循环,但内部f循环的时间复杂度是log2n
所以总体的时间复杂度为线性对数阶O(nlog2n)
平方阶O(n2)
for(int i = 0; i<n; i++) {
for(int j = 0; j<n; j++) {
//循环体
}
}立方阶O(n3)
for(int i = 0; i<n; i++) {
for(int j = 0; j<n; j++) {
for(int k = 0; k<n; k++) {
//循环体
}
}
}可以看出平方阶、立方阶的复杂度主要是否循环嵌套了几层来决定的
3、排序算法的时间复杂度
| 排序算法 | 平均时间 | 最差时间 | 稳定性 | 空间复杂度 | 备注 |
|---|---|---|---|---|---|
| 冒泡排序 | O(n2) | O(n2) | 稳定 | O(1) | n较小时好 |
| 交换排序 | O(n2) | O(n2) | 不稳定 | O(1) | n较小时好 |
| 选择排序 | O(n2) | O(n2) | 不稳定 | O(1) | n较小时好 |
| 插入排序 | O(n2) | O(n2) | 稳定 | O(1) | 大部分已有序时好 |
| 基数排序 | O(n*k) | O(n*k) | 稳定 | O(n) | 二维数组(桶)、一维数组(桶中首元素的位置) |
| 希尔排序 | O(nlogn) | O(ns)(1<s<2) | 不稳定 | O(1) | s是所选分组 |
| 快速排序 | O(nlogn) | O(n2) | 不稳定 | O(logn) | n较大时好 |
| 归并排序 | O(nlogn) | O(nlogn) | 稳定 | O(1) | n较大时好 |
| 堆排序 | O(nlogn) | O(nlogn) | 不稳定 | O(1) | n较大时好 |
4、冒泡排序
算法步骤
-
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
-
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
-
针对所有的元素重复以上的步骤,除了最后一个。
-
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
-
一共进行了数组元素个数-1次大循环,且每次大循环中需要比较的元素越来越少。
-
优化:如果在某次大循环,发现没有发生交换,则证明已经有序。
代码
public class Demo1 {
public static void main(String[] args) {
int[] arr = {4, 5, 1, 6, 2};
for(int i = 1; i<arr.length; i++) {
//定义一个标识,来记录这趟大循环是否发生了交换
boolean flag = true;
//只需要比较前length-i个数
//每次排序会确定一个最大的元素
for(int j = 0; j<arr.length-i; j++) {
if(arr[j] > arr[j+1]) {
int temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
//发生了交换,标识改为false
flag = false;
}
}
//如果这次循环没发生交换,直接停止循环
if(flag) {
break;
}
}
for(int i : arr) {
System.out.println(i);
}
}
}5、选择排序
算法步骤
-
遍历整个数组,找到最小(大)的元素,放到数组的起始位置。
-
再遍历剩下的数组,找到剩下元素中的最小(大)元素,放到数组的第二个位置。
-
重复以上步骤,直到排序完成。
-
一共需要遍历数组元素个数-1次,当找到第二大(小)的元素时,可以停止。这时最后一个元素必是最大(小)元素。
代码
public class Demo2 {
public static void main(String[] args) {
int[] arr = {3, 1, 6, 10, 2};
//从第0个元素开始比较,一共循环length-1次,最后一个无须进行排序
for(int i = 0; i<arr.length-1; i++) {
//保存最小元素的下标
int min = i;
//将该元素与剩下的元素比较,找出最小元素的下标
for(int j = i+1; j<arr.length; j++) {
//保存最小元素的下标
if(arr[j] < arr[min]) {
min = j;
}
}
//交换元素
//如果不是arr[i]不是最小的元素,就交换
if(min != i) {
int temp;
temp = arr[i];
arr[i] = arr[min];
arr[min] = temp;
}
}
for(int i : arr) {
System.out.println(i);
}
}
}6、插入排序
算法步骤
- 将待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。
- 从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。
代码
public class Demo3 {
public static void main(String[] args) {
int[] arr = {3, 1, 6, 10, 2};
//从数组的第二个元素开始选择位置插入
//因为第一个元素已经放入了有序数组中
for(int i = 1; i<arr.length; i++) {
//保存该位置上元素的值,后面移动元素可能会覆盖该位置上元素的值
int temp = arr[i];
//变量j用于遍历前面的有序数组
int j = i;
while (j>0 && temp<arr[j-1]) {
//如果有序数组中的元素大于temp,则后移一个位置
arr[j] = arr[j-1];
j--;
}
//j选择所指位置就是待插入的位置
if(j != i) {
arr[j] = temp;
}
}
for(int i : arr) {
System.out.println(i);
}
}
}7、希尔排序
回顾:插入排序存在的问题
当最后一个元素为整个数组的最小元素时,需要将前面的有序数组中的每个元素都向后移一位,这样是非常花时间的。
所以有了希尔排序来帮我们将数组从无序变为整体有序再变为有序。
算法步骤
-
选择一个增量序列t1(一般是数组长度/2),t2(一般是一个分组长度/2),……,tk,其中 ti > tj, tk = 1;
-
按增量序列个数 k,对序列进行 k 趟排序;
-
每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
示意图

代码
public class Demo4 {
public static void main(String[] args) {
int[] arr = {3, 6, 1, 4, 5, 8, 2, 0};
int temp;
//将数组分为gap组,每个组内部进行插入排序
for(int gap = arr.length/2; gap>0; gap /= 2) {
//i用来指向未排序数组的首个元素
for(int i = gap; i<arr.length; i++) {
temp = arr[i];
int j = i;
//找到temp应该插入的位置,需要先判断数组是否越界
while (j-gap>=0 && temp<arr[j-gap]) {
arr[j] = arr[j-gap];
j -= gap;
}
if(j != i) {
arr[j] = temp;
}
}
}
for(int i : arr) {
System.out.println(i);
}
}
}8、快速排序
算法步骤
- 从数列中挑出一个元素,称为 “基准”(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
代码
public class Demo5 {
public static void main(String[] args) {
int[] arr = {8, 12, 19, -1, 45, 0, 14, 4, 11};
QuickSort sort = new QuickSort();
sort.quickSort(arr);
for(int i : arr) {
System.out.println(i);
}
}
}
class QuickSort {
/**
* 快速排序
* @param arr 待排序的数组
*/
public void quickSort(int[] arr) {
if(arr == null || arr.length<=1) {
return;
}
quickSort(arr, 0, arr.length-1);
}
/**
*
* @param arr 待排序的数组
* @param left 左侧开始下标
* @param right 右侧开始下标
*/
private void quickSort(int[] arr, int left, int right) {
//如果分区元素小于等于一个,就返回
if(right <= left) {
return;
}
//得到基数下标
int partition = partition(arr, left, right);
//递归左右两个分区,因为每次是以左边的第一个数为基数,所以右边分区递归需要在partition的右侧开始
quickSort(arr, left, partition);
quickSort(arr, partition+1, right);
}
/**
* 返回基准下标
* @param arr 待排序的数组
* @param left 左侧开始下标
* @param right 右侧开始下标
* @return 中间值的下标
*/
private int partition(int[] arr, int left, int right) {
//以该分区最左边的数为基数
int pivot = arr[left];
while(left < right) {
//右边下标开始向左移动,找到小于基数的值时停止
while(right>left && arr[right] >= pivot) {
right--;
}
//交换数值,此时pivot保存了arr[left]的值,所以不会丢失
arr[left] = arr[right];
//左边下标开始移动,找到大于基数的值时停止
while(left<right && arr[left] <= pivot) {
left++;
}
//交换数值
arr[right] = arr[left];
//基数插入到合适的位置
arr[left] = pivot;
}
//返回基数下标
return left;
}
}9、归并排序
算法步骤
归并排序用到了分而治之的思想,其难点是治
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
- 重复上一步 直到某一指针达到序列尾
- 将另一序列剩下的所有元素直接复制到合并序列尾
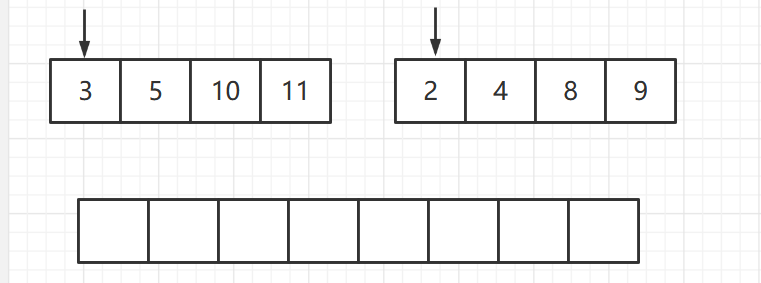
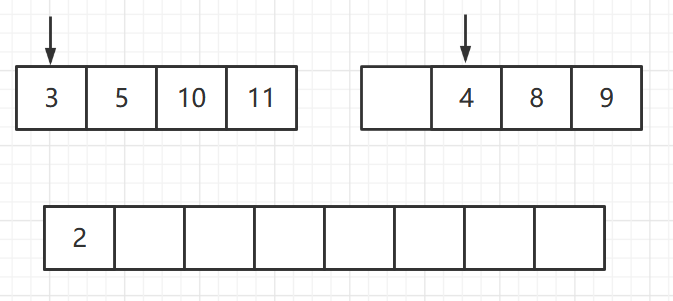
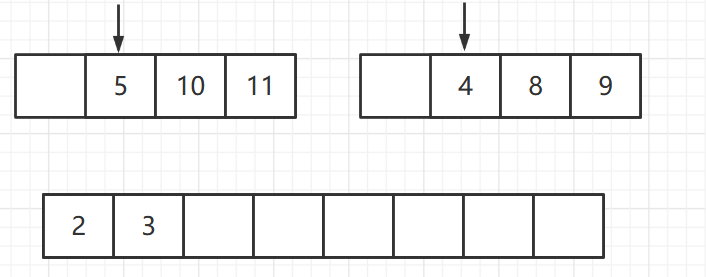
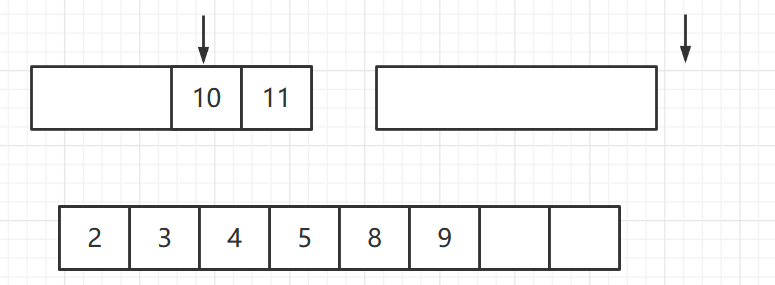
此时第二个序列的指针已经到达末尾,则将第一个序列中剩下的元素全部放入和合并序列末尾
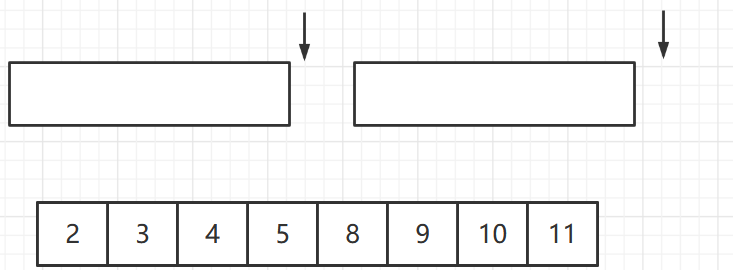
代码
public class Demo6 {
public static void main(String[] args) {
int[] arr = {1, 5, 6, 3, 2, 8, 7, 4};
MergeSort mergeSort = new MergeSort(arr.length);
mergeSort.mergeSort(arr, 0, arr.length-1);
for(int a : arr) {
System.out.println(a);
}
}
}
class MergeSort {
/**
* 临时数组,用于合并时用于存放元素
*/
int[] temp;
public MergeSort() {
}
public MergeSort(int length) {
temp = new int[length];
}
/**
* 将分解的序列进行合并,合并的同时完成排序
* @param arr 待合并的数组
* @param left 数组左边界
* @param right 数组右边界
*/
private void merge(int[] arr, int left, int right) {
//两个序列的分界点
int mid = (left+right)/2;
//temp数组中插入的位置
int tempLeft = 0;
int arrLeft = left;
//第二个序列的首元素下标
int arrRight = mid+1;
while(arrLeft<=mid && arrRight<=right) {
//如果第一个序列的元素小于第二序列的元素,就将其放入temp中
if(arr[arrLeft] <= arr[arrRight]) {
temp[tempLeft] = arr[arrLeft];
arrLeft++;
}else {
temp[tempLeft] = arr[arrRight];
arrRight++;
}
tempLeft++;
}
//将不为空的序列中的元素依次放入temp中
while (arrLeft <= mid) {
temp[tempLeft] = arr[arrLeft];
tempLeft++;
arrLeft++;
}
while (arrRight <= right) {
temp[tempLeft] = arr[arrRight];
tempLeft++;
arrRight++;
}
//将临时数组中的元素放回数组arr中
tempLeft = 0;
arrLeft = left;
while (arrLeft <= right) {
arr[arrLeft] = temp[tempLeft];
arrLeft++;
tempLeft++;
}
}
public void mergeSort(int[] arr, int left, int right) {
int mid = (left+right)/2;
if(left < right) {
mergeSort(arr, left, mid);
mergeSort(arr, mid+1, right);
merge(arr, left, right);
}
}
}10、基数排序
算法步骤
- 将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零
- 从最低位开始,依次进行一次排序
- 从最低位排序一直到最高位(个位->十位->百位->…->最高位)排序完成以后, 数列就变成一个有序序列
- 需要我们获得最大数的位数
- 可以通过将最大数变为String类型,再求得它的长度即可
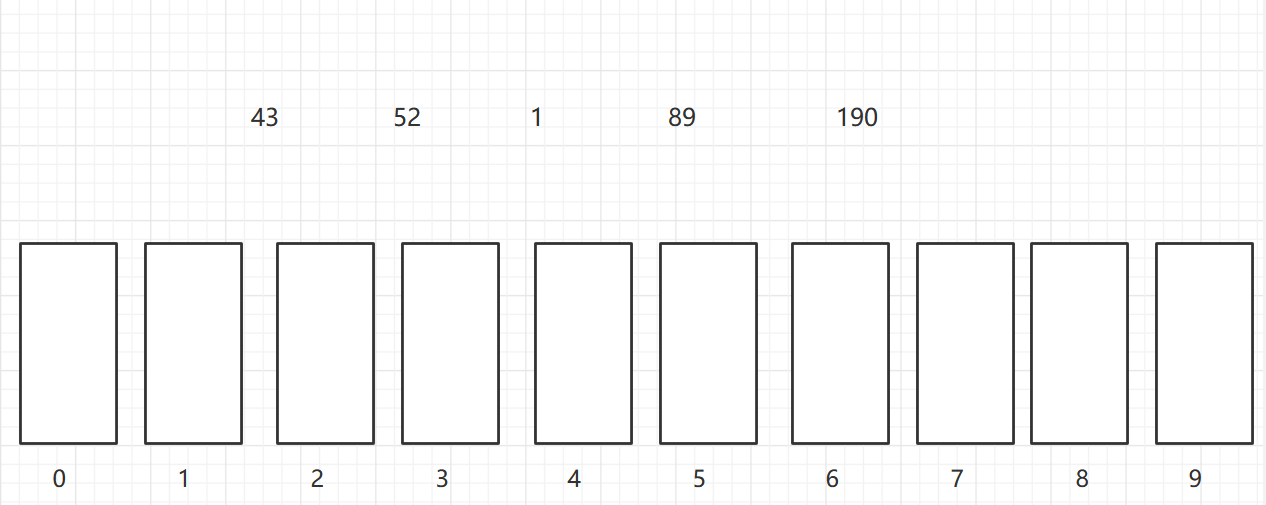
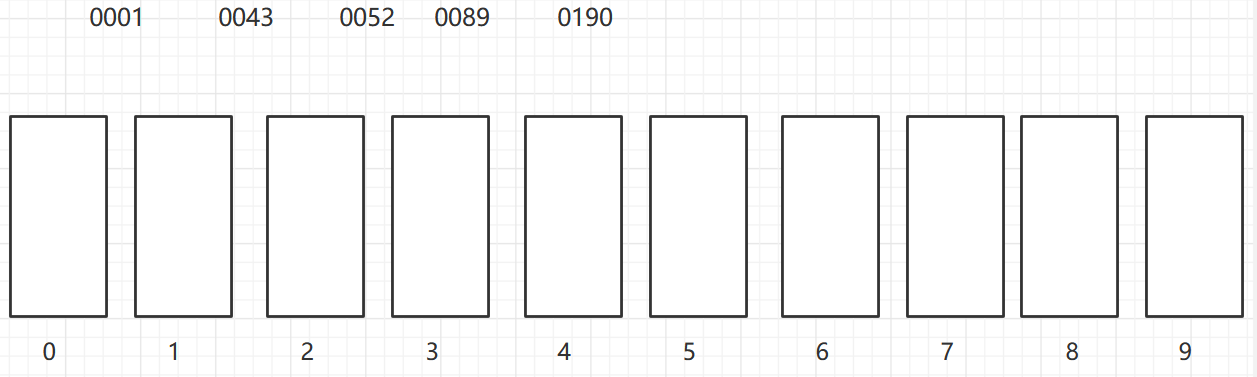
按照个位,放到对应的桶中
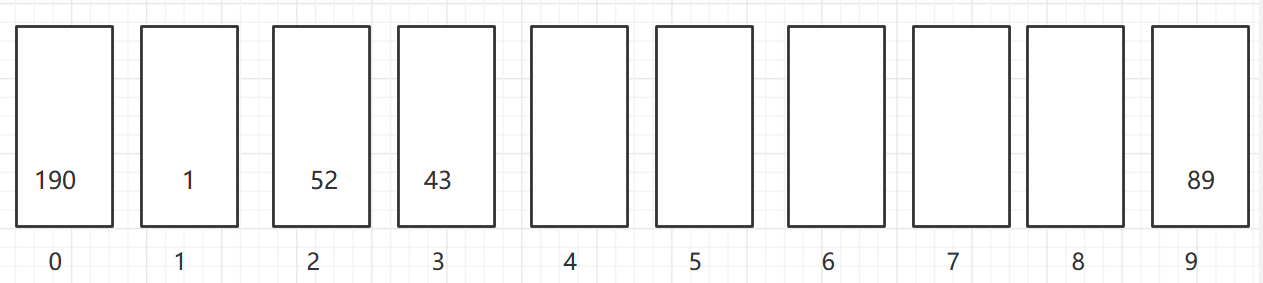
依次取出,同一个桶中有多个元素的,先放入的先取出
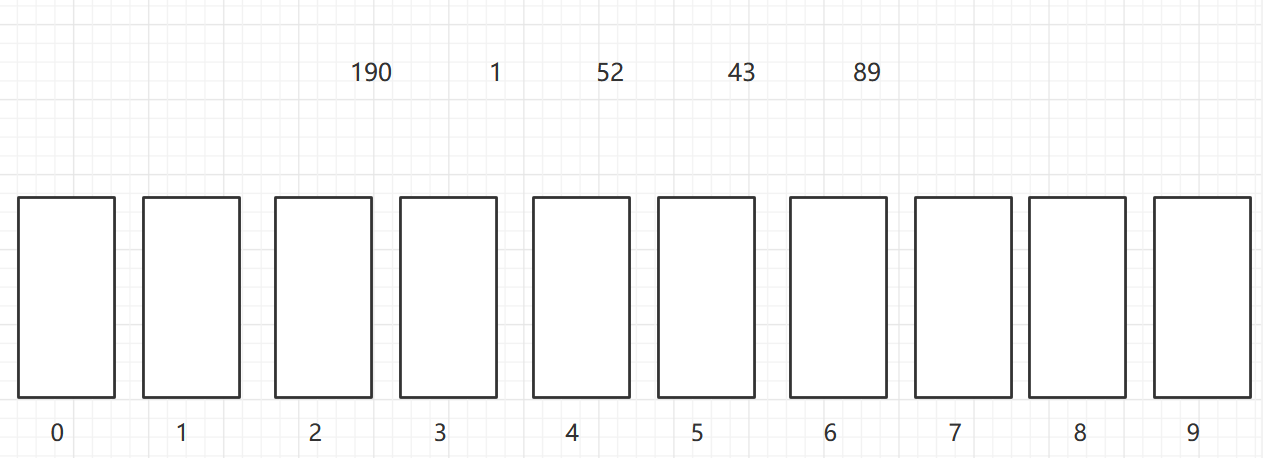
再按照十位,放到对应的桶中,个位数前面补0
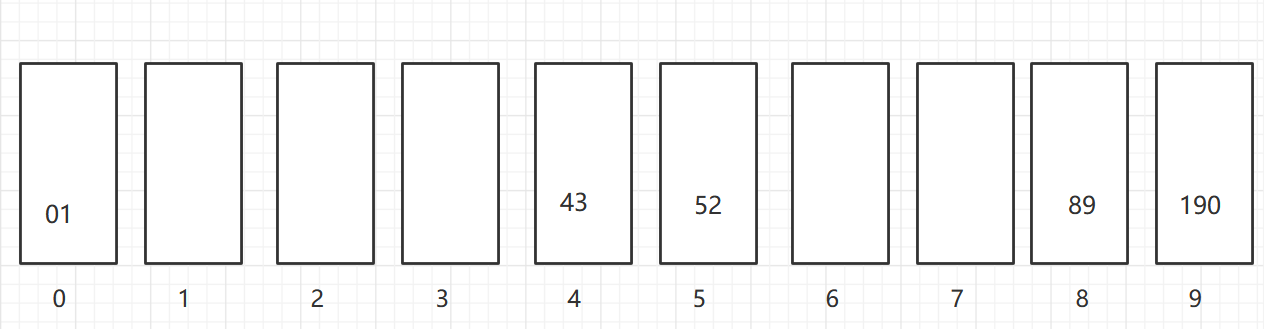
再依次取出桶中元素
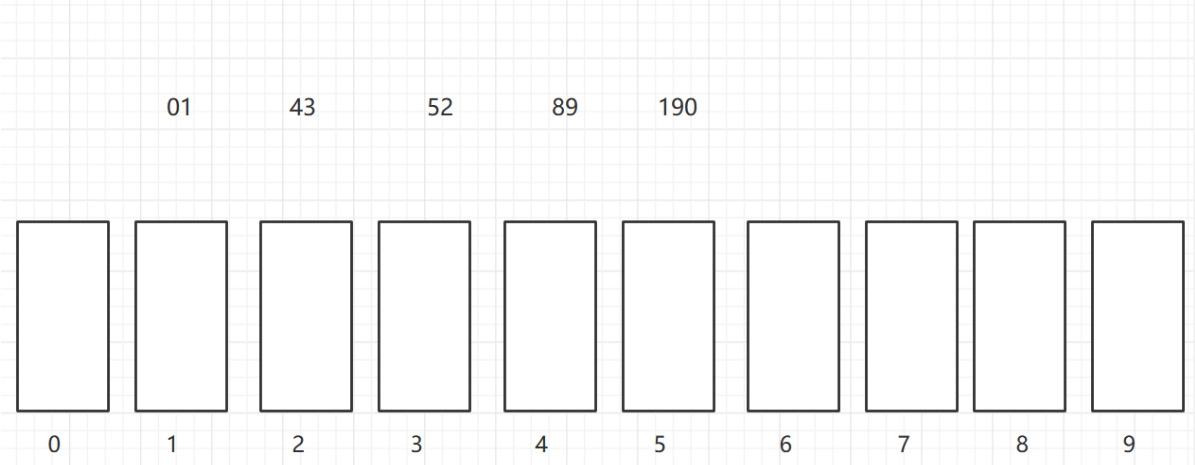
再按照百位,放到对应的桶中,个位数和十位数前面补0
再依次取出桶中元素
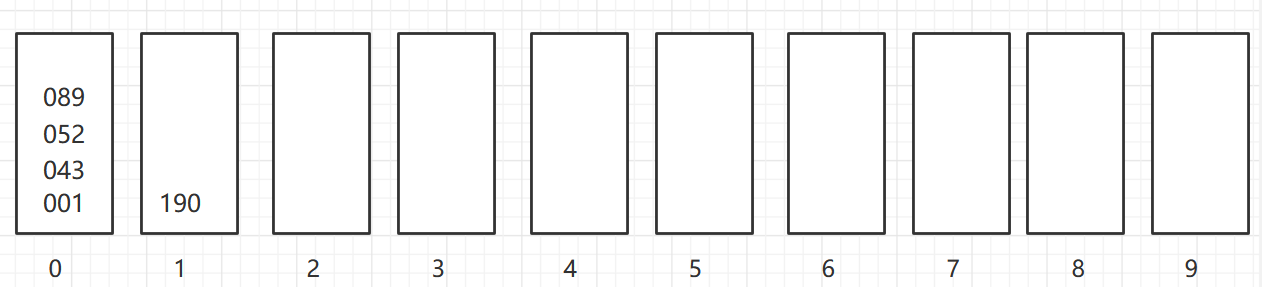
再按照千位,放到对应的桶中,个位数、十位数和百位数前面补0
 当所有的数都在0号桶时,依次取出元素,这时顺序即为排好后的顺序
当所有的数都在0号桶时,依次取出元素,这时顺序即为排好后的顺序
代码
public class Demo7 {
public static void main(String[] args) {
int[] arr = {43, 52, 1, 89, 190};
CardinalitySort cardinalitySort = new CardinalitySort();
cardinalitySort.sort(arr);
for(int a : arr) {
System.out.println(a);
}
}
}
class CardinalitySort {
/**
* 进行基数排序
* @param arr 待排序的数组
*/
public void sort(int[] arr) {
//创建一个二维数组,用于表示桶
//桶的个数固定为10个(个位是0~9),最大容量由数组的长度决定
int maxSize = arr.length;
int[][] bucket = new int[10][maxSize];
//用于记录每个桶中有多少个元素
int[] elementCounts = new int[10];
//获得该数组中最大元素的位数
int maxDigits = getMaxDigits(arr);
//将数组中的元素放入桶中, step是在求数组位数时,需要除以的倍数
for (int time = 1, step = 1; time<=maxDigits; time++, step *= 10) {
for(int i = 0; i<arr.length; i++) {
//取出所需的位数
int digits = arr[i] / step % 10;
//放入到对应的桶中 [digits]代表桶的编号
//[elementCounts[digits]]代表放入该桶的位置
bucket[digits][elementCounts[digits]] = arr[i];
//桶中元素个数+1
elementCounts[digits]++;
}
//将桶中的元素重新放回到数组中
//用于记录应该放入原数组的哪个位置
int index = 0;
for(int i = 0; i<10; i++) {
//从桶中按放入顺序依次取出元素,放入原数组
int position = 0;
//桶中有元素才取出
while (elementCounts[i] > 0) {
arr[index] = bucket[i][position];
position++;
elementCounts[i]--;
index++;
}
}
}
}
/**
* 得到该数组中最大元素的位数
* @param arr 待求数组
* @return 最大元素的位数
*/
public int getMaxDigits(int[] arr) {
int max = arr[0];
for(int i=1; i<arr.length; i++) {
if(arr[i] > max) {
max = arr[i];
}
}
//将最大值转为字符串,它的长度就是它的位数
int digits = (max + "").length();
return digits;
}
}11、堆排序
基本介绍
-
堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为 O(nlogn),它也是不稳定排序
-
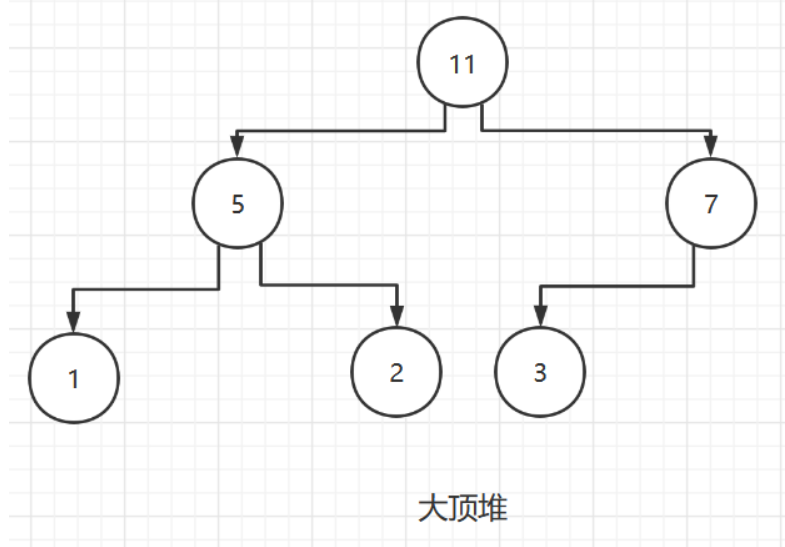
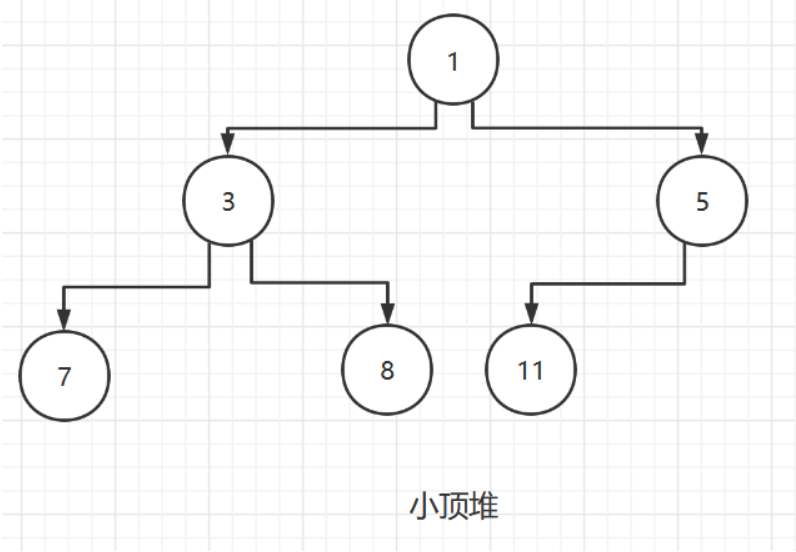
堆是具有以下性质的完全二叉树:
- 每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆
- 注意 : 没有要求结点的左孩子的值和右孩子的值的大小关系
- 每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆
- 每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆
-
一般升序排序采用大顶堆,降序排列使用小顶堆
排序思路
- 堆是一种树结构,但是排序中会将堆进行顺序存储(变为数组结构)
- 将无序序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆
- 将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端
- 重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序
实现代码
/**
* @author Chen Panwen
* @data 2020/7/27 16:19
*/
public class Demo2 {
public static void main(String[] args) {
int[] arr = {4, 6, 8, 5, 9};
//堆排序
heapSort(arr);
System.out.println("堆排序后结果");
System.out.println(Arrays.toString(arr));
}
/**
* 堆排序(升序排序)
* @param arr 待排序数组
*/
public static void heapSort(int[] arr) {
for(int i=arr.length-1; i>=0; i--) {
//将数组调整为大顶堆,长度为未排序数组的长度
for(int j=arr.length/2-1; j>=0; j--) {
adjustHeap(arr, j, i+1);
}
//调整后,数组首元素就为最大值,与为元素交换
int temp = arr[i];
arr[i] = arr[0];
arr[0] = temp;
}
}
/**
* 将无序数组进行调整,将其调整为大顶堆
* @param arr 待调整的数组
* @param index 非叶子节点的索引
* @param length 待调整数组的长度
*/
public static void adjustHeap(int[] arr, int index, int length) {
//保存非叶子节点的值,最后需要进行交换操作
int temp = arr[index];
//进行调整操作
//index*2+1代表其左子树
for(int i = index*2+1; i<length; i = i*2+1) {
//如果存在右子树,且右子树的值大于左子树,就让索引指向其右子树
if(i+1<length && arr[i] < arr[i+1]) {
i++;
}
//如果右子树的值大于该节点的值就交换,同时改变索引index的值
if(arr[i] > arr[index]) {
arr[index] = arr[i];
index = i;
}else {
break;
}
//调整完成后,将temp放到最终调整后的位置
arr[index] = temp;
}
}
}运行结果
堆排序后结果
[4, 5, 6, 8, 9]