【7.17 】 周总结
周总结
Monday
- 常见内置函数
- 可迭代对象
- 迭代器对象
- for循环的本质
Tuesday
- 异常捕获
- 异常捕获实参演练
- 异常捕获练习
- 生成器对象
- yield其他用法
- 生成器表达式
Wednesday
- 迭代取值与索引取值的差异
- 模块简介
- 导入模块的两种句式
- 两种导入句式的优缺点
- 补充知识
- 循环导入问题
- 判断文件类型
- 模块的查找顺序
Thursday
- 绝对导入与相对导入
- 包的概念
- 编程思想的转变
- 软件思想的转变
- 软件开发目录规范
- 常见的内置模块
Friday
- datetime模块
- os模块
- sys模块
- json模块
- json的实操
————————————————————————————————————————————————————————————————————————————————
M1 常见内置模块
内置函数:内存于内置空间里 全局可以任意分布由python解释器提前定义好的 直接可以调用的 其功能非常的便捷 好用 可以大大增高写代码的效率
1.abs() # 求绝对值
print(abs(-1312)) # 1312
"绝对值为正数"
2.all() # 作用是判断容器内所有的数据值的布尔值是否都为True
print(all((1,23,24,3243,54,6546,))) # True
print(all((1,23,24,3243,54,6546,0))) # False
print(all((1,23,24,3243,54,6546,{}))) # False
print(all((1,23,24,3243,54,6546,[]))) # False
"容器内的每个数据值的布尔值都为 True 结果才为True 只要有一个不为 True 结果都为 False "
3.any() # 容器内只要有一个数据值的布尔值为 Ture 结果就为 True
print(any([23,123,4324,354,54])) # True
4.bin() oct() hex() # 十进制的转换为其他进制 bin() 二进制 oct() 八进制 hex() 十六进制
print(bin(100)) # 0b1100100
print(oct(100)) # 0o144
print(hex(100)) # 0x64
5.int() # 类型转换 把其他进制转换为 十进制
print(int(0b1100100)) # 100 二进制
print(int(0o144)) # 100 八进制
print(int(0x64)) # 100 十六进制
6.bytes() # 类型转换
res = bytes('为什么', 'utf8')
print(res) # b'\xe4\xb8\xba\xe4\xbb\x80\xe4\xb9\x88'
print(str(res, 'utf8')) # 为什么
"bytes 为字节 (涉及到字符编号)把字符串转换为字符编码 也就是计算机可以看懂语言 想转换回来 用字符串类型转换一下就可以了"
7.callable() # 判断变量加括号是否就可以直接调用了 call 在IT专业名词中的翻译是 调用 + () 加括号执行
def func():
print('from func')
func() # from func
print(callable(func)) # True
"上述func为 True 可调用"
l1 = 'jaosn'
print(callable(l1)) # False
" 上述l1 为 False 不可调用 "
8.chr() ord() # 依据字符编号ASCII码表 实现字符与数字的转换
print(chr(65)) # A 65-90
print(chr(97)) # a 97-122
print(ord('A')) # 65
print(ord('a')) # 97
9.divmod() # 获取除法后的整数与余数
print(divmod(10,2)) # (5, 0) 5 是整数 0是余数
print(divmod(801,4)) # (200, 1)
10.enumerate() # 枚举 可以循环打印出数据值并且对应的索引值
l1 = ['a','b','c','d']
for i,b in enumerate(l1,1): # 这里的1 作为索引值可以自定义
print(i,b) # 1 a 2 b 3 c 4 d
11.eval() exec() # 能够识别字符串中的python代码
res = 'print213'
print(eval(res)) # 213 eval 能够识别简单的代码
exec() # 可以识别复杂结构的代码
res = "for i in range(20):print(i)"
exec(res) # 1 2 3...19
12.hash() # 返回一串随机数字(哈希值)
print(hash('make')) # -433113546
print(hash('哈哈')) # 1055926052
13.help() # 查看帮助信息
help(input) # 可以查看到具体的使用方法
14.isinstance() # 判断数据类型是否属于某个类型的方法
print(isinstance('jaosn',str)) # True
print(isinstance('jason',int)) # False
15.pow() # 幂指数
print(pow(3,2)) # 9
16.round() # 用来判定数据值四舍五入的
print(round(12,3)) # 12
print(round(10.5)) # 10 结果不准确
"python 对数字运算不敏感"
M1 可迭代对象
-
迭代的含义
迭代的意思就是更新换代 并且每次的更新都以上一个"版本"为基础
1. 代码演示:
while True:
print(123)
"""不属于迭代 因为每次更新都没有基于上次"版本"为基础"""
a = 0
while a < 10:
print(a)
a += 1
"""属于迭代 因为每次更新都基于上一次"版本"为基础"""
1.. 如何判断可迭代对象
"""
只要能点出来__iter__方法的都叫可迭代对象
__xxx__ 凡是有双下划线开头 双下划线结尾的 这种类型的内置方法 统一读成为双下
"""
| 可迭代对象 | 不可迭代对象 |
|---|---|
| 字符串(str) | 整型(int) |
| 列表(list) | 浮点型(float) |
| 字典(dict) | 布尔值(bool) |
| 元组(tuple) | 函数名(def index()😃 |
| 集合(set) | |
| 文件 |
-
总结:
文件本身就是迭代器对象
可迭代对象都支持 for 循环取值
M1 迭代器对象
-
作用:
如果没有迭代器对象 我们取值只能依赖索引取值的方式 并且索引取值在取值方面是不完善的 有了迭代器对象的存在 才能对 字典 集合 这些无序类型进行循环取值 让取值变的更加的方便 完善
-
1.如何判断是否 为迭代器对象
用点的方式 点出来 内置有__iter__和__next__的对象都成为迭代器对象
- 2.可迭代对象与迭代器对象的关系
可迭代对象调用__iter__方式之后就变成了迭代器对象
迭代器对象调用__iter__方式无论多少次 都是迭代器对象本身 因为本来就已从可迭代对象变身成为迭代器对象了
- 3.迭代器对象迭代取值
res = 'make'.__iter__()
print(res.__next__()) # m
print(res.__next__()) # a
print(res.__next__()) # m
print(res.__next__()) # e
print(res.__next__()) # 没有值了 直接报错
d = {'name':'make', 'age':18}
res = a.__iter__() # 迭代器对象
print(res.__next__()) # name
print(res.__next__()) # age
l1 = [23,3,2,354,3554,645]
# 循环打印出列表里的所有数据值
res = l1.__iter__() # 先将列表变成迭代器对象 方便后期调用
count = 0 # 设定一个计时器 等于 0
while count< len(l1): # 计时器小于列表数据值总和
print(res.__next__()) # 用__netx__调用
count += 1 # 计时器每循环一次加一
- 4.迭代器补充说明
4.1 迭代器反复使用
l1 = [23,3,2,354,3554,645]
# print(l1.__iter__().__next__()) # 23
# print(l1.__iter__().__next__()) # 23
# print(l1.__iter__().__next__()) # 23
# print(l1.__iter__().__next__()) # 23
# print(l1.__iter__().__next__()) # 23
# print(l1.__iter__().__next__()) # 23
"""此结果是每次都产生一个新的迭代器对象"""
l1 = [23,3,2,354,3554,645]
res = l1.__iter__()
print(res.__iter__().__next__()) # 23
print(res.__iter__().__next__()) # 3
print(res.__iter__().__next__()) # 2
print(res.__iter__().__next__()) # 354
print(res.__iter__().__next__()) # 3554
""" 先定义好迭代器对象 每次都使用一个迭代器对象"""
4.2 每次写__iter__ 可以简写为iter()
netx 简写为netx()
4.3迭代器对象特殊的地方
无论是可迭代对象 还是迭代器对象 内部情况 外部都是无法看到的 可以帮你去储存庞大数据 需要的时候可以随时用 大大的帮你节省了内存情况 减少了能源消耗 就类似于百宝箱 多啦a梦的口袋 不需要的时候隐藏起来 需要的时候可以帮你造出来
M1 for 循环的本质
for循环的语法结构
for 变量名 in 可迭代对象:
循环体代码
1.for循环会自动把 in 后面的数据 调用 __iter__()变成迭代器对象
2.然后每次循环都调用__netx__()的方式去取值
3.最后没有值调用__next__()就会报错 但是 for 循环到最后检测到没有值的时候 会自动结束 不会报错
T2异常捕获
-
1.说明是异常?
在程序运行过程中出现的报错 没有按正常的流程走下去 出现错误 导致程序提前结束
也是就程序员口中的 'bug'
-
2.异常的结构
例子:
name # 随便在pycharm 上输入一个错误代码句式
打印后则会报错:
Traceback (most recent call last):
File "C:/pythonProject/7.11/02.py", line 20, in <module> # ①
name
② NameError: name 'name' is not defined ③
# 上面就是一个 报错异常 接下来我们看一下 异常的结构体 里面的关键信息
1.标注①句子中 有line关键字 提示哪一行代码出错了
2.标注② 冒号左边的英文提示错误类型
3.标注③ 冒号右侧提示具体错误的原因 也是修改bug 的关键
- 3.异常的类型(常见的)
NameError # 变量名不存在 没有赋值 报错
IndexError # 索性超出范围 报错
KeyError # 键不存在 报错
SyntaxError # 错误使用标点符号 报错
TypeError # 类型错误 对象用来表示值的类型非预期类型时发生的错误
AttributeError # 属性错误 指引用和赋值失败时引发属性错误
-
4.异常的分类:
4.1 语法错误:
不允许出现 要求一旦出现立马修改 属于原则错误
4.2 逻辑错误:
允许出现 最好是写好代码后自己先跑一遍 出错后以及修改 这样就会避免错误情况发生
T2 异常捕获实参演练
- 1.当自己也不确定写的代码 是否会出现异常情况
为了稳妥就需要自己写下代码处理异常
-
2.异常捕获就是提前察觉到代码的异常 并提前判断错误的类型 给到相对应的处理措施
-
3.异常捕获的代码实现
基本的语法结构(对症下药 针对性很强)
try:
可能会出错的代码(被try监控)
except 变量名错误 as e: # e就是具体错误的原因
print(e) # 可以打印出来看到具体原因
对应 变量名错误 的解决措施
except 键错误 as e:
对应 键错误 的解决措施
except 标注符号错误 as e:
对应 标注符号 的解决措施
except 索引错误 as e:
对应 索引错误 的解决措施
"""
针对具体的错误类型 用具体的解决措施 一一对应
"""
### 上述一一对应去预测判断的方式 太过于繁琐 有一种便捷
万能异常
"""
上述一一对应去预测判断的方式 太过于繁琐 有一种便捷方式 万能异常处理
"""
try:
# 键错误
# 变量名错误
# 标注符号错误
# 索引错误
except Exception as e: # 万能异常方式一(推荐)
# 对应错误的解决措施
except BaseException as e: # 万能异常方式二
# 对应错误的解决措施
- 4.异常捕获其他操作补充
4.1 else 与 finally
try:
age # try 检测代码体的错误
except Exception as e:
print('变量名错了')
else:
print('try监测的代码没有出错的情况下正常运行结束 则会执行else子代码')
finally:
print('try监测的代码不管有没有出错 都会会执行finally子代码')
4.2 断言
name = 'jason' # 通过一系列的手段获取来的数据
assert isinstance(name, list) # 断言数据属于什么类型 如果不对则直接报错 对则正常执行下面的代码
print('针对name数据使用列表相关的操作')
4.3 主动抛出异常
age = input('年龄输入>>>:').strip()
if age == '18':
raise Exception('不通过') # raise 就是关键字 主动抛出异常 只要输入设定的值就报错
else:
print('不是18 可以过')
"""
1. 在写代码的时候 异常捕获尽量不去用
2.被try监测的代码能尽量少就尽量少
"""
T2异常捕获练习
1.for 循环内部的本质
# 用while 循环 加异常捕获 就可以实现for循环的功能
l1 = [1,2,3,4,5,6,7,8,9,10]
res = l1.__iter__()
while True:
try:
print(res.__next__())
except Exception as e:
break
2.例题演练
data_source = {'jason|123', 'kevin|321', 'oscar|222'}
username = input('username>>>:').strip()
password = input('password>>>:').strip()
# 2.比对(循环一一比对 有一个正确就可以)
for data in data_source: # 'jason|123' 'kevin|321' 'oscar|222'
real_name, real_pwd = data.split('|') # jason 123 kevin 321 ...
if username = real_name and password = real_pwd:
print('登录成功')
break # 只要匹配正确 就应该立刻结束循环 避免资源浪费
else:
print('用户名或密码错误')
结果报错:
File "C:/pythonProject/7.11/02.py", line 71
if username = real_name and password = real_pwd:
^
SyntaxError: invalid syntax
"""
分析是在line71行出错的
出错类型是符号错误 语法错误
找到该问题 纠正就可
if username == real_name and password == real_pwd:
"""
T2 生成器对象
1.本质
生成器对象本质就是迭代器对象 迭代器是由解释器提供给我们的 我们使用时直接调用就可以了
生成器需要我们自己去定义 也就是相当于我们需要自己去制作 __iter__ __next__
2.生成器对象目的就是为了优化代码
可以不依赖索引取值的方式去做到循环取值
主要是可以节省数据类型的内存占用空间
3.生成器对象代码实现的步骤
def func():
print('我')
yield
print('你')
yield
print('他')
yield
"""
当函数体代码中有yield关键字
那么函数名第一次加括号调用不会执行函数体代码
而是由普通的函数变成了迭代器对象(生成器) 用返回值去接收一下就可以调用 __iter__ __next__
"""
res = func()
print(res) # <generator object func at 0x01A8AB88> 已经成为生成器对象
res.__next__() # 我
res.__next__() # 你
res.__next__() # 他
"""
yield可以在函数体代码中出现多次
调用__next__方法都会从上往下执行直到遇到yield代码停留在此处
后续再次调用时 直接从停留的地方 再次运行
直到调用完毕后报错
"""
def func():
print('我')
yield 100,200,300
print('你')
yield 90
print('他')
yield 80
print(res.__next__()) # 我 (100,200,300)
print(res.__next__()) # 你 90
print(res.__next__()) # 他 80
"""
yield后面如果有数据值 则会像return一样返回出去
如果有多个数据值逗号隔开 那么也会自动组织成元组返回
"""
- 课堂练习
# 编写生成器 实现range方法的功能
# 1.可以先以两个参数的功能编写
# def my_range(start_num, end_num): # 定义好两个形参 range(10)
# while start_num < end_num: # 循环打印形参 start_num < end_num
# yield start_num # 返回每次循环的start_num形参
# start_num += 1 # 每次循环打印都让形start_num自增1
#
# for i in my_range(1, 10):
# print(i)
# 2.再考虑一个参数的情况 range(10) range(0,10)
# def my_range(start_num, end_num=None): # my_range(10) 如果传入一个实参 end_unm 为默认值None 如果传入两个实参 就使用传入的参数
# if not end_num:
# end_num = start_num
# start_num = 0
# while start_num < end_num:
# yield start_num
# start_num += 1
# for i in my_range(10):
# print(i)
# 3.最后考虑三个参数的情况 range(10) range(0,10) range(1, 10, 2)
# def my_range(start_num, end_num=None, step=1): # my_range(1,10,2) 还是用默认值形参来确定本来的规律 如果传入新的实参就用传入的值
# if not end_num:
# end_num = start_num
# start_num = 0
# while start_num < end_num:
# yield start_num
# start_num += step # 正常情况下是间隔1 传入新的值 让间隔几 就加几
# for i in my_range(1, 10, 2):
# print(i)
# for i in my_range(1, 5):
# print(i)
# for i in my_range(10):
# print(i)
T2 yield 其他用法
1.示例:
def index(name, food=None):
print(f'{name}准备干夜宵!!!')
while True:
food = yield # send 给yield传值 赋值给到 food
print(f'{name}正在吃{food}')
res = index('小五')
res.__next__()
res.send('羊肉串') # 小五正在吃羊肉串 关键字send 起到传值并且自动调用__next__的方法
res.send('牛肉串') # 小五正在吃牛肉串
res.send('猪肉串') # 小五正在吃猪肉串
T2生成器表达式
l1 = [i*2 for i in range(10) if i >2]
print(l1) # [6, 8, 10, 12, 14, 16, 18]
"""
上述是列表生成式 演变一下 就可以变成生成器表达式
"""
l1 = (i*2 for i in range(10) if i >2)
print(l1) # <generator object <genexpr> at 0x01FDAB88>
print(list(l1)) # [6, 8, 10, 12, 14, 16, 18] 用列表类型转换一下就可以看到生成器表达式里所有的数据值
"""
上述是列表生成式 把中括号换成小括号 就可以变成生成器表达式
和迭代器一样 都是为了优化内存空间 都可以类比成工厂 当你需要什么的时候 工厂可以直接造给你用 随调随用 减少能源消耗
"""
W3 迭代取值与索引取值的差异
l1 = [1,2,3,4,5,6,7,8,9]
# print(l1[0]) # 1
# print(l1[2]) # 2
# print(l1[0]) # 1
# 迭代取值
# res = l1.__iter__()
# print(res.__next__()) # 1
# print(res.__next__()) # 2
# print(res.__next__()) # 3
"""
# 索引取值:
优点:可以根据自己的需求 精确的索引到想要的值 支持反复取值
缺点:针对无序的容器类型 比如 字典 集合 就无法用索引来取值
# 迭代取值:
优点:不区分容器类型 只要容器内有值 都可以取到 最基础通用的一种取值方式
缺点:无法反复的取值 不能回退取值 循环取值直到把最后一个值取出来后报错结束
"""
W3 模块简介
-
简介:
模块化是将程序分解为一个个的模块module,通过组合模块来搭建出一个完整的程序。
优点:
便于团队开发,方便维护,代码复用。
-
1.如何理解模块:
在python中一个脚本(.py)文件就是一个模块,创建模块实际上就是创建一个.py文件
相当于一系列功能的结合体集成了在一个模块内(.py文件内) 使用模块就相当于拥有使用了这个集合体所有的功能 非常的便捷
-
2.模块的分类
2.1 内置模块:
和内置空间一样 都是有解释器提供自带的 直接就可以使用的模块
import time
time.sleep()
首先使用import导入time包,这样意味着我们能够使用time包里的所有公共内容。最后利用time包的相关计时功能计算出该程序执行时长。调用模块可以减少函数的重复使用,精简代码。
-
2.2自定义模块
包含所有你自己定义的函数和变量的文件,其后缀名是.py 例:注册功能 登录功能 ...
自定义模块的时候要注意命名的规范,使用小写,不要使用大写,不要使用中文,不要使用特殊字符等
-
2.3第三方模块:
就是别人写好的模块 发布于网路上 使用前直接下载导用就可
例如:
图片识别 图形可视化 人脸识别 语音识别
-
模块的表现形式
1.py文件(py文件也可以称之为是模块文件)
2.含有多个py文件的文件夹(按照模块功能的不同划分不同的文件夹存储)
3.已被编译为共享库或DLL的c或C++扩展(了解)
4.使用C编写并链接到python解释器的内置模块(了解)W3 导入模块的两种句式
- 1.导入模块的句式1
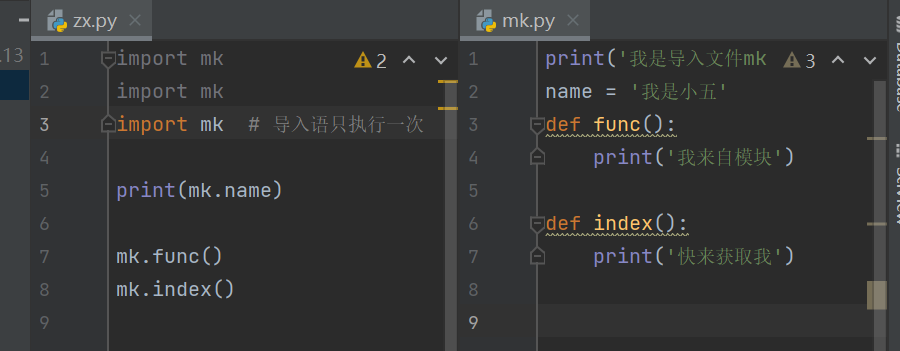
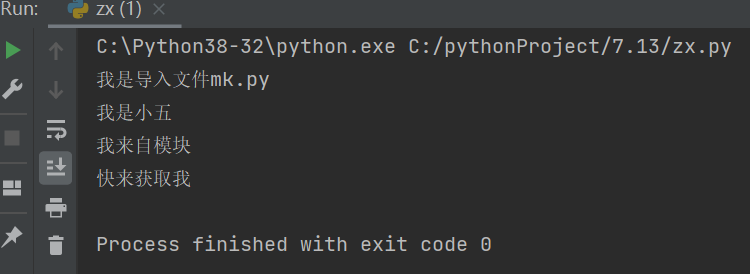
1.1.import句式 先创建一个模块(.py文件) 例如: mk.py 里面写入内容 在创建一个执行文件(zx.py) 用import mk 调用(不用去写入.py文件名的类型) 然后就可以去随意调用模块里的功能 过程: ①.创建执行文件时会产生一个执行的名称空间 ②.创建模块文件时会产生一个导入文件的名称空间 ③.模块名称空间内写入的代码功能 储存赋值的变量名 在被执行文件名称空间调用获取时指向被导入文件名称空间 ④.在执行文件中可以用import然后加上导入文件的名字 再用点的方式 点上被导入文件的名字 就可以随意获取模块里的功能信息了 注意: 在同一个执行文件内 反复去导入同一个模块 导入语只会执行一次 import mk # 有效 import mk # 无效 import mk # 无效![]()
![]()
-
2.导入模块的句式2
from...import...句式 from mk import name # 指名道姓导入(目标明确)
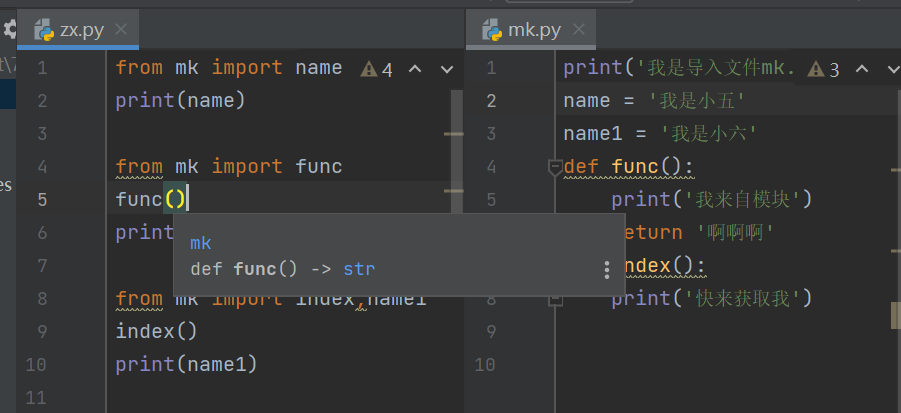
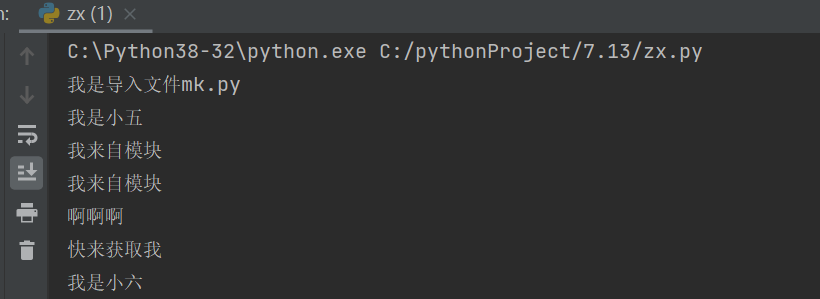
过程:
1.创建执行文件的名称空间
2.创建被导入文件的名称空间
3.执行被导入文件中的代码 将产生的名字存储到被导入文件的名称空间中
4.在执行文件中获取到指定的名字 指向被导入文件的名称空间
W3 两种导入句式的优缺点
| 句式类型 | 优点 | 缺点 |
|---|---|---|
| import mk | 导入语后 模块内的所有功能 都可以随意的去调用 | 模块里的内容暴露无遗 有时候并不想让他人所有的内容都被获取 |
| from mk import name,index | 可以明确的去获取想要的名字 不需要加模块名 | 名字很容易冲突 如果把绑定的关系修改 |
W3 补充知识
1.重命名
情况1:多个模块一起调用写入时 有些模块名相同 可以改名调用
for mk import name as mk_a
for mk1 import name as mk1_a
print(mk_a)
print(mk1_a)
情况2:模块名复杂时 也可以从新命名
import mkkkkkkkk as mk
2.导入多个模块内的多个名字
import mk1 mk2 mk3
# 如果多个模块内的功能相似 可以一起导入
如果类型不一建议分开
for mk import name1 index func
# 上述导入方式是想一次性导入同一个模块里的多个名字
3.全导入
from md import * # *表示所有
只有在固定只能使用 from ... import 方式的导入情况下 用加 * 的方式可以一次性全导入所有的名字
默认情况下 正常全部导入使用
但是如果在模块文件中使用__all__ = [字符串的名字]控制*能够获取的名字 那执行文件中的 * 就被限制使用的功能了
W3 循环导入问题
- 本质就是两个py文件 循环相互导入
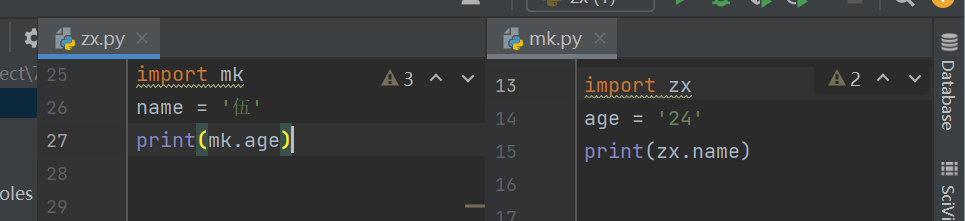
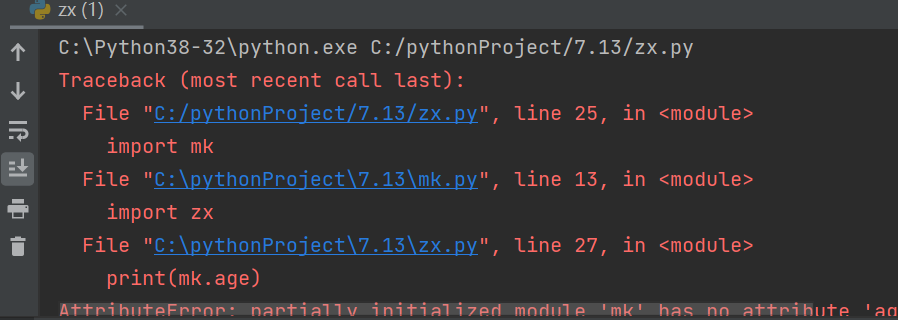
上述情况就是循环导入的结果
循环导入容易出现 报错现象
使用彼此的名字可能是在没有准备好的情况下就使用了
- 如何去解决循环报错现象
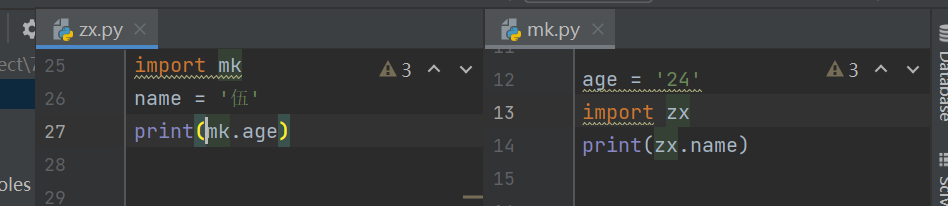
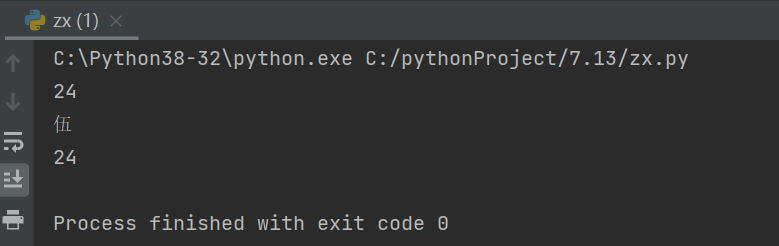
相互导入时 必须先有一方在被使用名字时 提前先准备好 上述所示
一般这种情况需要尽量避免 可以用另外的py文件去存储 如果真的避免不了 就想办法让所有的名字在使用之前提前准备好
W3 判断文件类型
所有的创建的py文件中都自带一个__name__内置名
情况一:
当py文件是执行文件的时候
运行__name__ 结果是__main__
情况二:
当py文件是被导入文件的时候
运行 __name__ 结果是模块名(文件名)
__name__主要用于开发模块的作者测试自己的代码使用
W3模块的查找顺序
先去内存中查找 > 内置空间找 > sys.path中找
1.导入一个模块 然后在导入过程中删除该模块发现还可以使用
import mk
import time
time.sleep(10)
print(mk.age) # 24
"""
即使运行时已删除了 但是名字已经存入到内存中了 执行文件找的时候 会先从内存中去找
"""
2.创建一个跟内置模块名相同的文件名
for time import name
# print(name)
#
# import time
# print(time.name)
""" 及时格式导入正确 但是还是会报错
创建模块时文件名尽量不要和内置模块名冲突
"""
3.导入模块的时候一定要知道谁是执行文件
所有的路径都是参照执行文件来的
import sys
sys.path.append(r'C:\pythonProject\7.13\mm')
import mkk
print(mkk.name)
"""
1.通用的方式
sys.path.append(目标文件所在的路径)
2.利用from...import句式
起始位置一定是执行文件所在的路径
from mm import mdd
"""
T4 绝对导入与相对导入
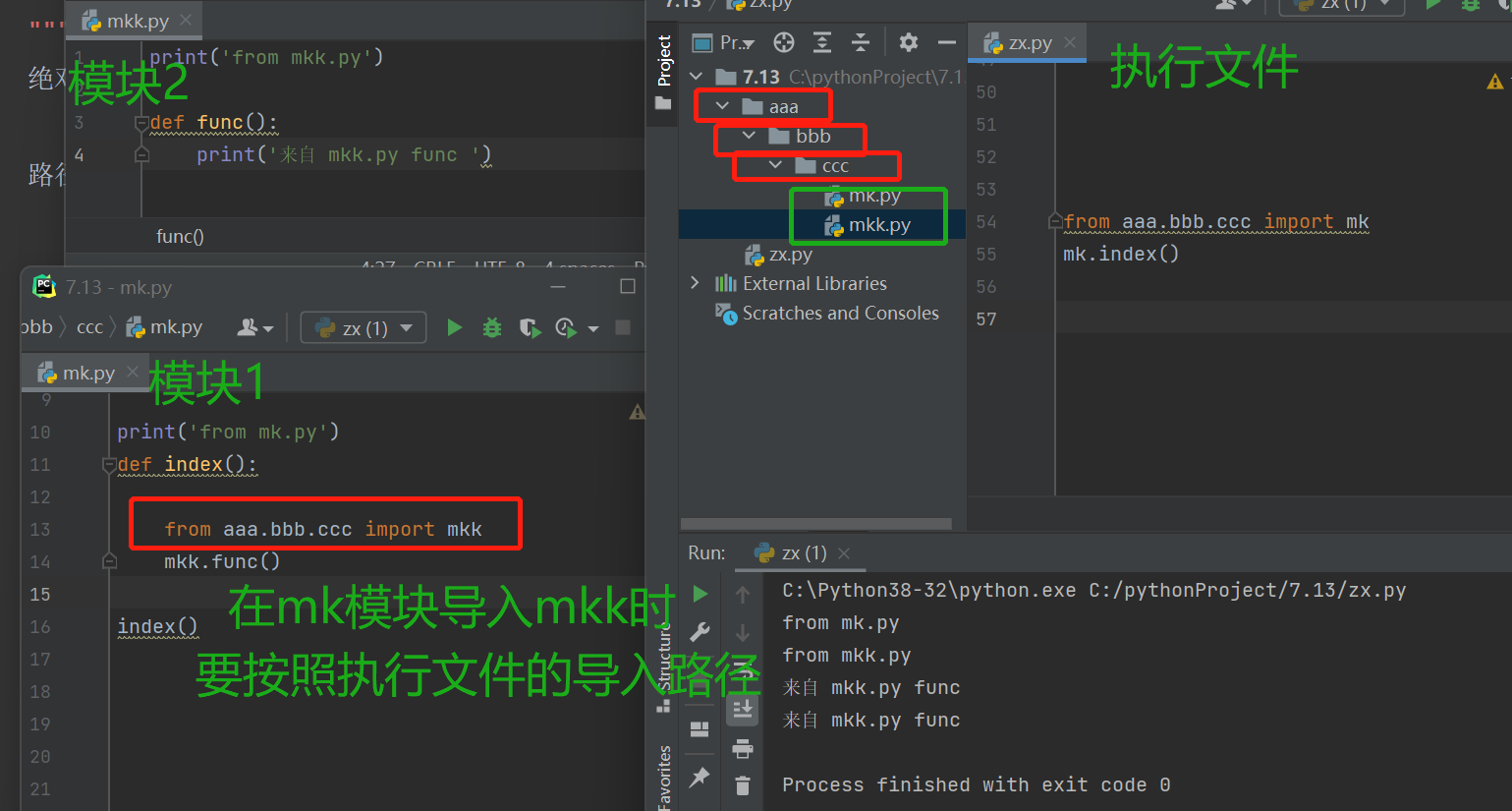
- 1.绝对导入
和和之前学过的绝对路径相同 所给的信息都是准确的 精确的 绝对导入也是一样 就是以执行文件所在的位置 sys.path 为起始路径 按照顺序一层层往下找
!!!!!!!!!!!!!!!!!!!!!!!!!!!
只要涉及到模块的导入 那么sys.path永远以执行文件为准
!!!!!!!!!!!!!!!!!!!!!!!!!!!
提醒:由于pycharm会自动将项目根目录添加到sys.path中所以查找模块肯定不报错的方法就是永远从根路径往下一层层找
注意:如果不是用pycharm运行 则需要将项目跟目录添加到sys.path
如果发送给他人 py文件 转移到其他电脑上 该如何获取:(针对项目根目录的绝对路径有模块可以帮助我们获取>>>:os模块)
2.相对导入
&& 相对导入的方法 我们首先来了解一下
. 在路径中意思是当前路径
.. 在路径中意思是上一层路径
../.. 在路径中意思是上上一层路径
注意:相对导入与绝对导入不同 相对导入 可以不参照执行文件的路径 直接以当前模块的路径为准
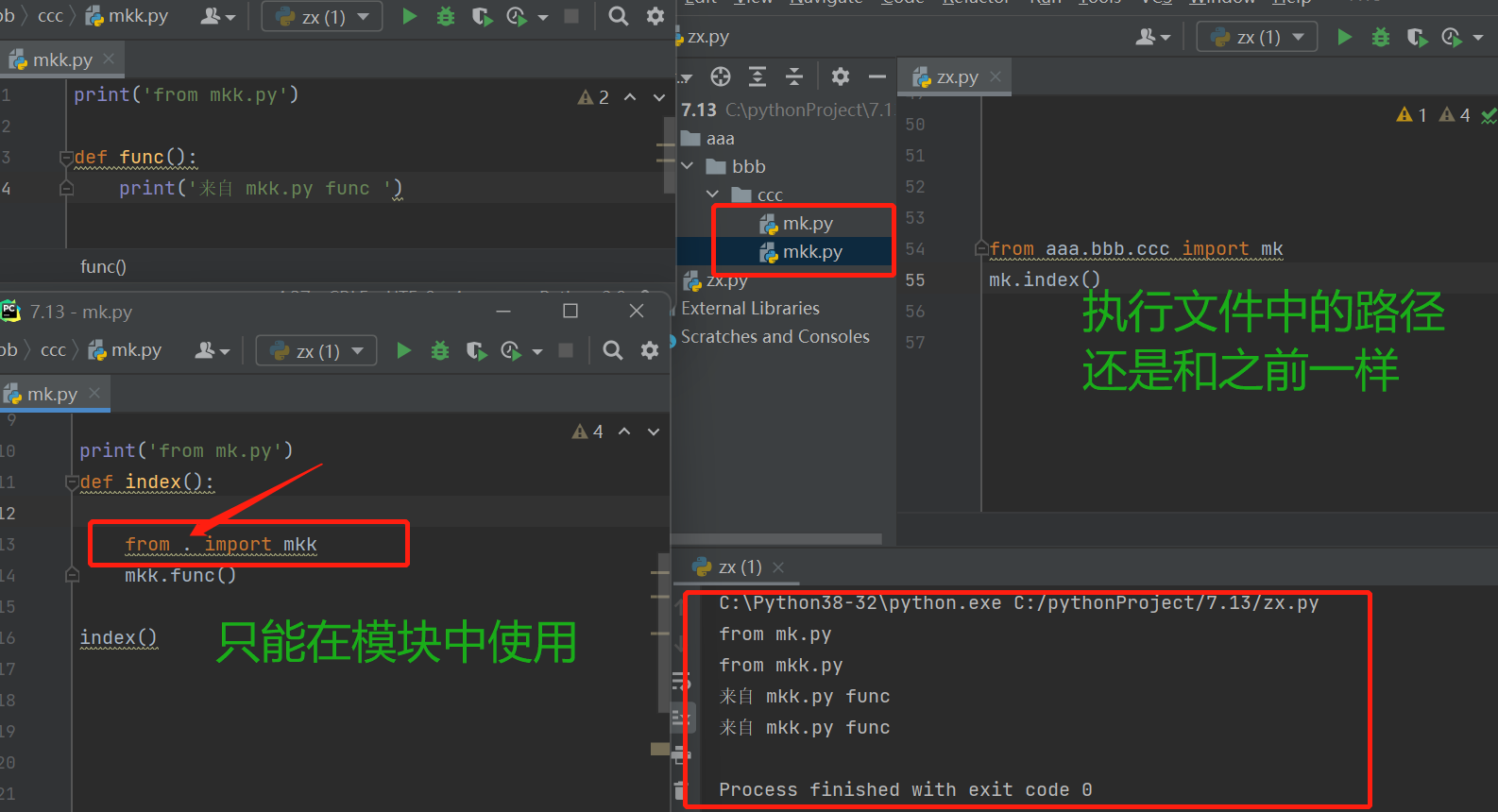
提醒:相对导入在项目比较复杂 文件夹很多的情况下 可能会弄混 容易出错 不建议使用
强烈建议:无脑使用绝对导入 肯定不会出错
T4包的概念
-
1.如何理解包
专业的角度:创建一个包 内部含有一个__init__.py 的文件夹
直观的角度:就像文件夹一样 没有太大区别
-
2.包的作用
就像文件夹一样 内部可以存放文件 包的内部存放的是多个py文件 (模块文件) 是为了 更加方便的管理模块文件
-
3.具体的使用方式
import + 包的名字 # 导入包名实际是导入包内部的 __init__.py 文件 __init__.py 文件内有什么 才能用什么 (一般情况 都是提前把包内部的模块文件功能 都以存入__itin__中 为了方便导入) # 也可以不通过__init__.py 文件 直接导入包里的模块文件 这样也可以 # 包在python2解释器和python3解释器中的区别解释 """ 针对python3解释器 其实文件夹里面有没有__init__.py已经无所谓了 都是包 但是针对Python2解释器 文件夹下面必须要有__init__.py才能被当做包 """T4 编程思想的转变
-
1.初始阶段
(在一个py文件中) 按需编写代码 (堆叠方式
-
2.函数阶段
(在多个py文件中)把不同功能的模块 区分放在不同的py文件中 方便编写导入
-
3.大致过程
初始阶段(文件全存在C盘)>>> 函数阶段(把C盘的文件分类存储)>>> 模块阶段(按照不同类型的功能 存入到不同的盘中)
-
【其目是为了更加方便快捷高效的管理资源】
T4 软件开发目录规范
| 文件夹名字 | 格式 | 作用 |
|---|---|---|
| bin文件夹 | start.py | 用于存储程序的启动文件 |
| conf文件夹 | settings.py | 用于存储程序的配置文件 |
| core文件夹 | src.py | 用于存储程序的核心逻辑 |
| lib文件夹 | common.py | 用于存储程序的公共功能 |
| db文件夹 | userinfo.txt | 用于存储程序的数据文件 |
| log文件夹 | log.log | 用于存储程序的日志文件 |
| interface文件夹 | ser.py order.py goods.py | 用于存储程序的接口文件 |
| readme文件(文本文件) | specification.txt | 用于编写程序的说明、介绍、广告 类似于产品说明书 |
| requirements.txt文件 | copy.txt | 用于存储程序所需的第三方模块名称和版本 |
- 仅供参考 文件名可以根据实际情况而取 stary.py 可以放在bin文件夹下也可以直接放在项目根目录下
T4常见内置模块
- 1.collections 模块(给使用者提供了更多的数据类型
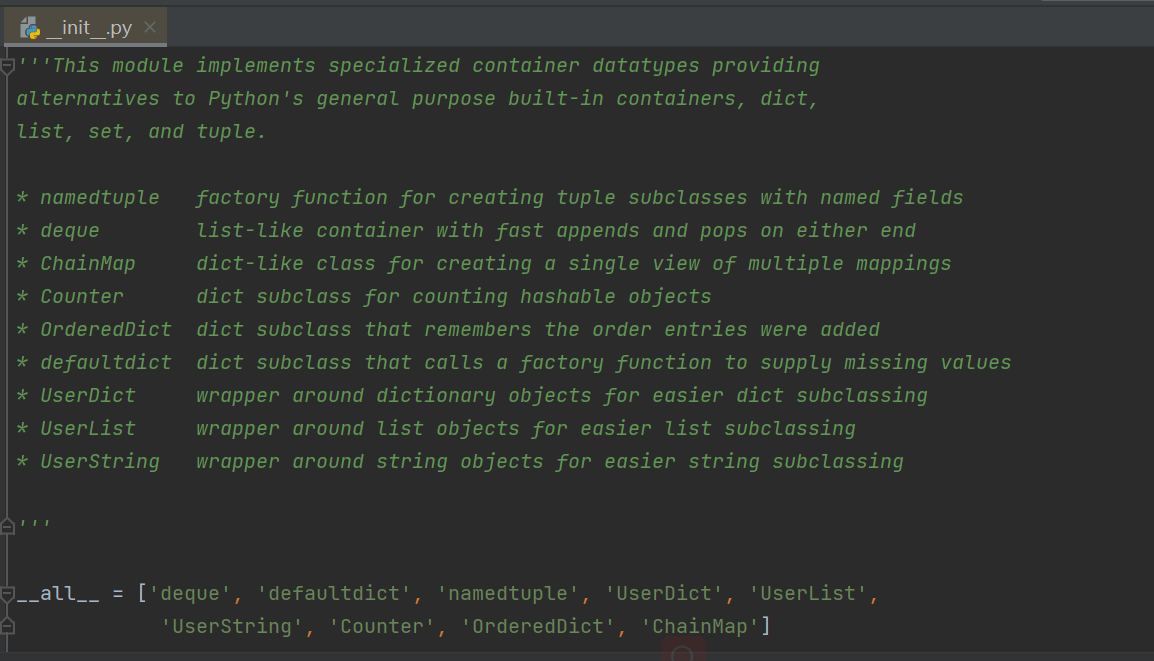
# 上述的 collections 相当于一个包 里面有 __init__文件 我们就是导入__init__使用里面的名字的
from collections import namedtuple
①
point = namedtuple('二维坐标系',['x','y'])
res = point(1,3) # 二维坐标系(x=1, y=3) 给上述式子传值
res1 = point(2,4) # 二维坐标系(x=2, y=4
print(res,res1) # 二维坐标系(x=1, y=3) 二维坐标系(x=2, y=4)
print(res.x) # 通过点的方式看坐标轴 x y 的值
print(res1.y) # 通过点的方式看坐标轴 x y 的值
from collections import namedtuple
②
Point = namedtuple('三维坐标系', 'x y z')
res1 = Point(23,45,6)
print(res1) # 三维坐标系(x=23, y=45, z=6) 也可以传输 x y z 三个值
res2 = Point(23,34,65)
print(res2) # 三维坐标系(x=23, y=34, z=65)
print(res1.z) # 6
print(res1,res2) # 三维坐标系(x=23, y=45, z=6) 三维坐标系(x=23, y=34, z=65)
from collections import namedtuple
③
n = namedtuple('扑克牌', ['花色', '点数'])
res1 = n('♥', 'A')
res2 = n('♠', 'A')
res3 = n('♦','A')
print(res1,res2,res3) # 扑克牌(花色='♥', 点数='A') 扑克牌(花色='♠', 点数='A') 扑克牌(花色='♦', 点数='A')
- 双端队列
from collections import deque
res = deque()
res.append(555) # deque([555])
res.append(222) # deque([555, 222])
res.appendleft(333) # deque([333, 555, 222])
print(res)
"""
通过调用模块 collections 用.append和.appendleft的方式 便捷的把数据值添加到容器里(双端队列)
"""
- 有序字典
from collections import OrderedDict
d = dict([('a',1),('b',2),('c',3)])
print(d) # {'a': 1, 'b': 2, 'c': 3}
od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
print(od) # OrderedDict([('a', 1), ('b', 2), ('c', 3)])
"""
OrderedDict 有序字典的意思 字典都是无序的 导入它就可以把你的地点变成有序字典
"""
- 默认值字典
#有如下值集合 [11,22,33,44,55,66,77,88,99,90],
# 将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中
情况一:
l1 = [11,22,33,44,55,66,77,88,99,90]
a = []
b = []
d = {}
for i in l1:
if i < 66:
a.append(i)
else:
b.append(i)
d['k1'] = a
d['k2'] = b
print(d) # {'k1': [11, 22, 33, 44, 55], 'k2': [66, 77, 88, 99, 90]}
情况二:默认值defaultdict
from collections import defaultdict
res = defaultdict(k1=[],k2=[])
for i in l1:
if i < 66:
res['k1'].append(i)
else:
res['k2'].append(i)
print(res) # defaultdict(None, {'k1': [11, 22, 33, 44, 55], 'k2': [66, 77, 88, 99, 90]})
- 统计次数
res = 'abcdeabcdabcaba'
情况一:
new_dict = {}
for i in res:
if i not in new_dict:
new_dict[i] = 1
else:
new_dict[i] += 1
print(new_dict) # {'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1}
情况二:
from collections import Counter
res1 = Counter(res)
print(res1) # Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
- 时间模块
| 时间 | 导入方式 |
|---|---|
| 时间戳 | time.time |
| 结构化时间 | time.gmtime() |
| 格式化时间 | time.strftime() |
F5 datatime模块
注意事项:
- 定义 py 文件名称时 尽量不要和模块名 (内置、第三方)发生名字上的冲突
"""
与之前学的time模块类型相似
time.time()
time.sleep()
都是与时间操作相关的模块
"""
# 模块名 :
datetime 年月日 时分秒
date 年月日
import datetime
res = datetime.datetime.today()
print(res) # 2022-07-15 16:04:35.507085
res1 = datetime.date.today()
print(res1) # 2022-07-15
print(res.year) # 2022
print(res.month) # 7 月
print(res.weekday()) # 4 是一个(0到6)之间的整数 也表示星期 但是从0开始计算
print(res.isoweekday()) # 5 星期5
# 模块名 :
timedelta括号内有很多参数
没有的时间可以通过换算得出
t1 = datetime.timedelta(days=4)
res1 = datetime.date.today()
print(res1)
print(res1 + t1) # 2022-07-19
print(res1-t1) # 2022-07-11
# 补充说明 :
rint(datetime.datetime.now()) # 2022-07-15 16:50:08.139104 现在时间
print(datetime.datetime.utcnow()) # 2022-07-15 08:50:08.139104 北半球时间
c =datetime.datetime(2008, 8, 8, 8, 8,8)
print('北京奥运会举办时间', c) # 指定时间 北京奥运会举办时间 2008-08-08 08:08:08
F5os模块
- 1.创建目录
import os
os.mkdir(r'aa') # 创建单机目录
os.mkdir(r'aa\bb') # 无法创建多级目录
os.makedirs(r'bb\cc\dd') # 可以创建多级目录
os.makedirs(r'ee') # 当然也可以创建单个目录
- 2.删除目录
import os
os.rmdir(r'ee') # 可以删除单级目录
os.rmdir(r'bb') # 删除的该目录里不能有其他的数据 也不支持删除多级目录
os.removedirs(r'aa') # 可以删除目录 但是只针对无任何数据的目录 有数据的目录删不掉
os.removedirs(r'bb\cc\dd') # 多层数据的删除 是从内而外递归删除空目录的 直到检测到有数据的目录停止删除
- 3..列举指定路径下的文件名称(文件、目录)
import os
print(os.listdir()) # 以列表的形式获取到的当前路径下的所有目录以及文件
print(os.listdir(r'c:\\PyCharm 2021.1.3')) # 也可以自己命令输入路径 ['bin', 'brokenPlugins.db', 'build.txt', 'classpath.txt', 'debug-eggs', 'help', 'icons.db', 'jbr', 'lib', 'license', 'plugins', 'product-info.json', 'skeletons']
- 4.重命名文件 删除文件
import os
# 重命名文件
os.rename(r'时间模块.py', r'时间 1 模块.py') # 由时间模块.py 改为 时间1模块.py
os.rename(r'aa.txt', r'b.txt') # 由aa.txt 改成 bb,txt
注意:必须在同一级目录下才可以操作重命名文件
# 删除文件
os.remove(r'a.txt') # 有无内容直接可以删除
os.remove(r'mm.py') # 直接删除
# 必须在同一级目录下才可以操作删除文件
- 5.获取当前工作路径(所在的路径)绝对路径
print(os.getcwd())
print(os.getcwd()) # C:\pythonProject\7.15day 当前工作文件所在的路径
os.chdir(r'..') # 配合 getcwd 切换路径使用 类似于cwd里的 cd
os.mkdir(r'文件') # 可以随意在路径下插入文件就会在该路径下生成插入的文件
print(os.getcwd()) # C:\pythonProject
- 6.与程序启动文件相关
print(os.path.abspath(__file__)) # 获取当前文件的绝对路径 C:\pythonProject\7.15day\os 模块.py
res = os.path.dirname(__file__)
print(res) # 获取当前文件所在的目录路径 C:/pythonProject/7.15day
res1 = os.path.dirname(os.path.dirname(__file__))
print(res1) # 嵌套可以提升到上一层级的路径 使用该模块 可以提升程序的兼容性 项目写好后 无论发到哪个设备上 都可以执行
- 7..判断路径是否存在(文件、目录)
import os
print(os.path.exists(r'll.py')) # True
print(os.path.exists(r'bb')) # True
print(os.path.exists(r'hh.py')) # False
"""
可以判断目录、文件是否存在 目录 文件必须要在同一层级上才可以判断
"""
print(os.path.isdir(r'cc')) # False
print(os.path.isdir(r'bb')) # True
"""
判断目录(文件夹)是否存在 也必须在同一层级上 才能判断
"""
print(os.path.isfile(r'zz.txt')) # True
print(os.path.isfile(r'll.py')) # True
print(os.path.isfile(r'hh.py')) # False
"""
判断 文件 是否存在 也必须在同一层级上 才能判断
"""
-
- 拼接路径
"""
需求有一个 a.txt 的文件 想拼接到某一个文件的路径下
"""
# 以往操作:
relative_path = 'a.txt'
absolute_path = r'C:\pythonProject\7.15day\bb\cc\dd'
print(absolute_path + relative_path)
"""
设计到路径拼接 用 + 号的方法不严谨 因为会涉及到不同系统的路径分隔符不一样 + 号只能适用win系统 建议统一使用 os 模块里的 join 方法
"""
relative_path = 'a.txt'
absolute_path = r'C:\pythonProject\7.15day\bb\cc\dd'
res = os.path.join(absolute_path,relative_path)
print(res)
"""
os.path.join join方法可以自动识别当前所在的操作系统并自动切换正确的分隔符 更加的严谨 xindows 用\ mas用/
"""
- 9.获取文件大小
"""
获取文件的大小 就是获取文件里有多少字节 单位是bytes
"""
print(os.path.getsize(r'时间模块.py')) # 2209
print(os.path.getsize(r'zz.txt')) # 16
"""
只能获取同层级的文件大小 不能获取其他层级的
"""
F5 sys模块
import sys
print(sys.path) # 结果是列表形式
print(sys.version) # 当前解释版本信息
print(sys.platform) # win32 查看当前品台
sys.argv
"""
主要适用于命令行 在命令行适用 命令行和程序做交互
"""
res = sys.argv
# 需求:命令行执行当前文件必须要提供用户名和密码 否则不准执行'''
解法1:
import sys
res = sys.argv
if len(res) == 3:
username = res[1]
password = res[2]
if username == 'jason' and password == '123':
print('您可以正在执行该文件')
else:
print('用户名或密码错误')
else:
print('请填写用户名和密码 二者不可或缺')
解法二:
import sys
res = sys.argv
try:
usrename = res[1]
password = res[2]
except Exception as e:
print('请输入用户名和密码')
else:
if usrename == 'jaosn' and password == '123':
print('执行')
else:
print('用户名或密码错误')
F5 json模块
-
理论
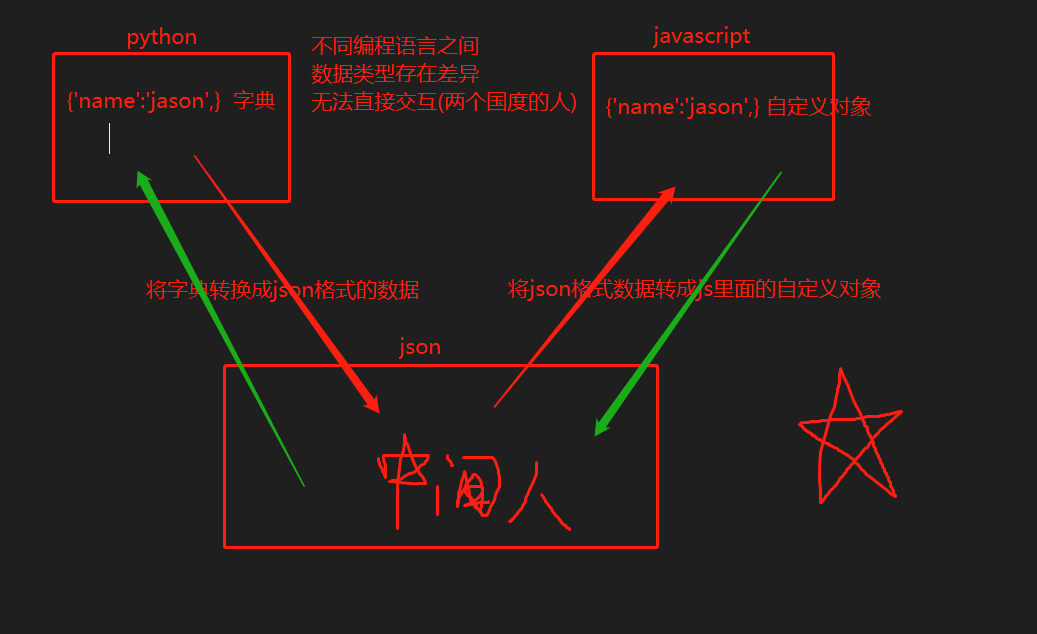
json模块也称之为序列化模块
json模块可以实现不同编程语言之间的数据交互
A编程--- json --B编程
A编程想和B编程做合作做项目 但是因为编程语言 命令不同 无法直接交互
所以必须需要通过 json 在中间转换一下(就相当于外国人(A)和中国人(B)在一起交流不畅通 需要翻译才能交流 这个 json模块 就是充当翻译的角色
-
json格式的数据应该是什么?
-
基于网络传输肯定是二进制
在python中只有字符串才能调用encode转换为二进制类型 进行传输 所以 json 格式的数据也是属于字符串
-
json格式特征:
- 必须是字符串 有双引号的标志
例题演示:
import json
dict1 = {'name':'make','age':18}
res = json.dumps(dict1) # 序列化 将其他的数据类型统一转换为 json 格式的数据类型 以便于传输
print(res,type(res)) # {"name": "make", "age": 18} <class 'str'> # 把其他的数据类型转换为json格式字符串 有双引号标志
# j = {"name": "make", "age": 18} # json格式不能直接写入(文本文件除外) 必须是json格式转换的
# print(j,type(j)) # {'name': 'make', 'age': 18} <class 'dict'> 自己写入后打印出的还是字典类型
res1 = json.loads(res) # 反序列化 将json格式的数据类型 转换为对应编程语音中的类型数据
print(res1,type(res1)) # 因为在python编程系统打印的json格式的数据类型 所以转换为的是原本的字典数据类型
"""
json dumps() 序列化
json loads() 反序列化
"""
# json 模块 基于文件存储 也提供了便捷的方式 想存入的数据类型不上字符串 只需要用下列方式转换一下 就可以了
import json
dict1 = {'name':'make','age':18}
with open(r'zz.txt','w',encoding='utf8')as f:
json.dump(dict1,f) # 可以直接把要存入的数据写入文件 (自动转换成json格式)
with open(r'zz.txt','r',encoding='utf8')as f:
res = json.load(f)
print(res) # 读取时 还是原来的存入前的数据类型 没有改变
"""
dump() 将其他数据类型以json格式字符串写入(w)文件
load() 将文件中json格式字符串读取(r)出来并转换成对应的数据类型
"""
F5 json模块的实操
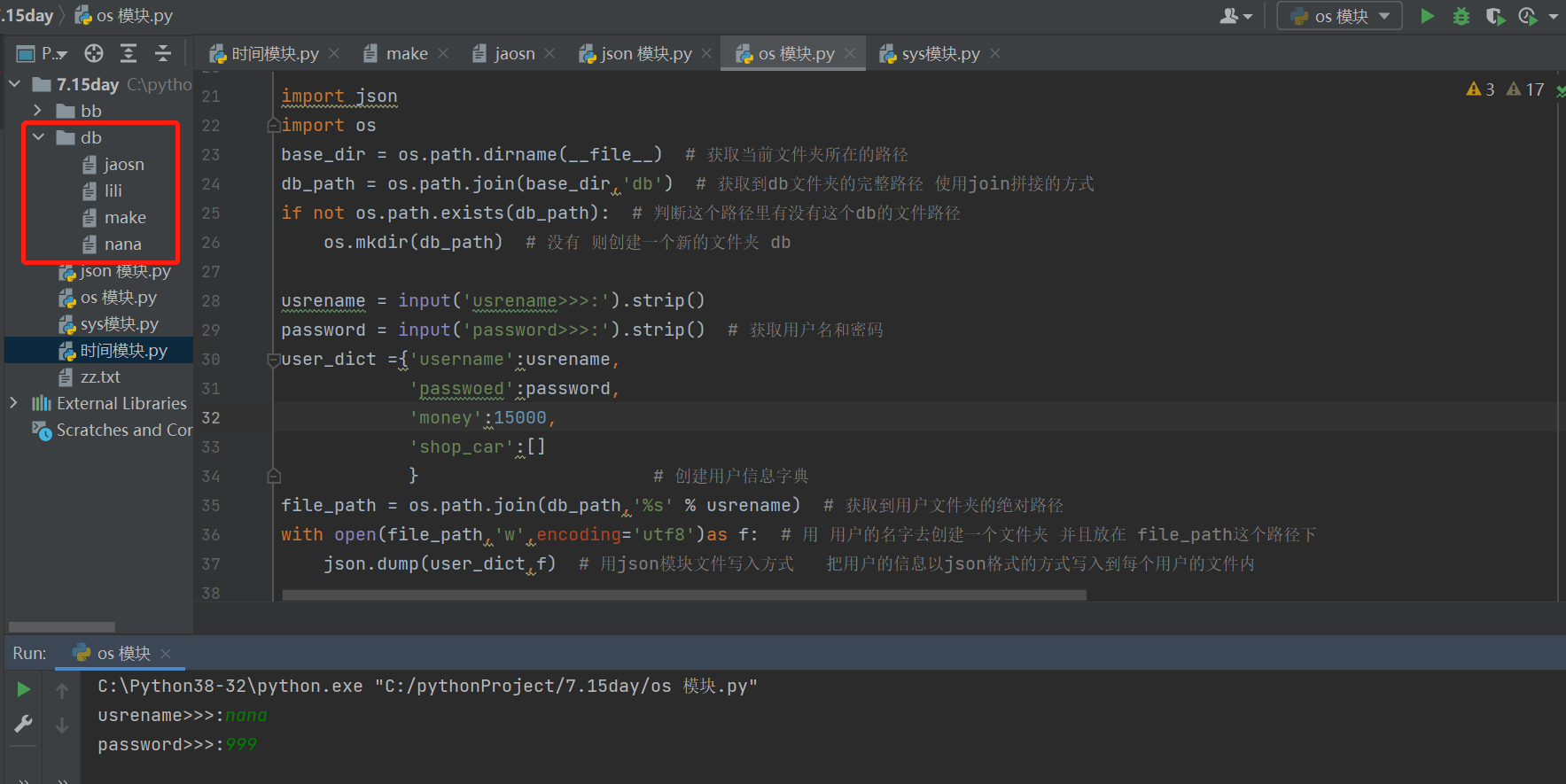
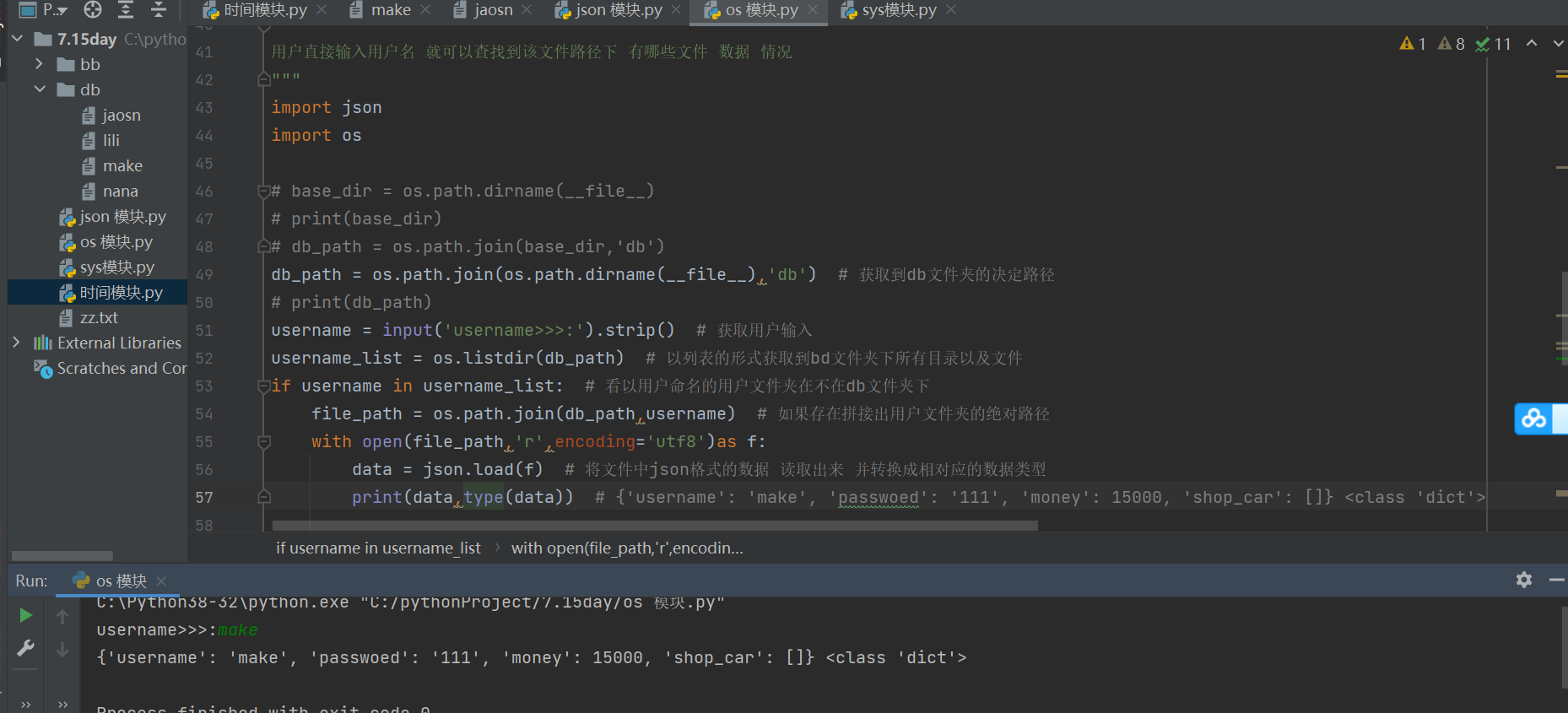
- 1.涉及到用户数据的存储 可以单用户单文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号