
MongoDB 学习总结
MongoDB 学习总结
题记:阅读了MongoDB技术文档,了解了NoSQL数据库,并对MongoDB进行了知识梳理。
1. NoSQL数据库分类
| 类型 | 部分代表 | 特点 |
|---|---|---|
| 列存储 | Hbase Cassandra Hypertable | 顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的IO优势。 |
| 文档存储 | MongoDB CouchDB | 文档存储一般用类似json的格式存储,存储的内容是文档型的。这样也就有有机会对某些字段建立索引,实现关系数据库的某些功能。 |
| key-value存储 | Tokyo Cabinet / Tyrant Berkeley DB MemcacheDB Redis | 可以通过key快速查询到其value。一般来说,存储不管value的格式,照单全收。(Redis包含了其他功能) |
| 图存储 | Neo4J FlockDB | 图形关系的最佳存储。使用传统关系数据库来解决的话性能低下,而且设计使用不方便。 |
| 对象存储 | db4o Versant | 通过类似面向对象语言的语法操作数据库,通过对象的方式存取数据。 |
| xml数据库 | Berkeley DB XML BaseX | 高效的存储XML数据,并支持XML的内部查询语法,比如XQuery,Xpath。 |
2. MongoDB基本概念
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
3. MongoDB基本操作
3.1 连接
3.2 创建
3.3 删除
3.4 插入
3.5 更新
-
criteria : update的查询条件,类似sql update查询内where后面的。
-
objNew : update的对象和一些更新的操作符(如inc...)等,也可以理解为sql update查询内set后面的
-
upsert : 这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
-
multi : mongodb默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
3.6 删除
- query :(可选)删除的文档的条件。
- justOne : (可选)如果设为 true 或 1,则只删除一个文档。
- writeConcern :(可选)抛出异常的级别。
3.7 查询
pretty() 方法以格式化的方式来显示所有文档。
3.8 条件操作符
MongoDB中条件操作符有:
- (>) 大于 - $gt
- (<) 小于 - $lt
- (>=) 大于等于 - $gte
- (<= ) 小于等于 - $lte
3.9 $type操作符
MongoDB 中可以使用的类型如下表所示:
| 类型 | 数字 | 备注 |
|---|---|---|
| Double | 1 | |
| String | 2 | |
| Object | 3 | |
| Array | 4 | |
| Binary data | 5 | |
| Undefined | 6 | 已废弃。 |
| Object id | 7 | |
| Boolean | 8 | |
| Date | 9 | |
| Null | 10 | |
| Regular Expression | 11 | |
| JavaScript | 13 | |
| Symbol | 14 | |
| JavaScript (with scope) | 15 | |
| 32-bit integer | 16 | |
| Timestamp | 17 | |
| 64-bit integer | 18 | |
| Min key | 255 | Query with -1. |
| Max key | 127 |
3.10 limit和skip方法
3.11 排序、索引、聚合
一些聚合的表达式:
| 表达式 | 描述 | 实例 |
|---|---|---|
| \(sum | 计算总和。 | db.mycol.aggregate([{\)group : {_id : "\(by_user", num_tutorial : {\)sum : "$likes"}}}]) | ||
| \(avg | 计算平均值 | db.mycol.aggregate([{\)group : {_id : "\(by_user", num_tutorial : {\)avg : "$likes"}}}]) | ||
| \(min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{\)group : {_id : "\(by_user", num_tutorial : {\)min : "$likes"}}}]) | ||
| \(max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate([{\)group : {_id : "\(by_user", num_tutorial : {\)max : "$likes"}}}]) | ||
| \(push | 在结果文档中插入值到一个数组中。 | db.mycol.aggregate([{\)group : {_id : "\(by_user", url : {\)push: "$url"}}}]) | ||
| \(addToSet | 在结果文档中插入值到一个数组中,但不创建副本。 | db.mycol.aggregate([{\)group : {_id : "\(by_user", url : {\)addToSet : "$url"}}}]) | ||
| \(first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate([{\)group : {_id : "\(by_user", first_url : {\)first : "$url"}}}]) | ||
| \(last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{\)group : {_id : "\(by_user", last_url : {\)last : "$url"}}}]) |
3.12 复制(副本集)
mongodb的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从、一主多从。
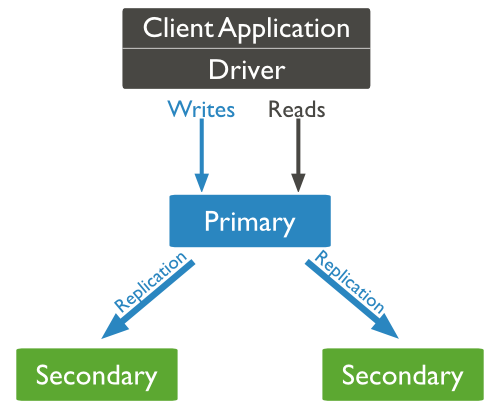
副本集特征:
- N 个节点的集群
- 任何节点可作为主节点
- 所有写入操作都在主节点上
- 自动故障转移
- 自动恢复
3.13 分片
在Mongodb里面存在另一种集群,就是分片技术,可以满足MongoDB数据量大量增长的需求。
当MongoDB存储海量的数据时,一台机器可能不足以存储数据也足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
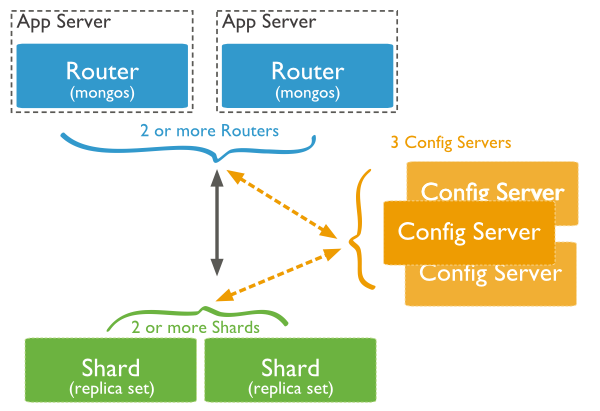
上图中主要有如下所述三个主要组件:
-
Shard:
用于存储实际的数据块,实际生产环境中一个shard server角色可由几台机器组个一个relica set承担,防止主机单点故障
-
Config Server:
mongod实例,存储了整个 ClusterMetadata,其中包括 chunk信息。
-
Query Routers:
前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
3.14 备份与恢复
-
-h:
MongDB所在服务器地址,例如:127.0.0.1,当然也可以指定端口号:127.0.0.1:27017
-
-d:
需要备份的数据库实例,例如:test
-
-o:
备份的数据存放位置,例如:c:\data\dump,当然该目录需要提前建立,在备份完成后,系统自动在dump目录下建立一个test目录,这个目录里面存放该数据库实例的备份数据。
-
-h:
MongoDB所在服务器地址
-
-d:
需要恢复的数据库实例,例如:test,当然这个名称也可以和备份时候的不一样,比如test2
-
--directoryperdb:
备份数据所在位置,例如:c:\data\dump\test,这里为什么要多加一个test,而不是备份时候的dump,读者自己查看提示吧!
-
--drop:
恢复的时候,先删除当前数据,然后恢复备份的数据。就是说,恢复后,备份后添加修改的数据都会被删除
3.14 监控
3.15 关系
嵌入式关系、引用式关系
3.16 数据库引用
3.17 覆盖索引查询
官方的 MongoDB 的文档中说明,覆盖查询是以下的查询:
- 所有的查询字段是索引的一部分
- 所有的查询返回字段在同一个索引中
由于所有出现在查询中的字段是索引的一部分, MongoDB 无需在整个数据文档中检索匹配查询条件和返回使用相同索引的查询结果。
因为索引存在于RAM中,从索引中获取数据比通过扫描文档读取数据要快得多。
3.18 查询分析
explain 操作提供了查询信息,使用索引及查询统计等。有利于我们对索引的优化。
3.19 原子操作
mongodb不支持事务,但是mongodb提供了许多原子操作,比如文档的保存,修改,删除等,都是原子操作。所谓原子操作就是要么这个文档保存到Mongodb,要么没有保存到Mongodb,不会出现查询到的文档没有保存完整的情况。
- $set
- $unset
- $inc
- $push
- $pushAll
- $pull
- $addToSet
- $rename
- $bit
3.20 高级索引及索引限制
索引数组字段
索引子文档字段
额外开销
每个索引占据一定的存储空间,在进行插入,更新和删除操作时也需要对索引进行操作。所以,如果你很少对集合进行读取操作,建议不使用索引。
内存(RAM)使用
由于索引是存储在内存(RAM)中,你应该确保该索引的大小不超过内存的限制。
如果索引的大小大于内存的限制,MongoDB会删除一些索引,这将导致性能下降。
查询限制
索引不能被以下的查询使用:
- 正则表达式及非操作符,如 not, 等。
- 算术运算符,如 $mod, 等。
- $where 子句
所以,检测你的语句是否使用索引是一个好的习惯,可以用explain来查看。
索引键限制
从2.6版本开始,如果现有的索引字段的值超过索引键的限制,MongoDB中不会创建索引。
插入文档超过索引键限制
如果文档的索引字段值超过了索引键的限制,MongoDB不会将任何文档转换成索引的集合。与mongorestore和mongoimport工具类似。
最大范围
- 集合中索引不能超过64个
- 索引名的长度不能超过125个字符
- 一个复合索引最多可以有31个字段
3.21 ObjectId
ObjectId 是一个12字节 BSON 类型数据,有以下格式:
- 前4个字节表示时间戳
- 接下来的3个字节是机器标识码
- 紧接的两个字节由进程id组成(PID)
- 最后三个字节是随机数。
3.22 MapReduce
参数说明:
- map :映射函数 (生成键值对序列,作为 reduce 函数参数)。
- reduce 统计函数,reduce函数的任务就是将key-values变成key-value,也就是把values数组变成一个单一的值value。。
- out 统计结果存放集合 (不指定则使用临时集合,在客户端断开后自动删除)。
- query 一个筛选条件,只有满足条件的文档才会调用map函数。(query。limit,sort可以随意组合)
- sort 和limit结合的sort排序参数(也是在发往map函数前给文档排序),可以优化分组机制
- limit 发往map函数的文档数量的上限(要是没有limit,单独使用sort的用处不大)
3.23 全文检索
3.24 正则表达式
使用 $regex 操作符来设置匹配字符串的正则表达式。
3.25 GridFS
-
用于存储和恢复那些超过16M(BSON文件限制)的文件(如:图片、音频、视频等)。
-
是文件存储的一种方式,但是它是存储在MonoDB的集合中。
-
可以更好的存储大于16M的文件。
-
会将大文件对象分割成多个小的chunk(文件片段),一般为256k/个,每个chunk将作为MongoDB的一个文档(document)被存储在chunks集合中。
-
用两个集合来存储一个文件:fs.files与fs.chunks。
-
每个文件的实际内容被存在chunks(二进制数据)中,和文件有关的meta数据(filename,content_type,还有用户自定义的属性)将会被存在files集合中。
3.26 固定集合
MongoDB 固定集合(Capped Collections)是性能出色且有着固定大小的集合,对于大小固定,我们可以想象其就像一个环形队列,当集合空间用完后,再插入的元素就会覆盖最初始的头部的元素!
3.27 自动增长
MongoDB 没有像 SQL 一样有自动增长的功能, MongoDB 的 _id 是系统自动生成的12字节唯一标识。
但在某些情况下,我们可能需要实现 ObjectId 自动增长功能。由于 MongoDB 没有实现这个功能,我们可以通过编程的方式来实现,以下我们将在 counters 集合中实现_id字段自动增长。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)