
动手学pytorch-文本预处理
文本预处理
预处理通常包括四个步骤:
- 读入文本
- 分词
- 建立字典,将每个词映射到一个唯一的索引(index)
- 将文本从词的序列转换为索引的序列,方便输入模型
读入文本
在此用一部英文小说,即H. G. Well的Time Machine,作为示例,展示文本预处理的具体过程。

# sentences 3221
分词
对每个句子进行分词,也就是将一个句子划分成若干个词(token),转换为一个词的序列。

[['the', 'time', 'machine', 'by', 'h', 'g', 'wells', ''], ['']]
建立字典
为了方便模型处理,需要将字符串转换为数字。因此需要先构建一个字典(vocabulary),将每个词映射到一个唯一的索引编号。

这里尝试用Time Machine作为语料构建字典
vocab = Vocab(tokens)
print(list(vocab.token_to_idx.items())[0:10])
[('', 0), ('the', 1), ('time', 2), ('machine', 3), ('by', 4), ('h', 5), ('g', 6), ('wells', 7), ('i', 8), ('traveller', 9)]
将词转为索引
使用字典,可以将原文本中的句子从单词序列转换为索引序列
for i in range(8, 10):
print('words:', tokens[i])
print('indices:', vocab[tokens[i]])
words: ['the', 'time', 'traveller', 'for', 'so', 'it', 'will', 'be', 'convenient', 'to', 'speak', 'of', 'him', '']
indices: [1, 2, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 0]
words: ['was', 'expounding', 'a', 'recondite', 'matter', 'to', 'us', 'his', 'grey', 'eyes', 'shone', 'and']
indices: [20, 21, 22, 23, 24, 16, 25, 26, 27, 28, 29, 30]
用现有工具进行分词
前面介绍的分词方式非常简单,它至少有以下几个缺点:
- 标点符号通常可以提供语义信息,但是我们的方法直接将其丢弃了
- 类似“shouldn't", "doesn't"这样的词会被错误地处理
- 类似"Mr.", "Dr."这样的词会被错误地处理
可以通过引入更复杂的规则来解决这些问题,但是事实上,有一些现有的工具可以很好地进行分词,在这里简单介绍其中的两个:spaCy和NLTK。
下面是一个简单的例子:
text = "Mr. Chen doesn't agree with my suggestion."
spaCy:
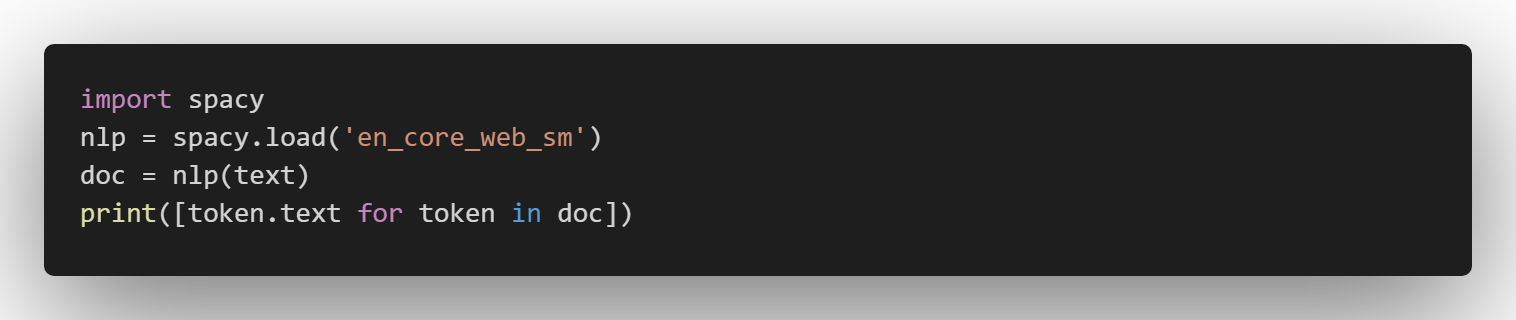
['Mr.', 'Chen', 'does', "n't", 'agree', 'with', 'my', 'suggestion', '.']
NLTK:
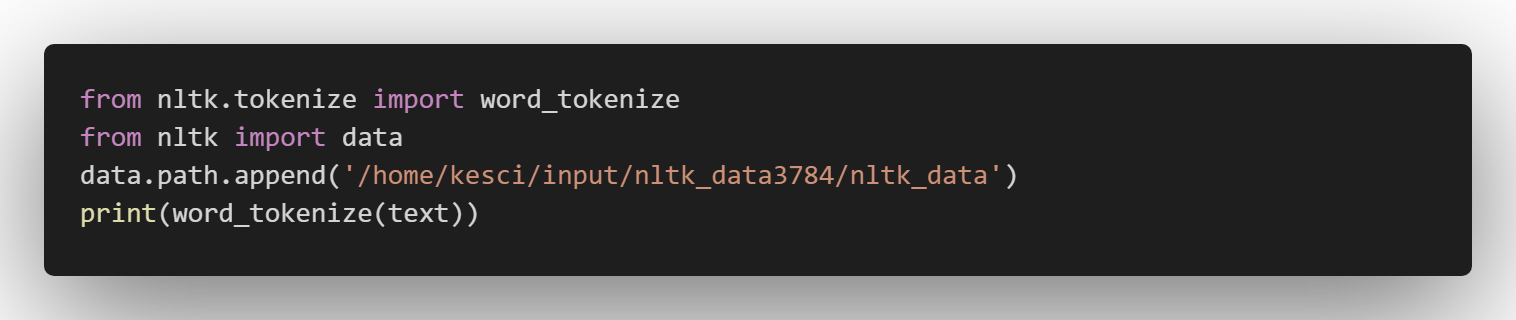
['Mr.', 'Chen', 'does', "n't", 'agree', 'with', 'my', 'suggestion', '.']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号