
动手学pytorch-softmax
1.softmax
\[ softmax(x_i) = \frac{ \exp(x_i)}{\sum_{j} \exp(x_j)}
\]
2.cross entropy
\[H\left(\boldsymbol y^{(i)}, \boldsymbol {\hat y}^{(i)}\right ) = -\sum_{j=1}^q y_j^{(i)} \log \hat y_j^{(i)},
\]
其中带下标的\(y_j^{(i)}\)是向量\(\boldsymbol y^{(i)}\)中非0即1的元素,需要注意将它与样本\(i\)类别的离散数值,即不带下标的\(y^{(i)}\)区分。在上式中,我们知道向量\(\boldsymbol y^{(i)}\)中只有第\(y^{(i)}\)个元素\(y^{(i)}{y^{(i)}}\)为1,其余全为0,于是\(H(\boldsymbol y^{(i)}, \boldsymbol {\hat y}^{(i)}) = -\log \hat y{y^{(i)}}^{(i)}\)。也就是说,交叉熵只关心对正确类别的预测概率,因为只要其值足够大,就可以确保分类结果正确。当然,遇到一个样本有多个标签时,例如图像里含有不止一个物体时,我们并不能做这一步简化。但即便对于这种情况,交叉熵同样只关心对图像中出现的物体类别的预测概率。
假设训练数据集的样本数为\(n\),交叉熵损失函数定义为
\[\ell(\boldsymbol{\Theta}) = \frac{1}{n} \sum_{i=1}^n H\left(\boldsymbol y^{(i)}, \boldsymbol {\hat y}^{(i)}\right ),
\]
其中\(\boldsymbol{\Theta}\)代表模型参数。同样地,如果每个样本只有一个标签,那么交叉熵损失可以简写成\(\ell(\boldsymbol{\Theta}) = -(1/n) \sum_{i=1}^n \log \hat y_{y^{(i)}}^{(i)}\)。从另一个角度来看,我们知道最小化\(\ell(\boldsymbol{\Theta})\)等价于最大化\(\exp(-n\ell(\boldsymbol{\Theta}))=\prod_{i=1}^n \hat y_{y^{(i)}}^{(i)}\),即最小化交叉熵损失函数等价于最大化训练数据集所有标签类别的联合预测概率。
3.手写
4.使用pytorch简易实现

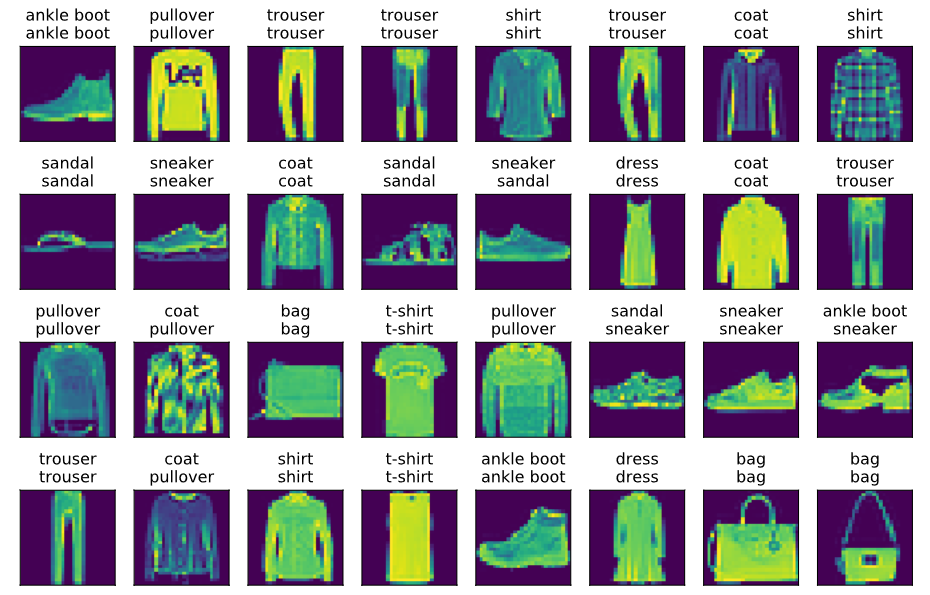
5.预测结果展示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号