线性表结构:栈
栈简介#
后进者先出,先进者后出,这就是典型的“栈”结构。
从栈的操作特性上来看,栈是一种“操作受限”的线性表,只允许在一端插入和删除数据。
看了上面的介绍,你会发现从功能上来说,数组或链表是可以替代栈的。但你要知道,特定的数据结构是对特定场景的抽象,而且,数组或链表暴露了太多的操作接口,操作上的确灵活自由,但使用时就比较不可控,自然也就更容易出错。
当某个数据集合只涉及在一端插入和删除数据,并且满足后进先出、先进后出的特性,我们就应该首选“栈”这种数据结构。
手动实现栈结构#
从刚才栈的定义里,我们可以看出,栈主要包含三个操作,入栈、出栈和获取栈顶元素,也就是在栈顶插入一个数据和从栈顶删除一个数据。理解了栈的定义之后,我们来看一看如何用代码实现一个栈。
实际上,栈既可以用数组来实现,也可以用链表来实现。用数组实现的栈,我们叫作顺序栈,用链表实现的栈,我们叫作链式栈。
public class MyStack<E> {
private int size;
private Object[] array;
public MyStack() {
// 默认创建长度是10的数组
array = new Object[10];
size = 0;
}
public MyStack(int capacity) {
// 默认创建长度是10的数组
array = new Object[capacity];
size = 0;
}
public E peek() {
if (size == 0) {
return null;
} else {
return (E) array[size - 1];
}
}
public E pop() {
if (size == 0) {
return null;
} else {
E item = (E) array[size - 1];
size--;
return item;
}
}
public boolean push(E item) {
int len = array.length;
if (len == size) {
Object[] ta = new Object[(int) (len * 1.5)];
System.arraycopy(array, 0, ta, 0, size);
array = ta;
}
array[size] = item;
size++;
return true;
}
}
上面操作的入栈和出栈操作的时间复杂度都是O(1)。
JDK中的栈结构#
在Java中,我们一般用LinkedList来实现栈的功能。
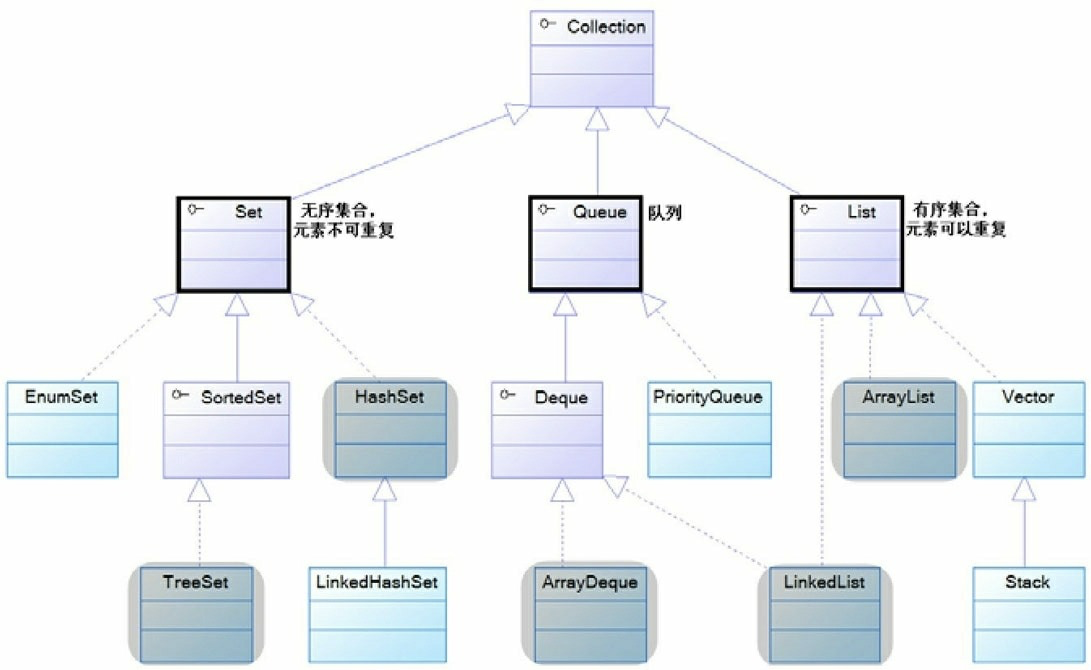
LinkedList实现了Deque接口,Deque接口定义了pop和push方法。
public class MyStack<E> {
private LinkedList<E> list;
public MyStack() {
this.list = new LinkedList<>();
}
public MyStack(E data){
Set<E> singleton = Collections.singleton(data);
this.list = new LinkedList<>(singleton);
}
public E peek() {
return list.peek();
}
public E pop() {
return list.pop();
}
public void push(E item) {
list.push(item);
}
}
还是需要提示的是:LinkedList并不是线程安全的,如果需要做线程安全的栈,需要自己进行手动同步。
使用场景#
1. 浏览器前进后退
在浏览器的同一个“tab”中访问了多个页面,我们可以使用浏览器的前进和后退功能来进行前后翻页。
这个功能也可以通过栈来实现。
我们使用两个栈,X 和 Y,我们把首次浏览的页面依次压入栈 X,当点击后退按钮时,再依次从栈 X 中出栈,并将出栈的数据依次放入栈 Y。当我们点击前进按钮时,我们依次从栈 Y 中取出数据,放入栈 X 中。当栈 X 中没有数据时,那就说明没有页面可以继续后退浏览了。当栈 Y 中没有数据,那就说明没有页面可以点击前进按钮浏览了。
比如你顺序查看了 a,b,c 三个页面,我们就依次把 a,b,c 压入栈,这个时候,两个栈的数据就是这个样子:
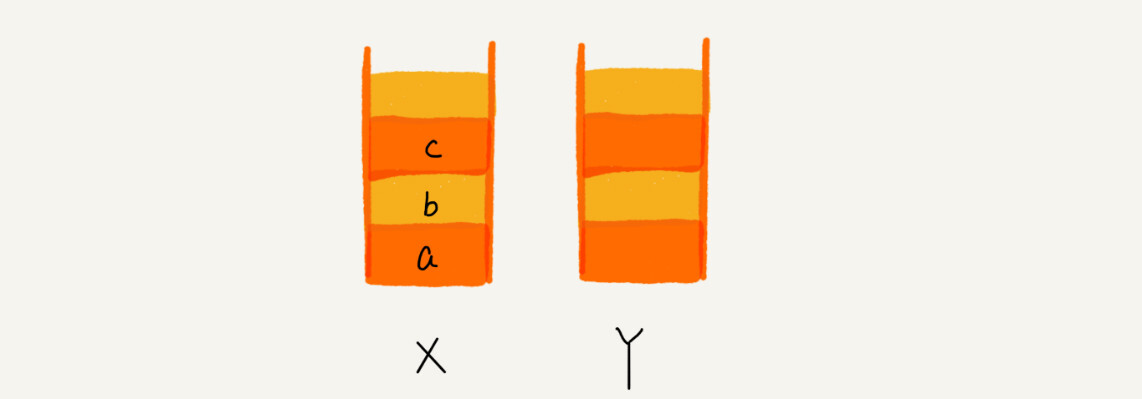
当你通过浏览器的后退按钮,从页面 c 后退到页面 a 之后,我们就依次把 c 和 b 从栈 X 中弹出,并且依次放入到栈 Y。这个时候,两个栈的数据就是这个样子:
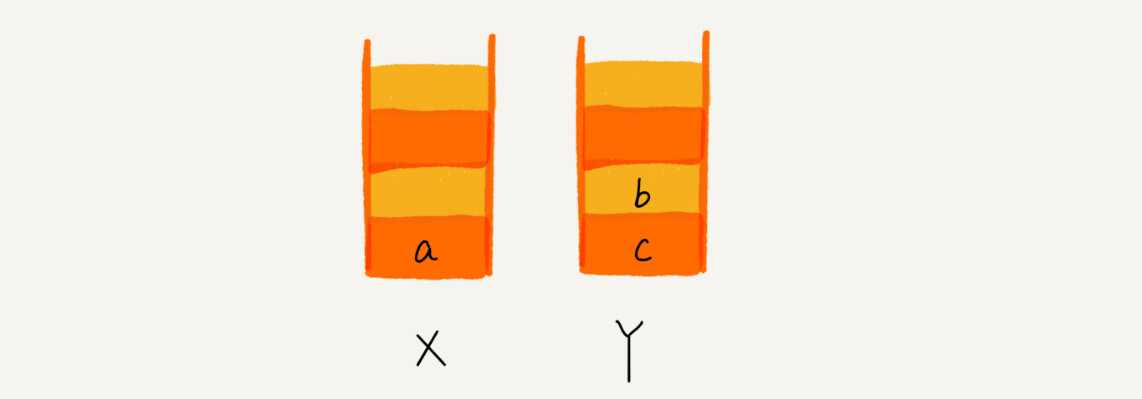
这个时候你又想看页面 b,于是你又点击前进按钮回到 b 页面,我们就把 b 再从栈 Y 中出栈,放入栈 X 中。此时两个栈的数据是这个样子:
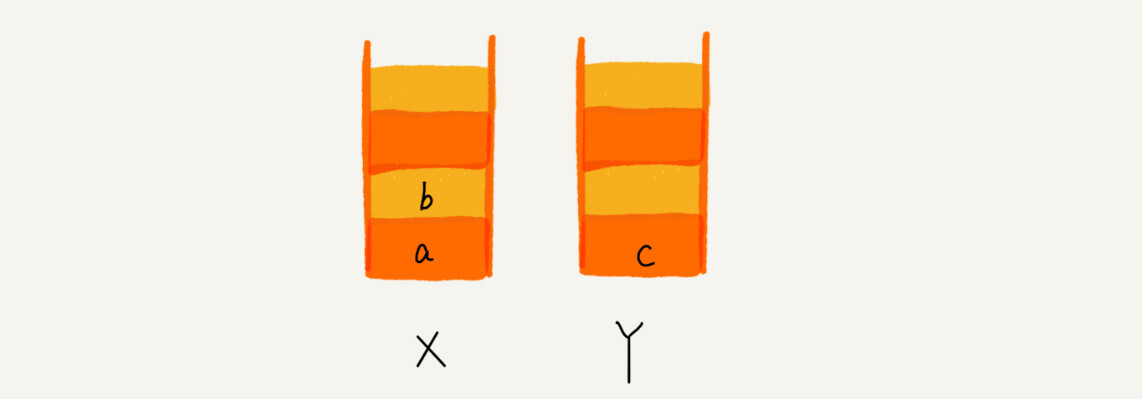
这个时候,你通过页面 b 又跳转到新的页面 d 了,页面 c 就无法再通过前进、后退按钮重复查看了,所以需要清空栈 Y。此时两个栈的数据这个样子:
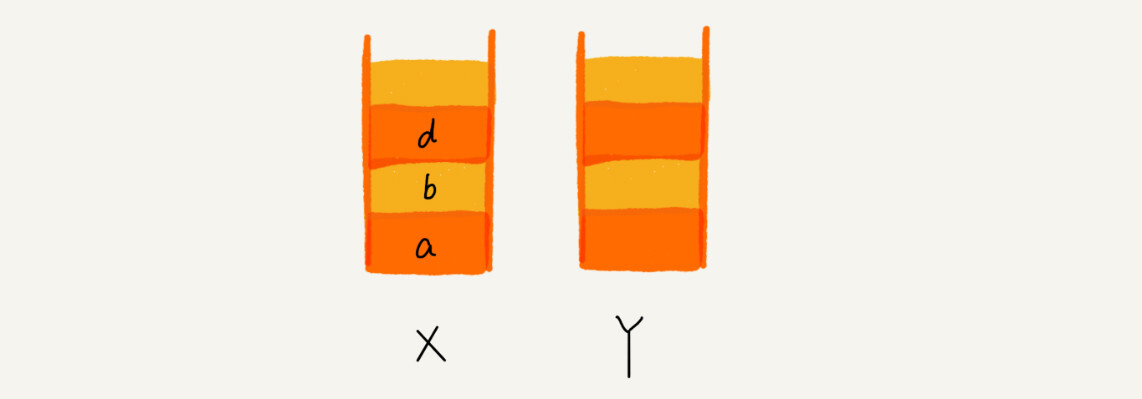
2. 函数调用栈
每个函数调用被封装成一个“栈帧”,每个“栈帧”就被放入栈中。
3. 表达式求值
为了方便解释,我将算术表达式简化为只包含加减乘除四则运算,比如:34+13*9+44-12/3。对于这个四则运算,我们人脑可以很快求解出答案,但是对于计算机来说,理解这个表达式本身就是个挺难的事儿。
实际上,编译器就是通过两个栈来实现的。其中一个保存操作数的栈,另一个是保存运算符的栈。我们从左向右遍历表达式,当遇到数字,我们就直接压入操作数栈;当遇到运算符,就与运算符栈的栈顶元素进行比较。
如果比运算符栈顶元素的优先级高,就将当前运算符压入栈;如果比运算符栈顶元素的优先级低或者相同,从运算符栈中取栈顶运算符,从操作数栈的栈顶取 2 个操作数,然后进行计算,再把计算完的结果压入操作数栈,继续比较。
我将 3+5*8-6 这个表达式的计算过程画成了一张图,你可以结合图来理解我刚讲的计算过程。
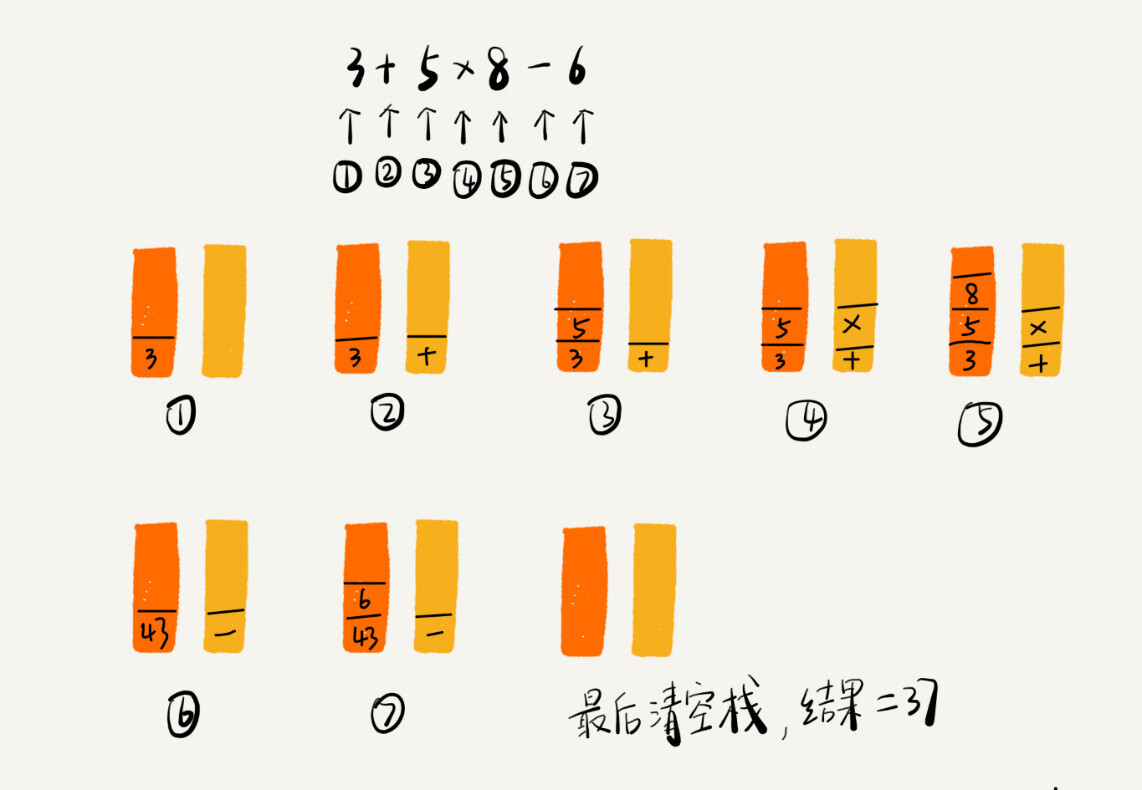
对于表达式求值,你也可以使用一些求值引擎来实现。比如在Java中,你就可以调用JS引擎来实现表达式的值。
ScriptEngine engine= new ScriptEngineManager().getEngineByName("Nashorn");
String js="var a=10;var b=20; var c=a+b;c;";
Double o= (Double) engine.eval(js);
System.out.println(o);
4. 括号匹配
假设表达式中只包含三种括号,圆括号 ()、方括号[]和花括号{},并且它们可以任意嵌套。比如,{[] ()[{}]}或[{()}([])]等都为合法格式,而{[}()]或[({)]为不合法的格式。那我现在给你一个包含三种括号的表达式字符串,如何检查它是否合法呢?
这里也可以用栈来解决。我们用栈来保存未匹配的左括号,从左到右依次扫描字符串。当扫描到左括号时,则将其压入栈中;当扫描到右括号时,从栈顶取出一个左括号。如果能够匹配,比如“(”跟“)”匹配,“[”跟“]”匹配,“{”跟“}”匹配,则继续扫描剩下的字符串。如果扫描的过程中,遇到不能配对的右括号,或者栈中没有数据,则说明为非法格式。
当所有的括号都扫描完成之后,如果栈为空,则说明字符串为合法格式;否则,说明有未匹配的左括号,为非法格式。
作者:程序员自由之路
出处:https://www.cnblogs.com/54chensongxia/p/14104304.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?