线性表结构:单向链表和循环链表
单向链表简介#
在底层结构上,单向链表通过指针将一组零散的内存块串联在一起。其中,我们把内存块称为链表的“结点”。为了将所有的结点串起来,每个链表的结点除了存储数据之外,还需要记录链上的下一个结点的地址。如下图所示,我们把这个记录下个结点地址的指针叫作后继指针 next。
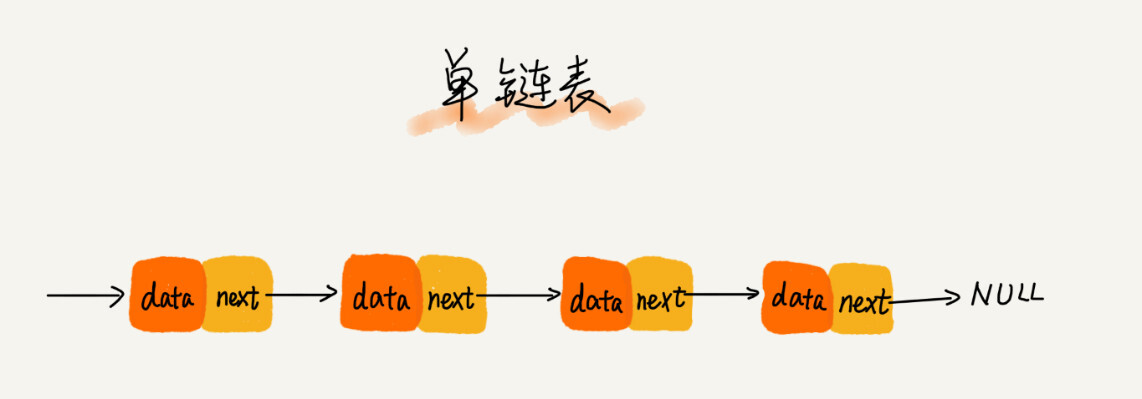
从画的单链表图中,你应该可以发现,其中有两个结点是比较特殊的,它们分别是第一个结点和最后一个结点。我们习惯性地把第一个结点叫作头结点,把最后一个结点叫作尾结点。其中,头结点用来记录链表的基地址。有了它,我们就可以遍历得到整条链表。而尾结点特殊的地方是:指针不是指向下一个结点,而是指向一个空地址 NULL,表示这是链表上最后一个结点。
单向链表的增删改查操作#
1. 插入操作
- 头部插入:时间复杂度O(1)
- 尾部插入:时间复杂度O(1)
- 指定位置后面插入:时间复杂度O(1)
- 指定位置前面插入:时间复杂度O(n)
2. 删除操作
删除操作的时间复杂度和插入操作的时间复杂度类似。
- 删除头部节点:时间复杂度O(1)
- 删除尾部节点:时间复杂度O(n),因为首先需要遍历链表,找到尾部节点的前一个节点(后面分析双向链表时发现就不会有这个问题)
- 删除指定节点:时间复杂度O(n)
- 删除值等于某个数的节点:时间复杂度O(n)
3. 更新操作
- 更新指定节点:时间复杂度O(1)
- 将链表中值等于某个具体值的节点更新:时间复杂度O(n)
4. 查询操作
- 时间复杂度:O(n)
由于链表的底层数据是不连续的,所以不能通过随机访问进行数据寻址。只能通过遍历进行查找数据。
单向链表的Java代码实现#
package com.csx.algorithm.link;
public class SinglyLinkedList<E> {
public static void main(String[] args) {
SinglyLinkedList<Integer> list = new SinglyLinkedList<>();
//尾部插入,遍历链表输出
System.out.println("尾部插入[1-10]");
for (int i = 1; i <= 10; i++) {
list.addLast(Integer.valueOf(i));
}
list.printList();
//头部插入,遍历链表输出
System.out.println("头部插入[1-10]");
for (int i = 1; i <= 10; i++) {
list.addFirst(Integer.valueOf(i));
}
list.printList();
//在指定节点后面插入
System.out.println("在头节点后面插入[100]");
list.addAfter(100, list.head);
list.printList();
System.out.println("在头节点前面插入[100]");
list.addBefore(100, list.head);
list.printList();
System.out.println("在尾节点前面插入[100]");
list.addBefore(100, list.tail);
list.printList();
System.out.println("在尾节点后面插入[100]");
list.addAfter(100, list.tail);
list.printList();
System.out.println("------------删除方法测试-----------");
System.out.println("删除头节点");
list.removeFirst();
list.printList();
System.out.println("删除尾节点");
list.removeLast();
list.printList();
System.out.println("删除指定节点");
list.removeNode(list.head.next);
list.printList();
}
private Node head;
private Node tail;
public SinglyLinkedList() {
}
public SinglyLinkedList(E data) {
Node node = new Node<>(data, null);
head = node;
tail = node;
}
public void printList() {
Node p = head;
while (p != null && p.next != null) {
System.out.print(p.data + "-->");
p = p.next;
}
if (p != null) {
System.out.println(p.data);
}
}
public void addFirst(E data) {
//允许节点值为空
//if(data==null){
// return;
//}
Node node = new Node(data, head);
head = node;
if (tail == null) {
tail = node;
}
}
public void addLast(E data) {
Node node = new Node(data, null);
if (tail == null) {
head = node;
tail = node;
} else {
tail.next = node;
tail = node;
}
}
/**
* @param data
* @param node node节点必须在链表中
*/
public void addAfter(E data, Node node) {
if (node == null) {
return;
}
Node newNode = new Node(data, node.next);
node.next = newNode;
if(tail==node){
tail = newNode;
}
}
/**
* @param data
* @param node node节点必须在链表中
*/
public void addBefore(E data, Node node) {
if (node == null) {
return;
}
Node p = head;
if (p == null) {
throw new RuntimeException("node not in LinkedList...");
}
if (p == node) {
Node newNode = new Node(data, node);
head = newNode;
return;
}
while (p.next != null) {
if (p.next == node) {
break;
}
p = p.next;
}
if (p.next == null) {
throw new RuntimeException("node not in LinkedList...");
}
Node newNode = new Node(data, node);
p.next = newNode;
}
public void removeFirst() {
if (head == null) {
return;
}
if (head == tail) {
head = null;
tail = null;
} else {
head = head.next;
}
}
public void removeLast() {
if (tail == null) {
return;
}
if (head == tail) {
head = null;
tail = null;
} else {
Node p = head;
while (p.next != tail) {
p = p.next;
}
p.next = null;
tail = p;
}
}
public void removeNode(Node node) {
if (node == null) {
return;
}
Node p = head;
if (p == null) {
return;
}
while (p.next != null && p.next != node) {
p = p.next;
}
if (p.next != null) {
p.next = node.next;
}
}
private static class Node<E> {
E data;
Node next;
public Node(E data, Node next) {
this.data = data;
this.next = next;
}
}
}
单向链表的JDK实现#
如果你使用高级编程语言,一般都会有现成的单向链表实现。比如你使用的是Java,其中的LinkedList就可以实现单向链表功能(虽然LinkedList底层是双向链表,但是双向链表可以实现单向链表的所有功能)。
有时候你可能只是想实现一个链表的结构,并不想暴露太多的操作API给用户。这时候使用LinkedList可能不太能满足你的需求,因为LinkedList除了链表相关的操作,还暴露了其他的一些接口,这样可能会给用户太多的操作权限。
其实这个问题也不是太大,我们是要做下适当的封装就行了。
package com.csx.algorithm.link;
import java.util.Collection;
import java.util.Collections;
import java.util.LinkedList;
import java.util.Set;
import java.util.function.Predicate;
public class SinglyLinkedList2<E> {
private LinkedList<E> list;
public SinglyLinkedList2() {
this.list = new LinkedList<>();
}
public SinglyLinkedList2(E data){
Set<E> singleton = Collections.singleton(data);
this.list = new LinkedList<>(singleton);
}
public SinglyLinkedList2(Collection<? extends E> c){
this.list = new LinkedList<>(c);
}
// ----------------------------------新增方法---------------------------------------
public void addFirst(E data){
list.addFirst(data);
}
public void addLast(E data){
list.addLast(data);
}
// 在链表末尾添加
public boolean add(E date){
return list.add(date);
}
public boolean addAll(Collection<? extends E> collection){
return list.addAll(collection);
}
public boolean addBefore(E data,E succ){
int i = list.indexOf(succ);
if(i<0){
return false;
}
list.add(i,data);
return true;
}
public boolean addAfter(E data,E succ){
int i = list.indexOf(succ);
if(i<0){
return false;
}
if((i+1)==list.size()){
list.addLast(data);
return true;
}else {
list.add(i+1,data);
return true;
}
}
// ---------------------------------- 删除方法---------------------------------------
// 删除方法,默认删除链表头部元素
public E remove(){
return list.remove();
}
// 删除方法,删除链表第一个元素
public E removeFirst(){
return list.removeFirst();
}
// 删除方法,删除链表最后一个元素
public E removeLast(){
return list.removeLast();
}
// 删除链表中第一次出现的元素,成功删除返回true
// 对象相等的标准是调用equals方法相等
public boolean remove(E data){
return list.remove(data);
}
// 逻辑和remove(E data)方法相同
public boolean removeFirstOccur(E data){
return list.removeFirstOccurrence(data);
}
// 因为LinkedList内部是双向链表,所以时间复杂度和removeFirstOccur相同
public boolean removeLastOccur(E data){
return list.removeLastOccurrence(data);
}
// 批量删除方法
public boolean removeAll(Collection<?> collection){
return list.removeAll(collection);
}
// 按照条件删除
public boolean re(Predicate<? super E> filter){
return list.removeIf(filter);
}
// ----------------------------- 查询方法----------------------------
// 查询链表头部元素
public E getFirst(){
return list.getFirst();
}
// 查询链表尾部元素
public E getLast(){
return list.getLast();
}
// 查询链表是否包含某个元素
// 支持null判断
// 相等的标准是data.equals(item)
public boolean contains(E data){
return list.contains(data);
}
public boolean containsAll(Collection<?> var){
return list.containsAll(var);
}
}
需要注意的是:虽然JDK中的LinkedList已经提供了非常方便的链表实现,但是这个类并不是线程安全的,如果你的代码需要保证线程安全的话,你需要额外做同步措施保证代码的线程安全。
循环链表#
循环链表是一种特殊的单链表。实际上,循环链表也很简单。它跟单链表唯一的区别就在尾结点。我们知道,单链表的尾结点指针指向空地址,表示这就是最后的结点了。而循环链表的尾结点指针是指向链表的头结点。从我画的循环链表图中,你应该可以看出来,它像一个环一样首尾相连,所以叫作“循环”链表。
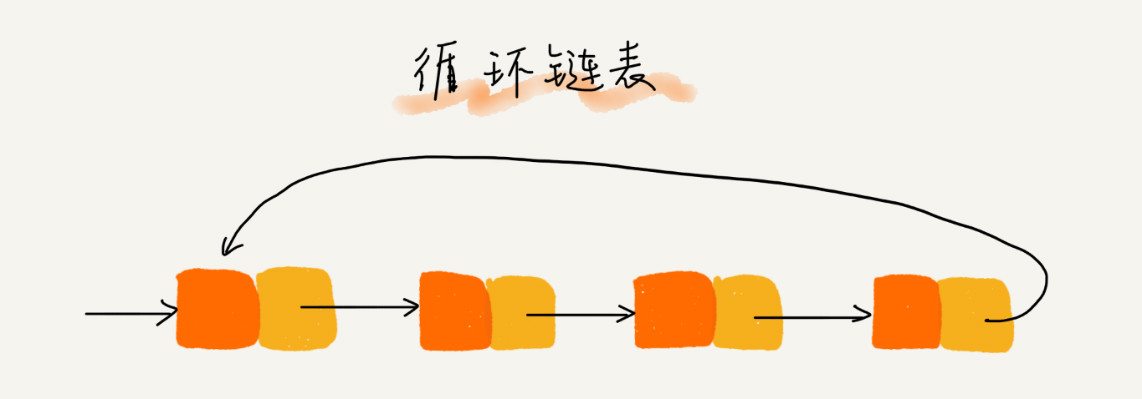
和单链表相比,循环链表的优点是从链尾到链头比较方便。当要处理的数据具有环型结构特点时,就特别适合采用循环链表。比如著名的约瑟夫问题。尽管用单链表也可以实现,但是用循环链表实现的话,代码就会简洁很多。
链表的使用场景#
实现 LRU 缓存淘汰算法#
因为双向链表、循环链表都能实现单链表的功能,所以这边举例的使用场景不仅仅是针对单链表的,使用其他链表也可以实现。
链表一个经典的链表应用场景就是 LRU 缓存淘汰算法。
缓存是一种提高数据读取性能的技术,在硬件设计、软件开发中都有着非常广泛的应用,比如常见的 CPU 缓存、数据库缓存、浏览器缓存等等。
缓存的大小有限,当缓存被用满时,哪些数据应该被清理出去,哪些数据应该被保留?这就需要缓存淘汰策略来决定。常见的策略有三种:先进先出策略 FIFO(First In,First Out)、最少使用策略 LFU(Least Frequently Used)、最近最少使用策略 LRU(Least Recently Used)。
使用单链表实现LRU算法的大致思路是:
维护一个有序单链表(链表长度有限),越靠近链表尾部的结点是越早之前访问的。当有一个新的数据被访问时,我们从链表头开始顺序遍历链表。
-
如果此数据之前已经被缓存在链表中了,我们遍历得到这个数据对应的结点,并将其从原来的位置删除,然后再插入到链表的头部。
-
如果此数据没有在缓存链表中,又可以分为两种情况:
- 如果此时缓存未满,则将此结点直接插入到链表的头部;
- 如果此时缓存已满,则链表尾结点删除,将新的数据结点插入链表的头部。
实现上面算法的时间复杂度是O(n)。
除了基于链表的实现思路,实际上还可以用数组来实现 LRU 缓存淘汰策略。思路和上面的类似。
反转链表#
有序链表合并#
作者:程序员自由之路
出处:https://www.cnblogs.com/54chensongxia/p/14058092.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?