ThreadLocalRandom——Random在大并发环境下的替代者
本博客系列是学习并发编程过程中的记录总结。由于文章比较多,写的时间也比较散,所以我整理了个目录贴(传送门),方便查阅。
随机数
随机数在科学研究与工程实际中有着极其重要的应用!
简单来说,随机数就是一个数列,这个数列可能满足一定的概率分布,又获取其满足的分布并不为我们所知。
数学方法产生随机数应该称之为“伪随机数”,只有使用物理方法才能得到真正的随机数!因此我们使用计算机产生的随机数都是"伪随机数"。那么计算机到底是怎么产生随机数的呢?这时就要提到随机数发生器了。
随机数发生器
我们高中的时候都学过数列的知识,上面提到随机数可以看成是一个数列,那么我们可以将随机数发生器看成是一个数列表达式。比如现在有下面两个随机说发生器
//发生器1
X(n+1)= a * X(n) + b
//发生器2
X(n+1)= a * X(n)
当然还有很多随机数发生器,现实生产中使用的发生器也并不是像上面的那么简单,这边只是为了说明随机数发生器到底是什么列了两个例子。
随机数种子
我们在产生随机数的时候经常会听到随机数种子这个名词,那随机数种子到底是什么?我们还是以上面的发生器为例。
//发生器1
X(n+1)= a * X(n) + b
显然通过上式我们能够得到一个数列,前提是X(0)应该给出,依次我们就可以算出X(1),X(2)...;当然不同的X(0)就会得到不同的数列。
可以说X(0)的值就是随机数的种子,只要这个种子给的一样,产生的随机数序列就是一样的。下面给出一个使用Java中��Random产生随机数的列子证明下这个说法。
Random random1 = new Random(100);
for (int i = 0; i < 10 ; i++) {
System.out.println(random1.nextInt(5));
}
System.out.println("-------------");
Random random2 = new Random(100);
for (int i = 0; i < 10 ; i++) {
System.out.println(random2.nextInt(5));
}
执行结果如下:
0
0
4
3
1
1
1
3
3
3
-------------
0
0
4
3
1
1
1
3
3
3
--------------
上面代码中新建了两个随机数发生器,都设置了同样的随机数种子100,产生10个随机数。从上面的结果中可以看出两个发生器产生的序列是一样的。
对于一个应用级的伪随机数发生器,所有的“伪随机数”,均匀的分布于一个“轨道”上,几乎所有的数都可以做为种子。数字“0”,有时是一个特例,不能作为种子,当然它取决于你使用的随机数发生器!
Random类的局限性
Random类是JDK提供的一个随机数发生器。 我们看下Random类中nextInt方法的源代码:
public int nextInt(int bound) {
if (bound <= 0)
throw new IllegalArgumentException(BadBound);
//关键代码点,这边会根据老的随机数种子生成新的随机数种子,然后会根据新生成的随机数种子生成随机数
int r = next(31);
int m = bound - 1;
if ((bound & m) == 0) // i.e., bound is a power of 2
r = (int)((bound * (long)r) >> 31);
else {
for (int u = r;
u - (r = u % bound) + m < 0;
u = next(31))
;
}
return r;
}
那我们看下上面的next方法到底是怎样生成新的随机数种子的。
protected int next(int bits) {
long oldseed, nextseed;
AtomicLong seed = this.seed;
do {
oldseed = seed.get();
//根据旧值计算新的种子
nextseed = (oldseed * multiplier + addend) & mask;
} while (!seed.compareAndSet(oldseed, nextseed));
return (int)(nextseed >>> (48 - bits));
}
上面代码中,首先获取当前原子变量种子的值,然后根据当前种子值计算新的种子。再然后使用CAS机制更新种子的值,保证多线程竞争的情况下只有一个能更新成功。最后使用固定算法根据新的种子计算随机数。
每个Random实例里面都有一个原子性的种子变量用来记录当前的种子值,当要生成新的随机数时需要根据当前种子计算新的种子并更新回原子变量。在多线程下使用单个Random实例生成随机数时,当多个线程同时计算随机数来计算新的种子时,多个线程会竞争同一个原子变量的更新操作,由于原子变量的更新是CAS操作,同时只有一个线程会成功,所以会造成大量线程进行自旋重试,这会降低并发性能。
分析到这里我们可以看出Random的局限性并不是线程安全的问题,而是在大量线程并发的时候,通过CAS机制更新随机数种子会导致大量线程自旋,耗费CPU性能,导致系统吞吐量下降。
ThreadLocalRandom
ThreadLocalRandom类是JDK 7在JUC包下新增的随机数生成器,它弥补了Random类在多线程下的缺陷。下面来分析下ThreadLocalRandom的实现原理。
从名字上看它会让我们联想到ThreadLocal。ThreadLocal通过让每一个线程复制一份变量,使得在每个线程对变量进行操作时实际是操作自己本地内存里面的副本,从而避免了对共享变量进行同步。
实际上ThreadLocalRandom的实现也是这个原理,Random的缺点是多个线程会使用同一个原子性种子变量,从而导致对原子变量更新的竞争。

那么,如果每个线程都维护一个种子变量,则每个线程生成随机数时都根据自己老的种子计算新的种子,并使用新种子更新老的种子,再根据新种子计算随机数,就不会存在竞争问题了,这会大大提高并发性能。
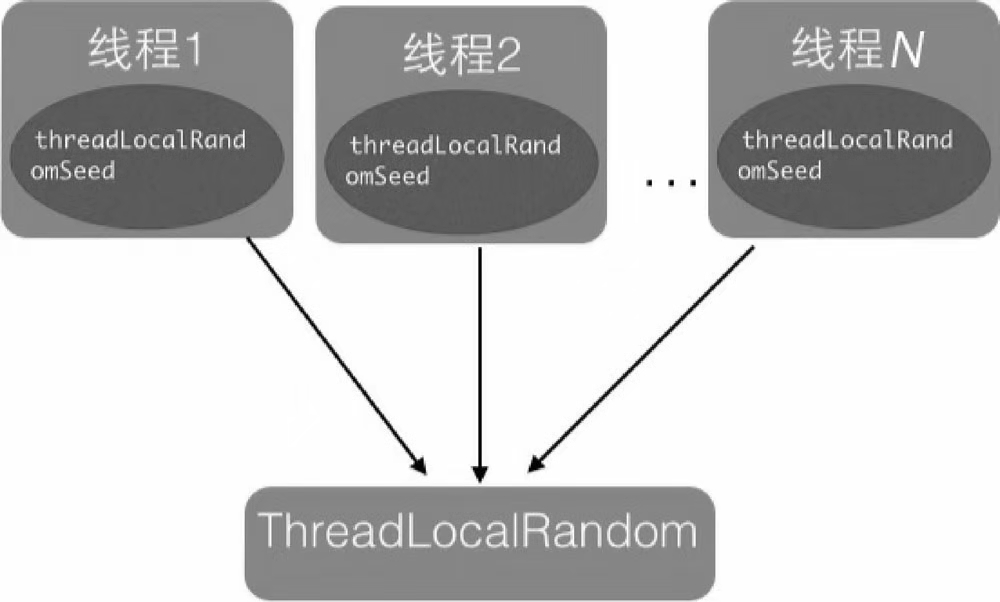
ThreadLocalRandom提升性能的原理就是这样的。具体的源代码也比较简单,这边就不贴代码了。感兴趣的可以自己看下。下面贴下ThreadLocalRandom的简单使用方法
ThreadLocalRandom random = ThreadLocalRandom.current();
random.nextInt();
参考
- 《Java并发编程之美》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号