最简单的 Java内存模型讲解
本博客系列是学习并发编程过程中的记录总结。由于文章比较多,写的时间也比较散,所以我整理了个目录贴(传送门),方便查阅。
前言
在并发编程中,需要处理两个关键问题:线程之间如何通信及线程之间如何同步(这里的线程是指并发执行的活动实体)。通信是指线程之间以何种机制来交换信息。在命令式编程中,线程之间的通信机制有两种:共享内存和消息传递。
在共享内存的并发模型里,线程之间共享程序的公共状态,通过写-读内存中的公共状态进行隐式通信。在消息传递的并发模型里,线程之间没有公共状态,线程之间必须通过发送消息来显式进行通信。
同步是指程序中用于控制不同线程间操作发生相对顺序的机制。在共享内存并发模型里,同步是显式进行的。程序员必须显式指定某个方法或某段代码需要在线程之间互斥执行。在消息传递的并发模型里,由于消息的发送必须在消息的接收之前,因此同步是隐式进行的。
Java的并发采用的是共享内存模型,Java线程之间的通信总是隐式进行,整个通信过程对程序员完全透明。如果编写多线程程序的Java程序员不理解隐式进行的线程之间通信的工作机制,很可能会遇到各种奇怪的内存可见性问题。
JMM(Java内存模型)就是来解决这些问题的。
在网上看了很多文章,也看了好几本书中关于JMM的介绍,我发现JMM确实是Java中比较难以理解的概念。网上很多文章中关于JMM的介绍要么是照搬了一些书上的内容,要么就干脆介绍的就是错的。本文试着用比较简洁的语言介绍清楚JMM到底是什么,解决了Java编程中的哪些问题。不求深入,但求让读者看地清楚,看完之后能对JMM有个比较直观的认识。
本文是笔者在总结了网上的多篇文章之后加上自己的理解整理出来的,内容上可能和JMM标准存在偏差,有问题还望留言指出。
什么是JMM
JMM是一个规范,我从JSR133标准(贴心的我也准备了中文版)中摘录了一段对JMM的简单介绍:
JavaTM virtual machines support multiple threads of execution. Threads are represented by the
Thread class. The only way for a user to create a thread is to create an object of this class; each
thread is associated with such an object. A thread will start when the start() method is invoked
on the corresponding Thread object.
The behavior of threads, particularly when not correctly synchronized, can be confusing and
counterintuitive. This specification describes the semantics of multithreaded programs written in
the JavaTM programming language; it includes rules for which values may be seen by a read of
shared memory that is updated by multiple threads. As the specification is similar to the memory
models for different hardware architectures, these semantics are referred to as the JavaTM memory
model.
These semantics do not describe how a multithreaded program should be executed. Rather,
they describe the behaviors that multithreaded programs are allowed to exhibit. Any execution
strategy that generates only allowed behaviors is an acceptable execution strategy.
上面的英文简要翻译如下:
Java虚拟机支持多线程执行。在Java中
Thread类代表线程,创建一个线程的唯一方法就是创建一个Thread类的实例对象。当调用了对象的start方法后,相应的线程将会执行。线程的行为有时会令人困惑而且和我们的直觉相左,特别是在线程没有正确同步的情况下。本规范描述了JVM平台上多线程程序的语义(含义),具体包括一个线程对共享变量的写入何时能被其他线程“看到”。由于本规范和不同硬件平台上的内存模型相似,所以将本规范命名为Java内存模型。
从上面这段英文介绍中我们可以得到关于JMM的简要信息:
- JMM是一个和多线程相关的规范;
- JMM描述了JVM平台上多线程程序的语义(含义),具体包括一个线程对共享变量的写入何时能被其他线程“看到”。
但是只看上面对于JMM的简单解释,我相信大多数人还是会很晕,对JMM具体是什么还是很模糊。
不过我在上面的这段介绍中又发现了一段对JMM介绍的关键信息:
As the specification is similar to the memory models for different hardware architectures, these semantics are referred to as the JavaTM memory model. (JMM和硬件平台上的内存模型相似)
上面的介绍中提到JMM和硬件平台上的内存模型相似,那么我们就先看看硬件平台上的内存模型究竟是什么?
内存模型
有点计算机基础的同学都应该知道,程序执行的时候其实就是一条条指令在CPU上执行的过程,而指令的执行又势必会涉及到数据的读取和写入。说到数据,就又不得不提到一个重要的硬件:内存。在计算机中,内存是数据的“收集站”,数据从键盘、网络、文件也有可能是一些传感器设备进入到内存,然后CPU从内存中读取这些数据并对这些数据进行“加工”后再写回到内存。
上面整个过程看起来很完美,但是就像人与人之间是有差别的一样,硬件和硬件之间也存在差别。CPU的运行速度就和尤塞恩·博尔特的速度一样(飞一样的速度),而内存的运行速度和CPU相比就像我的跑步速度和博尔特比一样,根本不是一个数量级的。CPU和内存运行速度的差距会导致整个系统性能的下降,因为CPU每次读写数据都要等待内存。(木桶理论在计算机中的体现)
但是这个问题根本就难不倒我们伟大的硬件工程师们。“聪明”的工程师们在CPU中加入了一层CPU高速缓存层。这个缓存的运算速度和CPU相当,当指令在CPU上运行的时候,会先将运算需要的数据从内存中复制一份到CPU的高速缓存当中,那么CPU进行计算时就可以直接从它的高速缓存读取数据和向其中写入数据,当运算结束之后,再将高速缓存中的数据刷新到主存当中。(现代CPU其实是有多级缓存的,但是为了简单起见就没介绍了,因为我觉得这里不介绍CPU多级缓存不会影响对JMM的理解)
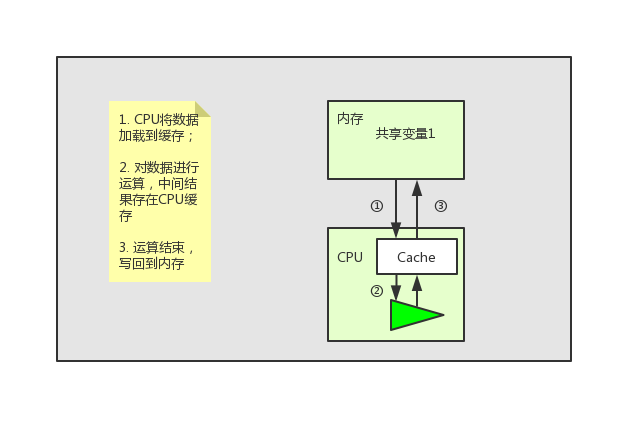
世界好像又重归于平静,一切又显得那么美好。但是其实问题才刚刚开始。
原子性问题
上面提到CPU进行运算时需要将共享变量先加载到CPU缓存中,运算结束后再将最新数据写回共享内存。这种看起来完美的工作方式其实存在一个问题,下面我们就以上面的图片为列子,说下这个问题。
假如现在系统环境是 单核CPU+多线程工作模式,共享变量初始值是1,线程1和线程2分别对这个共享变量进行加一操作,理论上这个共享变量最后的值是3。我们看看程序的执行行为是否会和我们预期的一致。
线程对一个共享变量加一的过程需要分三步进行:
step1: read共享变量到工作内存
step2:对共享变量+1
step3:将共享变量写回主内存
但是上面的三个步骤并不是原子操作,也就是说可能会被打断。现在假如线程1已经执行完了step1,但是这时CPU时间片用完了,线程2获得执行机会也从内存中加载共享变量的值(此时共享变量的值还是1),最后两个线程执行完step2和step3之后共享变量的值是2,并不是3。
出现上面问题的原因就是对共享变量的加一操作并不是原子性操作,所谓原子性操作是指一个或多个操作,要么全部执行且在执行过程中不被任何因素打断,要么全部不执行。在多线程环境下原子性问题可能会造成错误的执行结果。
原子性问题是内存模型存在的第一个问题,但是内存模型存在的问题不止这一个。
缓存一致性问题
随着科技的进步,对CPU的需求越来越高。但是摩尔定律的失效注定单个CPU的性能已经很难再大幅度提升。此时“聪明”的硬件工程师又出场了,他们创造性地将多个CPU集成到一个上,这样CPU的性能不就能成倍地增长了么。多核CPU的确带来了CPU性能的提升,但是这却“害苦”了软件工程师,因为多核CPU大大提升了多线程编程的难度。
多核CPU进行多线程编程时存在的一个显著问题就是缓存一致性问题。
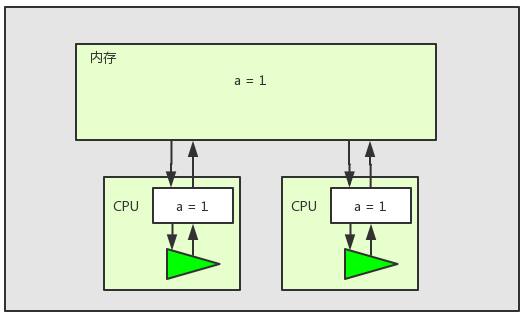
以上图为例,在多核CPU多线程环境下,两个线程对共享变量a进行加1操作。两个线程都将共享变量a在内存中的值加载到了工作内存中,如上图所示。但是此时线程2失去了CPU时间片,而线程1还是继续执行并成功将变量加一。当线程1执行完之后,内存中的值如下图所示:
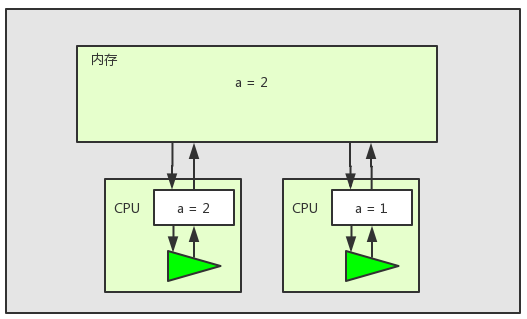
我们发现此时线程2中的变量a的值已经是过期的值,并不是变量a最新的值,所以当线程2执行完之后变量a并不是我们想要的值3。这个问题就是多核CPU中缓存一致性问题。
和上面的原子性问题不同,缓存一致性问题只有在多核多线程环境下才会出现,而原子性问题只要是在多线程环境下都可能会出现。
指令重排序问题
所谓的指令重拍是指CPU为了是内部的处理器单元得到充分的应用,可能会对代码进行乱序执行的行为。这个指令重拍的行为在单线程环境下不会有任何问题,但是在多线程环境下程序就可能出现错误的执行结果。
这边不准备对指令重排进行深入的讨论,大家只要知道指令重排序是一种CPU性能优化的行为,而这个行为在多线程环境下可能会导致程序错误的执行结果。下边举一个简单的列子说明这个问题:
class Singleton{
private static Singleton instance = null;
private Singleton() {
}
public static Singleton getInstance() {
if(instance==null) { // 1
synchronized (Singleton.class) {
if(instance==null)
instance = new Singleton(); //2
}
}
return instance;
}
}
上面的代码是一段实现单列模式的代码。代码中的Instance变量没有用volatile关键字修饰的,会导致这样一个问题:在线程执行到第1行的时候,代码读取到instance不为null时,但是instance引用的对象有可能还没有完成初始化。
造成这种现象主要的原因是重排序。
2处的代码可以分解成以下几步
emory = allocate(); // 1:分配对象的内存空间
ctorInstance(memory); // 2:初始化对象
instance = memory; // 3:设置instance指向刚分配的内存地址
上面的第2和第3步之间,可能会被重排序。例如:
memory = allocate(); // 1:分配对象的内存空间
instance = memory; // 3:设置instance指向刚分配的内存地址
// 注意,此时对象还没有被初始化!
ctorInstance(memory); // 2:初始化对象
此时程序判断到instance变量是非空的,但是还没初始化完成。如果立即使用的话会出现“致命”的问题。
通过上面分析我们看到:随着CPU性能的不断提升,随之出现了原子性问题、缓存一致性问题和指令重排序问题。细心的我们会发现这些问题其实是和多线程环境下共享变量访问的原子性、可见性和有序性问题一一对应的。
内存模型的作用
为了既保证CPU的高效执行,又保证共享内存读写的正确性(原子性、可见性和有序性),人们定义了内存模型。内存模型是一个规范,这个规范能保证共享内存读写的正确性。
Java内存模型
上面提到内存模型的出现是为了解决共享变量读写的原子性、可见性和有序性问题,但是没有具体讲怎么解决的。下面就来看看在Java中的内存模型JMM。
Java内存模型是内存模型在JVM中的体现。这个模型的主要目标是定义程序中各个共享变量的访问规则,也就是在虚拟机中将变量存储到内存以及从内存中取出变量这类的底层细节。通过这些规则来规范对内存的读写操作,保证了并发场景下的可见性、原子性和有序性。
Java内存模型规定了所有的变量(此处的变量(Variables)与Java编程中所说的变量有所区别,它包括了实例字段、静态字段和构成数组对象的元素,但是不包括局部变量与方法参数)都存储在主内存中(此处的主内存与介绍物理硬件时提到的主内存名字一样,两者也可以类比,但物理上它仅是虚拟机内存的一部分),每条线程还有自己的工作内存(可与前面讲的处理器高速缓存类比),线程的工作内存中保存了该线程中是用到的变量的主内存副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量的传递均需要自己的工作内存和主存之间进行数据同步进行。
而JMM就作用于工作内存和主存之间数据同步过程。他规定了如何做数据同步以及什么时候做数据同步。也就是说Java线程之间的通信由Java内存模型控制, JMM决定一个线程对共享变量的写入何时对另一个线程可见。

以下是《并发编程的艺术》中对JMM的定义。
PS:Java线程之间的通信由Java内存模型(本文简称为JMM)控制,JMM决定一个线程对共享变量的写入何时对另一个线程可见。从抽象的角度来看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory),本地内存中存储了该线程以读/写共享变量的副本。本地内存是JMM的一个抽象概念,并不真实存在。它涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化。
内存间交互操作
关于主内存与工作内存之间具体的交互协议,即一个变量如何从主内存拷贝到工作内存、如何从工作内存同步回主内存这一类的实现细节,Java内存模型中定义了以下8种操作来完成。Java虚拟机实现时必须保证下面提及的每一种操作都是原子的、不可再分的。
- lock(锁定):作用于主内存的变量,它把一个变量标识为一条线程独占的状态。
- unlock(解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
- read(读取):作用于主内存的变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用。
- load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。
- use(使用):作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。
- assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收的值赋给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
- store(存储):作用于工作内存的变量,它把工作内存中一个变量的值传送到主内存中,以便随后的write操作使用。
- write(写入):作用于主内存的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中。
如果要把一个变量从主内存拷贝到工作内存,那就要按顺序执行read和load操作,如果要把变量从工作内存同步回主内存,就要按顺序执行store和write操作。注意,Java内存模型只要求上述两个操作必须按顺序执行,但不要求是连续执行。也就是说read与load之间、store与write之间是可插入其他指令的,如对主内存中的变量a、b进行访问时,一种可能出现的顺序是read a、read b、load b、load a。除此之外,Java内存模型还规定了在执行上述8种基本操作时必须满足如下规则:
- 不允许read和load、store和write操作之一单独出现,即不允许一个变量从主内存读取了但工作内存不接受,或者工作内存发起回写了但主内存不接受的情况出现。
- 不允许一个线程丢弃它最近的assign操作,即变量在工作内存中改变了之后必须把该变化同步回主内存。
- 不允许一个线程无原因地(没有发生过任何assign操作)把数据从线程的工作内存同步回主内存中。
- 一个新的变量只能在主内存中“诞生”,不允许在工作内存中直接使用一个未被初始化(load或assign)的变量,换句话说就是对一个变量实施use、store操作之前,必须先执行assign和load操作。
- 一个变量在同一个时刻只允许一条线程对其进行lock操作,但lock操作可以被同一条线程重复执行多次,多次执行lock后,只有执行相同次数的unlock操作,变量才会被解锁。
- 如果对一个变量执行lock操作,那将会清空工作内存中此变量的值,在执行引擎使用这个变量前,需要重新执行load或assign操作以初始化变量的值。
- 如果一个变量事先没有被lock操作锁定,那就不允许对它执行unlock操作,也不允许去unlock一个被其他线程锁定的变量。
- 对一个变量执行unlock操作之前,必须先把此变量同步回主内存中(执行store、write操作)。
大家发现,上面的定义相当繁琐,实践起来也很复杂。后来Java设计团队大概也意识到了这个问题,将Java内存模型的操作简化为read、write、lock和unlock四种,但这只是语言描述上的等价化简,Java内存模型的基础设计并未改变。
简单总结
Java的多线程之间是通过共享内存进行通信的,而由于采用共享内存进行通信,在通信过程中会存在一系列如原子性、可见性和有序性的问题。JMM就是为了解决这些问题而出现的,这个模型建立了一些规范,来屏蔽各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的内存访问效果,以保证在多核CPU多线程编程环境下,对共享变量读写的原子性、可见性和有序性。
再简单点说 JMM就是一个为了解决多核CPU多线程编程环境下对共享变量访问存在原子性、可见性和有序性问题 的规范。
本篇博客只是简单讲了下JMM的概念,以及解决哪些问题。具体JMM怎么解决原子性、可见性和有序性问题的,后续会写博客分析。

