数据结构:树和二叉树简介
本博客记录下关于树和二叉树的基本概念。
本文主要转载自:二叉树-你可能需要知道这些
1. 什么是树#
树是一种非线性的数据结构,是由n(n >=0)个结点组成的有限集合。
如果n==0,树为空树。
如果n>0,
树有一个特定的结点,根结点。根结点只有直接后继,没有直接前驱。
除根结点以外的其他结点划分为m(m>=0)个互不相交的有限集合,T0,T1,T2,...,Tm-1,每个结合是一棵树,称为根结点的子树。

2. 二叉树#
对于树这种数据结构,使用最频繁的是二叉树这种数据结构。
2.1 什么是二叉树#
每个节点最多只有2个子节点的树叫做二叉树。
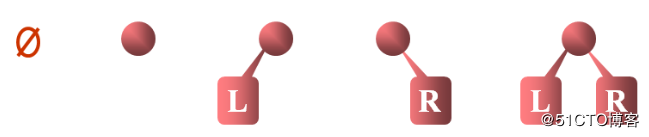
2.2 二叉树的一些特性#
A、在二叉树的第i层上最多有2^(i-1)个结点(i>=1)。
B、高度为k的二叉树,最多有2^k-1个结点(k>=0)。
C、对任何一棵二叉树,如果其叶结点有n个,度为2的非叶子结点有m个,则n = m + 1。
D、具有n个结点的完全二叉树的高度为logn + 1
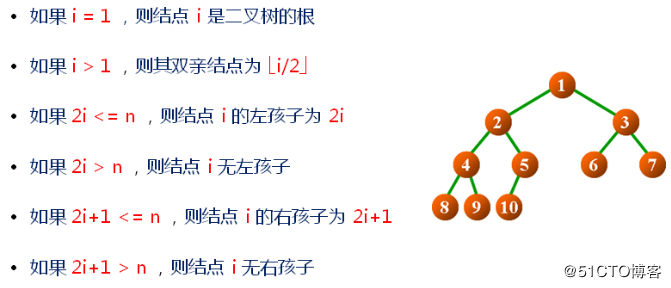
E、对于有n个结点的完全二叉树,按层次对结点进行编号(从上到下,从左到右),对于任意编号为i的结点:
2.3 二叉树的存储实现#
// 节点
public class BinaryNode {
// 存放的信息
Object data;
// 左儿子
BinaryNode left;
// 右儿子
BinaryNode right;
}
2.4 二叉树的遍历#
遍历是对树的一种最基本的运算,所谓遍历二叉树,就是按一定的规则和顺序走遍二叉树的所有结点,使每一个结点都被访问一次,而且只被访问一次。由于二叉树是非线性结构,因此,树的遍历实质上是将二叉树的各个结点转换成为一个线性序列来表示。
对于树的遍历,按照访问根节点的次序不同,主要有以下三种遍历算法:
- 先序遍历
- 后序遍历
- 中序遍历
除了上面最基本的三种遍历方式外,二叉树还有深度优先遍历和广度优先遍历。
我们首先给出一个假设:
L:左子树
D:根
R:右子树
2.4.1 先序遍历(DLR)#
先序遍历:根节点->左子树->右子树
public static void DLR(BinaryNode node) {
// 访问根节点
System.out.print(node.data + " ");
// 遍历左子树
if (node.left != null) {
DLR(node.left);
}
// 遍历右子树
if (node.right != null) {
DLR(node.right);
}
}
2.4.2 后序遍历(LRD)#
后序遍历:左子树->右子树->根节点
public static void LRD(BinaryNode node) {
// 遍历左子树
if (node.left != null) {
LRD(node.left);
}
// 遍历右子树
if (node.right != null) {
LRD(node.right);
}
// 访问根节点
System.out.print(node.data + " ");
}
2.4.3 中序遍历(LDR)#
中序遍历:左子树->根节点->右子树
// 遍历左子树
if (node.left != null) {
LDR(node.left);
}
// 访问根节点
System.out.print(node.data + "");
// 遍历右子树
if (node.right != null) {
LDR(node.right);
}
2.4.4 深度优先遍历#
英文缩写为DFS即Depth First Search.其过程简要来说是对每一个可能的分支路径深入到不能再深入为止,而且每个节点只能访问一次。
深度优先遍历需要使用到栈这种数据结构,栈具有先进后出的特点。

如上图,我们来分析下深度优先遍历的过程。
- 首先根节点A入栈,stack(A)。
- 将A节点弹出,因为A存在 B C两个子节点,根据定义和栈特点,首先将C(右儿子)压入栈中,然后将B(左儿子)压入栈中,stack(C B)
- 弹出栈顶元素B节点弹出,将节点 E 和 D压入栈中,stack(C E D)。
- 弹出栈顶元素D,由于节点D只存在一个子节点H,因此H直接入栈,stack(C E H).
- 弹出栈顶元素H,元素H不存在子元素,stack(C E).
- 弹出栈顶元素E,元素E不存在子元素,stack(C).
- 弹出栈顶元素C,子节点G F分别入栈,stack(G F).
- F出栈,stack(G)。
- G出栈,stack()。
- 遍历结束。
深度优先遍历的结果为: A B D H E C F G.
通过上面的分析,是不是觉得深度优先遍历其实也没那么难啊,下面我们来动手实现这段代码(过程理解清楚了,代码实现起来很简单)。
private void depthFirst(AVLTreeNode<T> node) {
if (node == null) {
return;
}
Stack<AVLTreeNode> stack = new Stack<>();
// 根节点入栈,然后进行后续操作
stack.push(node);
while (!stack.isEmpty()) {
AVLTreeNode root = stack.pop();
// 弹出栈顶元素,进行访问。
System.out.println(root.key + " ");
// 首先将右节点入栈
if (root.right != null) {
stack.push(node.right);
}
// 然后左节点入栈
if (root.left != null) {
stack.push(node.left);
}
}
}
2.4.5 广度优先遍历#
英文缩写为BFS即Breadth FirstSearch。其过程检验来说是对每一层节点依次访问,访问完一层进入下一层,而且每个节点只能访问一次。对于上面的例子来说,广度优先遍历的 结果是:A,B,C,D,E,F,G,H(假设每层节点从左到右访问)。
广度优先遍历需要使用到队列这种数据结构,队列具有先进先出的特点。
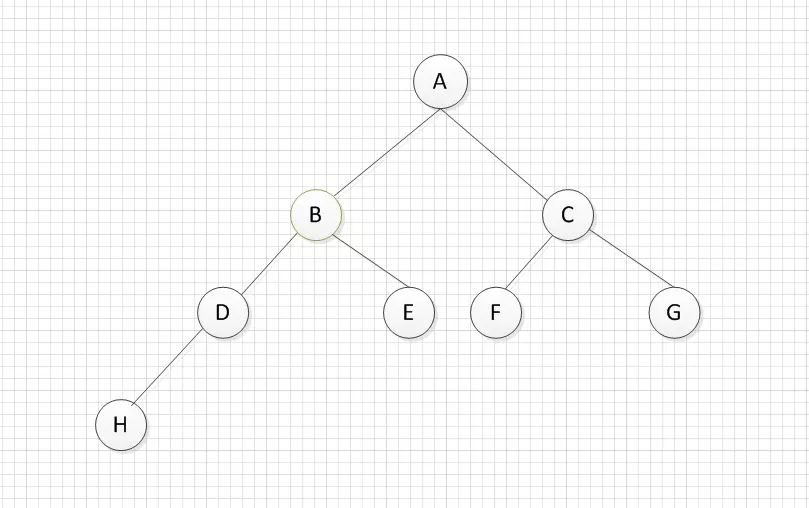
如上图所示,我们来分析广度优先遍历的过程。
首先将A节点插入队列中,queue(A);
将A节点弹出,同时将A的子节点B,C插入队列中,此时B在队列首,C在队列尾部,queue(B,C);
将B节点弹出,同时将B的子节点D,E插入队列中,此时C在队列首,E在队列尾部,queue(C,D,E);
将C节点弹出,同时将C的子节点F,G插入队列中,此时D在队列首,G在队列尾部,queue(D,E,F,G);
将D节点弹出,同时将D节点的子节点H插入队列中,此时E在队列首,H在队列尾部,queue(E,F,G,H);
E F G H分别弹出(这四个节点均不存在子节点)。
广度优先遍历结果为:A B C D E F G H
动手来实现广度优先遍历,代码如下:
public void breadthFirst() {
breadthFirst(root);
}
private void breadthFirst(AVLTreeNode<T> node) {
if (node == null) {
return;
}
Queue<AVLTreeNode> queue = new ArrayDeque<>();
// 根节点入栈
queue.add(node);
while (!queue.isEmpty()) {
AVLTreeNode root = queue.poll();
System.out.print(node.key + " ");
if (root.left != null) {
queue.add(node.left);
}
if (root.right != null) {
queue.add(node.right);
}
}
}
2.5 完全二叉树#
定义:若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。
完全二叉树有如下特点:
- 只允许最后一层有空缺结点且空缺在右边,即叶子结点只能在层次最大的两层上出现。
- 对任一结点,如果其右子树的深度为j,则其左子树的深度必为j或j+1。 即度为1的点只有1个或0个。
2.6 满二叉树#
除最后一层无任何子节点外,每一层上的所有结点都有两个子结点二叉树。
国内教程定义:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且结点总数是(2^k) -1 ,则它就是满二叉树。
满二叉树是一种特殊的完全二叉树。
二叉树的顺序存储,寻找后代节点和祖先节点都非常方便,但对于普通的二叉树,顺序存储浪费大量的存储空间,同样也不利于节点的插入和删除。因此顺序存储一般用于存储完全二叉树。
链式存储相对顺序存储节省存储空间,插入删除节点时只需修改指针,但寻找指定节点时很不方便。不过普通的二叉树一般是用链式存储结构。
作者:程序员自由之路
出处:https://www.cnblogs.com/54chensongxia/p/11567515.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?