数据结构:Hash表
Hash表也叫散列表,是一种线性数据结构。在一般情况下,可以用o(1)的时间复杂度进行数据的增删改查。在Java开发语言中,HashMap的底层就是一个散列表。
1. 什么是Hash表#
Hash表是一种线性数据结构,这种数据结构的底层一般是通过数组来实现的。在进行数据增删改查的时候,Hash表首先通过Hash函数对某个键值进行Hash操作,这个Hash操作会将这个键映射到数组的某个下标,获得下标以后就可以直接对数组中的数据进行操作了。理论上讲,Hash表数据操作的时间复杂度都是O(1)。
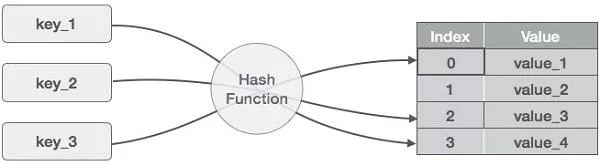
Hash表的底层是通过数组实现的。数据有个特点就是:必须在初始化的时候指定其长度。所以当Hash表中的数据填满之后想继续向里面放数据的话就必须再创建一个容量更大的数组,然后将之前数组中的数组copy到这个新数组中。这个过程是一个耗费性能的操作,因此我们在使用Hash表之前最好估算下数据的容量,尽量避免扩容操作。
2. Hash函数#
哈希函数又称为散列函数,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。假设输出值域为S,哈希函数的性质如下:
-
典型的哈希函数都有无限的输入值域;
-
当哈希函数输入一致时,输出必相同;
-
当哈希函数传入不同的输入值时,返回值可能一样,也可能不一样;
-
对于不同的输入所得的输出值会均匀的分布;
另外,Hash函数还具有如下两个性质:
-
免碰撞:即不会出现输入 x≠y ,但是H(x)=H(y) 的情况,其实这个特点在理论上并不成立,比如目前比特币使用的 SHA256 算法,会有2256种输出,如果我们进行2256 + 1 次输入,那么必然会产生一次碰撞,事实上,通过 理论证明 ,通过2^130次输入就会有99%的可能性发生一次碰撞,不过即使如此,即便是人类制造的所有计算机自宇宙诞生开始一直运算到今天,发生一次碰撞的几率也是极其微小的。
-
隐匿性:也就是说,对于一个给定的输出结果 H(x) ,想要逆推出输入 x ,在计算上是不可能的。如果想要得到 H(x) 的可能的原输入,不存在比穷举更好的方法。
常用的Hash函数有:SHA1、MD5、SHA2等
3. Hash冲突#
对于不同的输入值,Hash函数可能会给出相同的输出,这种情况就叫做Hash冲突。
哈希冲突是不可避免的,我们常用解决哈希冲突的方法有开放地址法和** 拉链法**。
3.1 拉链法#
拉链法的核心思想是:如果Hash表的某个位置上发生了Hash冲突(也就是说在将一个元素放置到数组中某个位置的时候,这个位置上已经有其他元素占据了),那么将这些元素以链表的形式存放。

链表的查询效率是比较低的,所以如果在Hash表的某个位置上发生冲突的次数太多的话,那么这个位置就是一个很长的链表。查询速度较慢。在Java 8中,HashMap做了一个优化,就是当链表长度达到8时,会自动将链表转换成红黑树,查询效率较高(红黑树是一种自平衡的二叉查找树)。
3.2 开放地址法#
在开放地址法中,若数据不能直接存放在哈希函数计算出来的数组下标时,就需要寻找其他位置来存放。在开放地址法中有三种方式来寻找其他的位置,分别是线性探测、二次探测、再哈希法。
3.2.1 线性探测法#
线性探测的插入比较简单,做法是:首先将元素进行hash映射,如果映射的位置上没有其他元素,就直接在这个位置上插入数据;如果这个位置上已经有数据了,那么判断下个位置上有无数据,如果没有直接插入如果有数据再进行下一次判断,直到找到空位。
线性探测的查找:先通过键值定位到数组下标位置,然后将这个位置上数据的值和你要查找数据的值对比,如果相等就直接找到了,如果不相等则继续判断下个元素,所有元素遍历完都没找到的话,则不存在。
线性探测的删除:首先还是通过键值映射到数组某个下标的位置,然后通过数组中元素的值和你要删除的元素的值进行比较,找出你要删除的那个元素。然后将这个位置上的元素删除并设置一个标志位说明这个位置上曾经有过数据(这步大家自己想想为什么要这么做)
3.2.2 二次探测法#
在线性探测哈希表中,数据会发生聚集,一旦聚集形成,它就会变的越来越大,那些哈希函数后落在聚集范围内的数据项,都需要一步一步往后移动,并且插入到聚集的后面,因此聚集变的越大,聚集增长的越快。这个就像我们在逛超市一样,当某个地方人很多时,人只会越来越多,大家都只是想知道这里在干什么。
二次探测是防止聚集产生的一种尝试,思想是探测相隔较远的单元,而不是和原始位置相邻的单元。在线性探测中,如果哈希函数得到的原始下标是x,线性探测就是x+1,x+2,x+3......,以此类推,而在二次探测中,探测过程是x+1,x+4,x+9,x+16,x+25......,以此类推,到原始距离的步数平方。
3.2.3 双哈希法#
双哈希是为了消除原始聚集和二次聚集问题,不管是线性探测还是二次探测,每次的探测步长都是固定的。双哈希是除了第一个哈希函数外再增加一个哈希函数用来根据关键字生成探测步长,这样即使第一个哈希函数映射到了数组的同一下标,但是探测步长不一样,这样就能够解决聚集的问题。
第二个哈希函数必须具备如下特点
- 和第一个哈希函数不一样;
- 不能输出为0,因为步长为0,每次探测都是指向同一个位置,将进入死循环,经过试验得出 stepSize=constant-(key%constant);形式的哈希函数效果非常好,constant是一个质数并且小于数组容量。
双hash的核心思想是,第二步生成一个随机的探测步长。
4. Hash表的相关应用#
电脑只有2G内存,怎么在20亿个数据中找到出现次数最多的整数
首先我们需要确定value的范围,因为这个20亿个数有可能是同一个数,那么value就为20亿次。因此我们最少需要用一个int型的数据来存这个数(Java中int占4个字节);
同时我们还要确定下这个20亿整数的取值范围是多少。如果取值范围是1~20亿的话,我们也可以用int来存key,如果是更大的取值范围的话,就需要考虑用long来存了。我们以极端坏的情况来考虑下这个问题:也就是20一个数据全是不同的数据,这些数据的取值范围是超过20亿的,因此我们需要用long类型来存key值,应int类型来存value值,20亿条记录的话大概需要26G左右的内存空间。这样的话显然内存不足,因此一次性统计20亿个数风险很大。
解决方案:将包含有20亿个数的大文件分成16个小文件,利用哈希函数,这样的话,同一个重复的数肯定不会分到不同的文件中去,并且,如果哈希函数足够好,那么这16个文件中不同的数也不会大于2亿(20 / 16)。然后我们在这16个文件中依次统计就可以了,最后进行汇总得到重复数最多的数。(汇总的时候我只需要取出每个小文件中出现次数最多的数,然后将这16个数进行比较就行了)
问题:如果这个20亿个数都相同怎么判断呢?
作者:程序员自由之路
出处:https://www.cnblogs.com/54chensongxia/p/11566973.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?