6. PyTorch进阶训练技巧
6.1 自定义损失函数
6.1.1 以函数方式定义
def my_loss(output, target): loss = torch.mean((output-target)**2) return loss
6.1.2 以类方式定义
每一个损失函数的继承关系我们就可以发现Loss函数部分继承自_loss, 部分继承自_WeightedLoss, 而_WeightedLoss继承自_loss, _loss继承自 nn.Module。将其当作神经网络的一层来对待,因此,损失函数类就需要继承自nn.Module类。
例子:DiceLoss
Dice Loss是一种在分割领域常见的损失函数,定义如下:
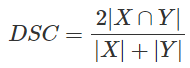
实现代码如下:
class DiceLoss(nn.Module): def __init__(self, weight=None, size_average=True): super(DiceLoss, self).__init__() def forward(self, inputs, targets, smooth=1): inputs = F.sigmoid(inputs) inputs = inputs.view(-1) ## 将其变为一维数据 targets = targets.view(-1) 交集= (输入 *目标).sum() dice = (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth) 返回1-骰子 # 使用方法 criterion = DiceLoss() 损失=标准(输入,目标)
注:在自定义损失函数时,涉及到数学运算时,建议最好全程使用PyTorch提供的张量计算接口,这样就不需要我们实现自动求导功能并且我们可以直接调用cuda。
6.2 动态调整学习率
设置适当的学习率衰减策略方式在PyTorch中被称为scheduler
6.2.1 使用官方scheduler
PyTorch已经在torch.optim.lr_scheduler封装好了一些动态调整学习率的方法,如下:
lr_scheduler.LambdaLR(optimizer,lr_lambda,last_epoch=-1,verbose=False)
介绍:将每个参数组的学习率设置为初始 lr 乘以给定函数。当 last_epoch=-1 时,设置初始 lr 为 lr。
参数:
-
-
optimizer– 包装的优化器。
-
lr_lambda(函数或列表) – 在给定整数参数 epoch 或此类函数列表的情况下计算乘法因子的函数,其中一个用于 optimizer.param_groups 中的每个组。
-
last_epoch (int) – 上一个epoch的索引。默认值:-1。
- verbose (bool) -- 如果为 True,则每次更新时都会向 stdout 打印一条消息。默认值:False。
-
lr_scheduler.MultiplicativeLR(optimizer,lr_lambda,last_epoch=-1,verbose=False)
lr_scheduler.StepLR(optimizer,step_size,gamma=0.1,last_epoch=-1,verbose=False)
介绍:每个 step_size epochs 衰减每个参数组的学习率。请注意,这种衰减可能与此调度程序外部对学习率的其他更改同时发生。当 last_epoch=-1 时,设置初始 lr 为 lr。
参数:
-
- optimizer– 包装的优化器。
- step_size (int) -- 学习率衰减的周期。
- gamma (float) – 学习率衰减的乘法因子。默认值:0.1。
- last_epoch (int) – 上一个epoch的索引。默认值:-1。
lr_scheduler.MultiStepLR(optimizer,milestones,gamma=0.1,last_epoch=-1,verbose=False)
介绍:一旦 epoch 的数量达到里程碑之一,通过 gamma 衰减每个参数组的学习率。请注意,这种衰减可能与此调度程序外部对学习率的其他更改同时发生。当 last_epoch=-1 时,设置初始 lr 为 lr。
参数:
-
- milestones(lsit)– 纪元索引列表。一定要增加。
lr_scheduler.ExponentialLR(optimizer,gamma,last_epoch=-1,verbose=False)
介绍:每个 epoch 衰减每个参数组的学习率。当 last_epoch=-1 时,设置初始 lr 为 lr。
参数:
-
- optimizer -- 包装优化器。
- gamma (float) – 学习率衰减的乘法因子。
- last_epoch (int) -- 最后一个纪元的索引。默认值:-1。
- verbose (bool) -- 如果为 True,则每次更新时都会向 stdout 打印一条消息。默认值:False。
lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=- 1, verbose=False)
参数:
-
-
optimizer-- 包装优化器。
-
T_max (int) – 最大迭代次数。
-
eta_min(float) – 最低学习率。默认值:0。
-
last_epoch (int))– 上一个epoch的索引。默认值:-1。
-
verbose (bool) -- 如果为 True,则每次更新时都会向 stdout 打印一条消息。默认值:False。
-
lr_scheduler.ReduceLROnPlateau(optimizer,mode='min',factor=0.1,patience=10,threshold=0.0001,threshold_mode='rel',cooldown=0,min_lr=0,eps=1e-08,verbose=False)
介绍:当指标停止改进时降低学习率。一旦学习停滞,模型通常会受益于将学习率降低 2-10 倍。该调度程序读取一个指标数量,如果“patience”的 epoch 数量没有改善,则学习率会降低。
参数:
- optimizer -- 包装优化器。
- mode (str) -- 最小值,最大值之一。在 min 模式下,当监控的数量停止减少时,lr 将减少;在最大模式下,当监控的数量停止增加时,它将减少。默认值:“分钟”。
- factor (float) -- 学习率降低的因素。 new_lr = lr * 因子。默认值:0.1。
- patience(int)——没有改善的时期数,之后学习率将降低。例如,如果patience = 2,那么我们将忽略前 2 个没有改善的 epoch,并且只有在第 3 个 epoch 之后损失仍然没有改善的情况下才会降低 LR。默认值:10。
- threshold (float) - 衡量新优化的阈值,仅关注重大变化。默认值:1e-4。
- threshold_mode (str) -- rel、abs 之一。在 rel 模式下,dynamic_threshold = best * ( 1 + threshold ) 在“max”模式下或 best * ( 1 - threshold ) 在 min 模式下。在 abs 模式下,dynamic_threshold = 最佳 + 最大模式下的阈值或最佳 - 最小模式下的阈值。默认值:'rel'。
- cooldown (int) – 在 lr 减少后恢复正常操作之前要等待的 epoch 数。默认值:0。
- min_lr(浮点数或列表)- 标量或标量列表。所有参数组或每个组的学习率的下限。默认值:0。
- eps (float) – 应用于 lr 的最小衰减。如果新旧 lr 之间的差异小于 eps,则忽略更新。默认值:1e-8。
- verbose (bool) -- 如果为 True,则每次更新时都会向 stdout 打印一条消息。默认值:False。
-
使用官方API
# 选择一种优化器 optimizer = torch.optim.Adam(...) # 选择上面提到的一种或多种动态调整学习率的方法 scheduler1 = torch.optim.lr_scheduler.... scheduler2 = torch.optim.lr_scheduler.... ... schedulern = torch.optim.lr_scheduler.... # 进行训练 for epoch in range(100): train(...) validate(...) optimizer.step() # 需要在优化器参数更新之后再动态调整学习率 scheduler1.step() ... schedulern.step()
注:在使用官方给出的torch.optim.lr_scheduler时,需要将scheduler.step()放在optimizer.step()后面进行使用。
6.2.2 自定义scheduler
例子:学习率每30轮下降为原来的1/10
def adjust_learning_rate(optimizer, epoch): lr = args.lr*(0.1**(epoch//30)) for param_group in optimizer.param_groups: param_group['lr'] = lr
optimizer = torch.optim.SGD(model.parameters(),lr = args.lr,momentum = 0.9) for epoch in range(10): train(...) validate(...) adjust_learning_rate(optimizer,epoch)
6.3 模型微调-torchvision
迁移学习(transfer learning),将从源数据集学到的知识迁移到目标数据集上。
迁移学习的一大应用场景是模型微调(finetune):先找到一个同类的别人训练好的模型,把别人现成的训练好了的模型拿过来,换成自己的数据,通过训练调整一下参数。
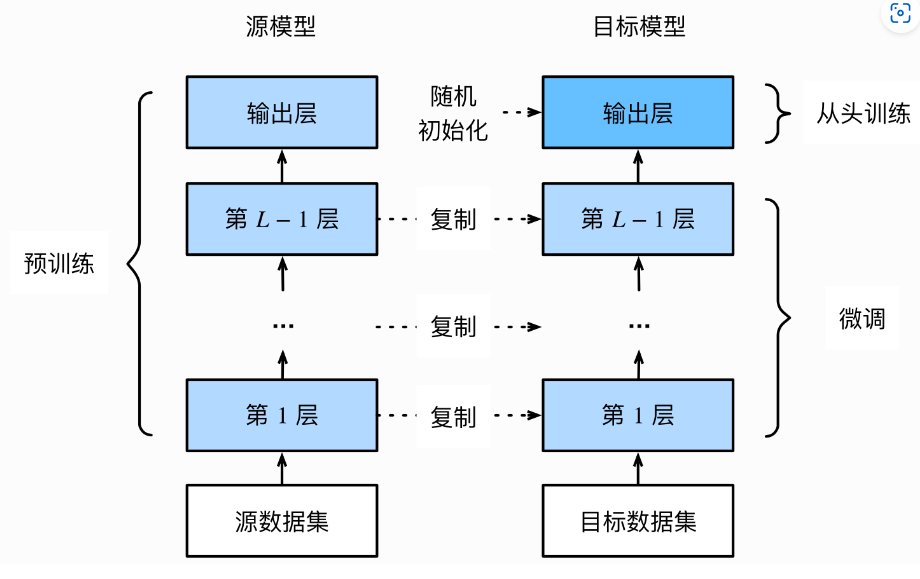
6.3.1 模型微调的流程
-
在源数据集(如ImageNet数据集)上预训练一个神经网络模型,即源模型。
-
创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。我们还假设源模型的输出层跟源数据集的标签紧密相关,因此在目标模型中不予采用。
-
为目标模型添加一个输出⼤小为⽬标数据集类别个数的输出层,并随机初始化该层的模型参数。
-
在目标数据集上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
6.3.2 使用已有模型结构
- 实例化网络
import torchvision.models as models resnet18 = models.resnet18() # resnet18 = models.resnet18(pretrained=False) 等价于与上面的表达式 alexnet = models.alexnet() vgg16 = models.vgg16() squeezenet = models.squeezenet1_0() densenet = models.densenet161() inception = models.inception_v3() googlenet = models.googlenet() shufflenet = models.shufflenet_v2_x1_0() mobilenet_v2 = models.mobilenet_v2() mobilenet_v3_large = models.mobilenet_v3_large() mobilenet_v3_small = models.mobilenet_v3_small() resnext50_32x4d = models.resnext50_32x4d() wide_resnet50_2 = models.wide_resnet50_2() mnasnet = models.mnasnet1_0()
-
传递
pretrained参数
在默认状态下pretrained = False:使用预训练得到的权重;当pretrained = True:使用在一些数据集上预训练得到的权重。
import torchvision.models as models resnet18 = models.resnet18(pretrained=True) alexnet = models.alexnet(pretrained=True) squeezenet = models.squeezenet1_0(pretrained=True) vgg16 = models.vgg16(pretrained=True) densenet = models.densenet161(pretrained=True) inception = models.inception_v3(pretrained=True) googlenet = models.googlenet(pretrained=True) shufflenet = models.shufflenet_v2_x1_0(pretrained=True) mobilenet_v2 = models.mobilenet_v2(pretrained=True) mobilenet_v3_large = models.mobilenet_v3_large(pretrained=True) mobilenet_v3_small = models.mobilenet_v3_small(pretrained=True) resnext50_32x4d = models.resnext50_32x4d(pretrained=True) wide_resnet50_2 = models.wide_resnet50_2(pretrained=True) mnasnet = models.mnasnet1_0(pretrained=True)
注:
通常PyTorch模型的扩展为.pt或.pth,程序运行时会首先检查默认路径中是否有已经下载的模型权重,一旦权重被下载,下次加载就不需要下载了。
一般情况下预训练模型的下载会比较慢,我们可以直接通过迅雷或者其他方式去 这里 查看自己的模型里面model_urls,然后手动下载,预训练模型的权重在Linux和Mac的默认下载路径是用户根目录下的.cache文件夹。在Windows下就是C:\Users\<username>\.cache\torch\hub\checkpoint。我们可以通过使用 torch.utils.model_zoo.load_url()设置权重的下载地址。
如果觉得麻烦,还可以将自己的权重下载下来放到同文件夹下,然后再将参数加载网络。
self.model = models.resnet50(pretrained=False) self.model.load_state_dict(torch.load('./model/resnet50-19c8e357.pth'))
如果中途强行停止下载的话,一定要去对应路径下将权重文件删除干净,要不然可能会报错
6.3.3 训练特定层
在默认情况下,参数的属性.requires_grad = True,如果我们从头开始训练或微调不需要注意这里。但如果我们正在提取特征并且只想为新初始化的层计算梯度,其他参数不进行改变。那我们就需要通过设置requires_grad = False来冻结部分层。在PyTorch官方中提供了这样一个例程。
def set_parameter_requires_grad(model, feature_extracting): if feature_extracting: for param in model.parameters(): param.requires_grad=False
在下面我们仍旧使用resnet18为例的将1000类改为4类,但是仅改变最后一层的模型参数,不改变特征提取的模型参数;
注意我们先冻结模型参数的梯度,再对模型输出部分的全连接层进行修改,这样修改后的全连接层的参数就是可计算梯度的。
import torchvision.models as models # 冻结参数的梯度 feature_extract = True model = model.resnet18(pretrained=True) set_parameter_requires_grad(model, feature_extract) # 修改模型 num_ftrs = model.fc.in_features model.fc = nn.Linear(in_features=num_ftrs, out_features=4, bias=True)
之后在训练过程中,model仍会进行梯度回传,但是参数更新则只会发生在fc层。通过设定参数的requires_grad属性,我们完成了指定训练模型的特定层的目标,这对实现模型微调非常重要。
6.3 半精度训练
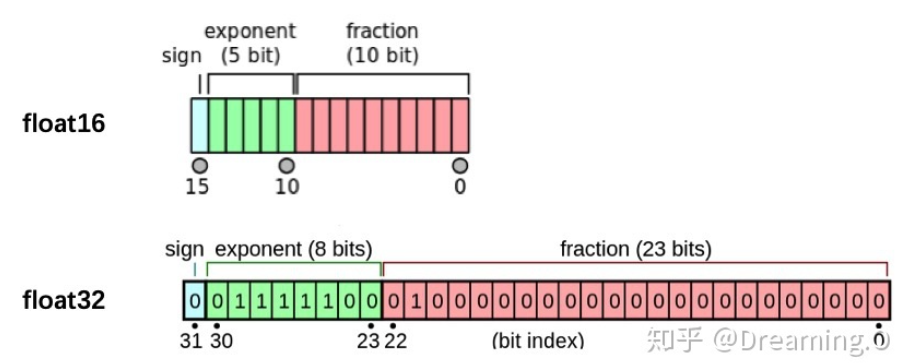
PyTorch默认的浮点数存储方式用的是torch.float32,小数点后位数更多固然能保证数据的精确性,但绝大多数场景其实并不需要这么精确,只保留一半的信息也不会影响结果,也就是使用torch.float16格式。由于数位减了一半,因此被称为“半精度”,具体如下图:
-
import autocast
from torch.cuda.amp import autocast
-
模型设置
在模型定义中,使用python的装饰器方法,用autocast装饰模型中的forward函数。
@autocast() def forward(self, x): ... return x
-
训练过程
在训练过程中,只需在将数据输入模型及其之后的部分放入“with autocast():“即可:
for x in train_loader: x = x.cuda() with autocast(): output = model(x) ...
注意:
半精度训练主要适用于数据本身的size比较大(比如说3D图像、视频等)。当数据本身的size并不大时(比如手写数字MNIST数据集的图片尺寸只有28*28),使用半精度训练则可能不会带来显著的提升。
6.4 使用argparse进行调参
6.4.1 argparse简介
6.4.2 argparse的使用
-
创建
ArgumentParser()对象 -
调用
add_argument()方法添加参数 -
使用
parse_args()解析参数
import argparse # 创建ArgumentParser()对象 parser = argparse.ArgumentParser() # 添加参数 parser.add_argument('-o-', '--output', action = 'store_true', help = 'show_output') # action = `store_true` 会将output参数记录为True # type 规定了参数的格式 # default 规定了默认值 parser.argument('--lr', type=float, default=3e-5, help='select the learning rate, default=1e-3') parser.argument('--batch_size', type=int, default=32, required = True, help='input batch size') # 使用parse_args()解析函数 args = parser.parse_args()
argparse的参数主要可以分为可选参数和必选参数。
可选参数就跟我们的lr参数相类似,未输入的情况下会设置为默认值。必选参数就跟我们的batch_size参数相类似,当我们给参数设置required =True后,我们就必须传入该参数,否则就会报错。
6.4.3 更加高效使用argparse修改超参数
config.py,然后在train.py或者其他文件导入import argparse def get_options(parser=argparse.ArgumentParser()): parser.add_argument('--workers', type=int, default=0, help='number of data loading workers, you had better put it ' '4 times of your gpu') parser.add_argument('--batch_size', type=int, default=4, help='input batch size, default=64') parser.add_argument('--niter', type=int, default=10, help='number of epochs to train for, default=10') parser.add_argument('--lr', type=float, default=3e-5, help='select the learning rate, default=1e-3') parser.add_argument('--seed', type=int, default=118, help="random seed") parser.add_argument('--cuda', action='store_true', default=True, help='enables cuda') parser.add_argument('--checkpoint_path',type=str,default='', help='Path to load a previous trained model if not empty (default empty)') parser.add_argument('--output',action='store_true',default=True,help="shows output") opt = parser.parse_args() if opt.output: print(f'num_workers: {opt.workers}') print(f'batch_size: {opt.batch_size}') print(f'epochs (niters) : {opt.niter}') print(f'learning rate : {opt.lr}') print(f'manual_seed: {opt.seed}') print(f'cuda enable: {opt.cuda}') print(f'checkpoint_path: {opt.checkpoint_path}') return opt if __name__ == '__main__': opt = get_options()
# 导入必要库 ... import config opt = config.get_options() manual_seed = opt.seed num_workers = opt.workers batch_size = opt.batch_size lr = opt.lr niters = opt.niters checkpoint_path = opt.checkpoint_path # 随机数的设置,保证复现结果 def set_seed(seed): torch.manual_seed(seed) torch.cuda.manual_seed_all(seed) random.seed(seed) np.random.seed(seed) torch.backends.cudnn.benchmark = False torch.backends.cudnn.deterministic = True ... if __name__ == '__main__': set_seed(manual_seed) for epoch in range(niters): train(model,lr,batch_size,num_workers,checkpoint_path) val(model,lr,batch_size,num_workers,checkpoint_path)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号