
rabbitmq搭建与python应用
Rabbitmq
Rabbitmq简介
Rabbitmq是一个应用较广的消息中间件,凭借其高可靠、易扩展、高可用以及丰富的功能特性在很多行业得到了广泛应用。
什么是消息中间件?消息中间件是利用高效可靠的机制进行与平台无法的数据交流,可以在分布式环境下扩展进程间的通信。在分布式、微服务应用越发广泛的今天,消息中间件已经成为了一名开发者必须熟悉的技能。目前使用较多的消息队列有ActiveMQ,RabbitMQ,Kafka,RocketMQ。
Rabbitmq整体架构
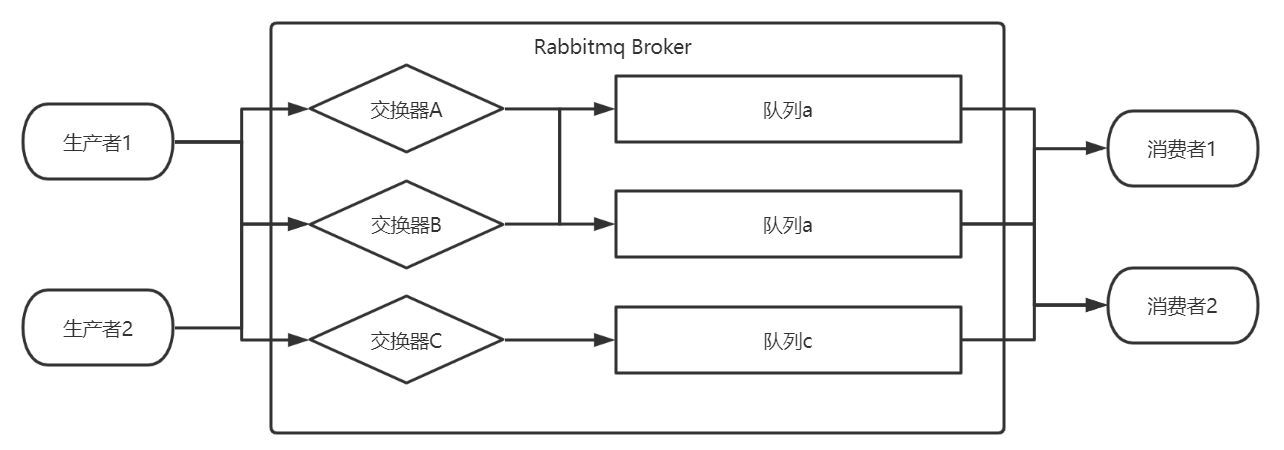
生产者:消息的发送方。
消费者:消息的接收方。
Broker:rabbitmq的服务节点,其中包括了交换器与队列。
队列:rabbitmq的内部对象,消息的存储位置。
交换器:复制消息的转发,根据相关的配置将生产者产生的消息转发至队列中。
Rabbitmq的安装
宿主机部署:
yum install erlang
yum install rabbitmq-server
systemctl start rabbitmq-server
rabbitmq-plugins enable rabbitmq_management
centos上使用yum管理软件包,如果服务器是ubuntu需要换成apt。另外较老系统中使用service管理本机服务,需要使用service命令启动rabbitmq服务。
容器部署:
docker run -p 15672:15672 -p 5672:5672 -it --name rabbitmq_server -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin rabbitmq:3.9.22-management
-p将宿主机端口映射到容器上,后面可以直接通过宿主机的端口访问rabbitmq服务。
--name指定容器名称。
-e参数修改容器环境变量,这里修改的rabbitmq的用户名和密码,不同的容器存在不同的环境变量,这个有兴趣的可以dockerhub上查看了解。
这里指定的容器tags为3.9.22-management,带management的是附带了web控制台的镜像,一般推荐使用这种。部署之后可以通过访问控制台,进入rabbitmq的管理页面。
另外目前可以更多需要K8s微服务部署集群的场景,这种场景部署较复杂,这里不做讨论。
Pika
这里的pika指的不是那个类redis 存储系统,而是python中操作rabbitmq的三方库。(Pika is a RabbitMQ client library for Python.)
初始化
import pika
# 设置用户名密码
user_info = pika.PlainCredentials('username', 'password')
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters('host', port, '/', user_info))
# 创建一个channel
channel = connection.channel()
在操作rabbitmq之前,都需要通过认证,创建channel,之后的操作都是建立在channel之上的。
创建队列
import pika
# 设置用户名密码
user_info = pika.PlainCredentials('guest', 'xxx')
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters('xxxx', 5672, '/', user_info))
# 创建一个channel
channel = connection.channel()
# 创建队列,存在就跳过
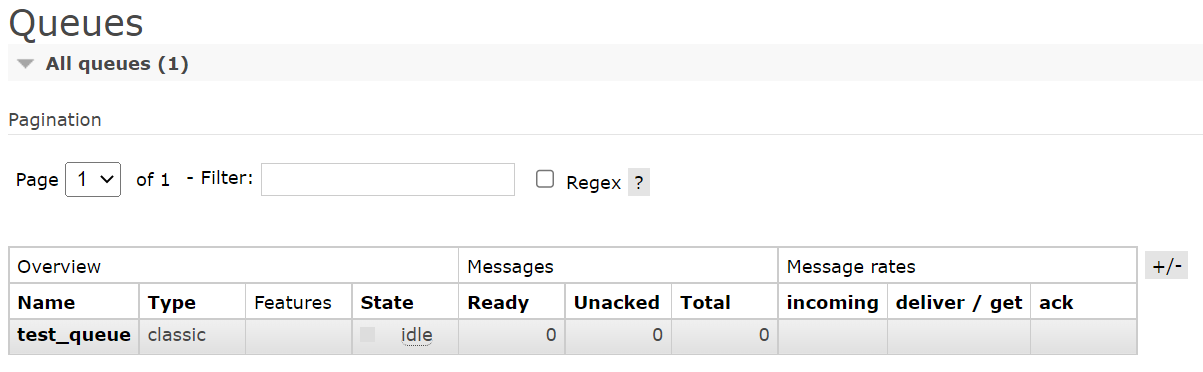
channel.queue_declare(queue='test_queue')
queue_declare这个方法,遇到队列已存在,会自动跳过创建步骤,推荐在发送消息之前,可以加上。
运行之后,可以在web页面看到新创建的这个队列信息。
发送消息
channel.basic_publish(exchange='',
routing_key='test_queue',
body='hello queue'.encode("utf-8")
)
exchange为空,使用rabbitmq的默认交换器,
routing_key路由键,默认交换器使用全匹配,即队列名称。
body消息体,bytes类型。
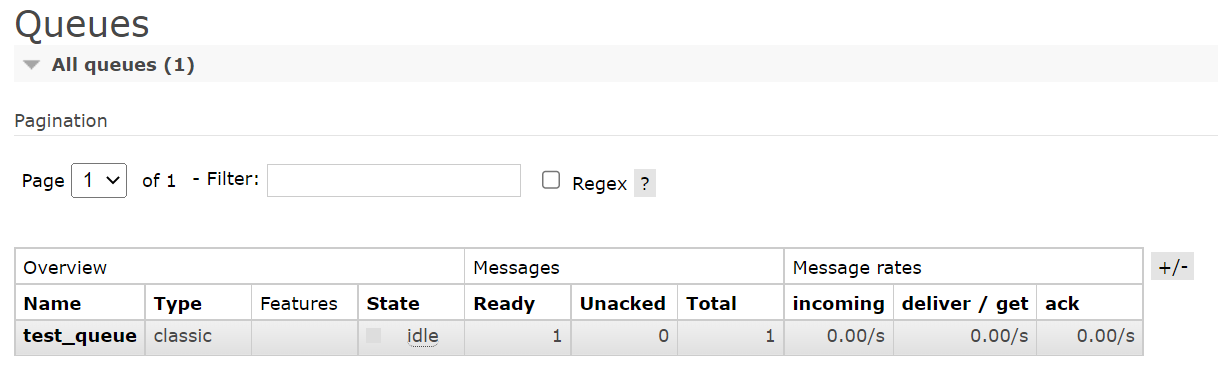
发送之后,可以从网页查看到队列中的消息数。
接收消息
推模式
# 回调函数
def callback(ch, method, properties, body):
print('消息内容为:%s' % format(body))
channel.basic_consume(queue='test_queue',
auto_ack=True,
on_message_callback=callback
)
channel.start_consuming()
queue指定,监听的队列。
auto_ack:接收到消息之后自动ack确定。
on_message_callback:设置获取到消息时的回调地址。
推模式消费者将会处于堵塞状态,一直等待消息的到来。
输出内容:
消息内容为:b'hello queue'
此时再从网页查看队列状态,可以看到消息数回到0。
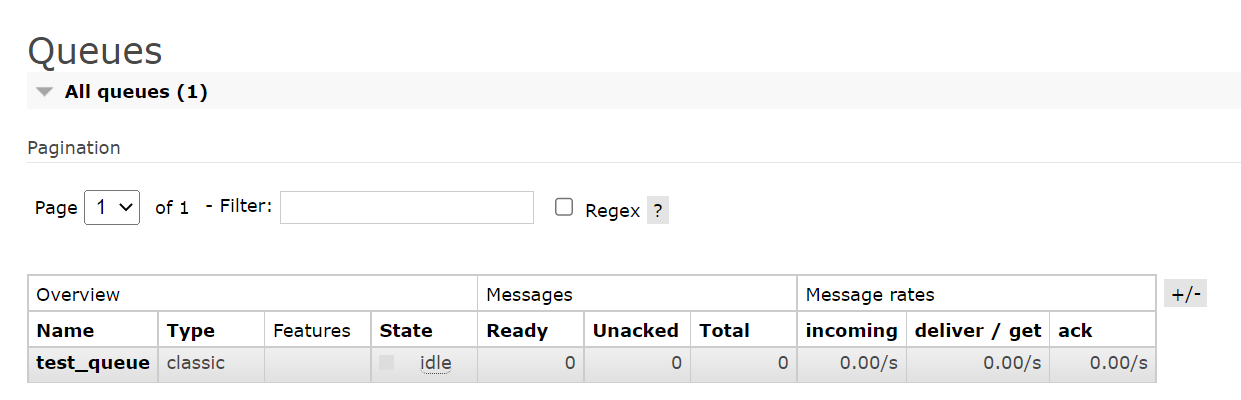
拉模式
method_frame, header_frame, body = channel.basic_get("test_queue", auto_ack=True)
if method_frame:
print(method_frame, header_frame, body) # 收到的全部数据 就要body
print('消息内容为:%s' % body)
else:
print('没有收到消息')
basic_get拉模式,由消费者自主控制,什么时候去获取消息。第一个参数为队列名称。
输出结果:
消息内容为:b'hello queue'
创建交换器
channel.exchange_declare(exchange='test_exchange', exchange_type='direct')
exchange:设置交换器的名称
exchange_type:设置交换器的类型,
class ExchangeType(Enum) :
direct = 'direct'
fanout = 'fanout'
headers = 'headers'
topic = 'topic'
目前rabbitmq交换器支持上面这四种类型。具体的区别与用法将在其它文章种做详细介绍。创建交换器和创建队列一样,当遇到已经创建的情况,会自动跳过。创建成功之后,可以在网页看到交换器的信息。
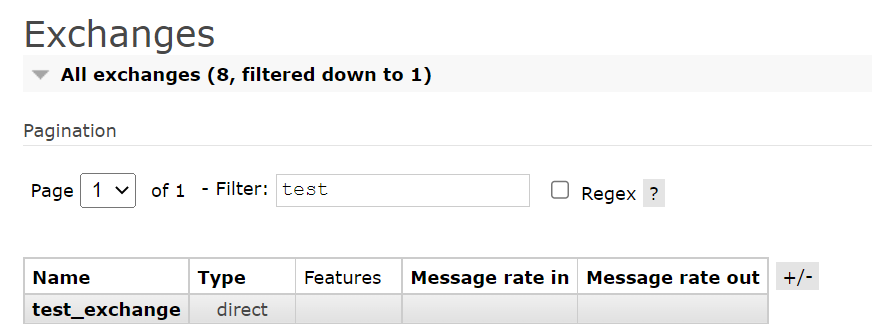
绑定队列
创建完队列和交换器之后,需要使用绑定键,将队列和交换器建立绑定关系。
channel.queue_bind(exchange='test_exchange', queue='test_queue')
exchange:绑定交换器的名称
queue:绑定队列的名称
routing_key:绑定键名称,默认为队列的名称。(这种使用方法在实际应用种较为常见)
绑定之后,可以在网页查看到绑定的信息。
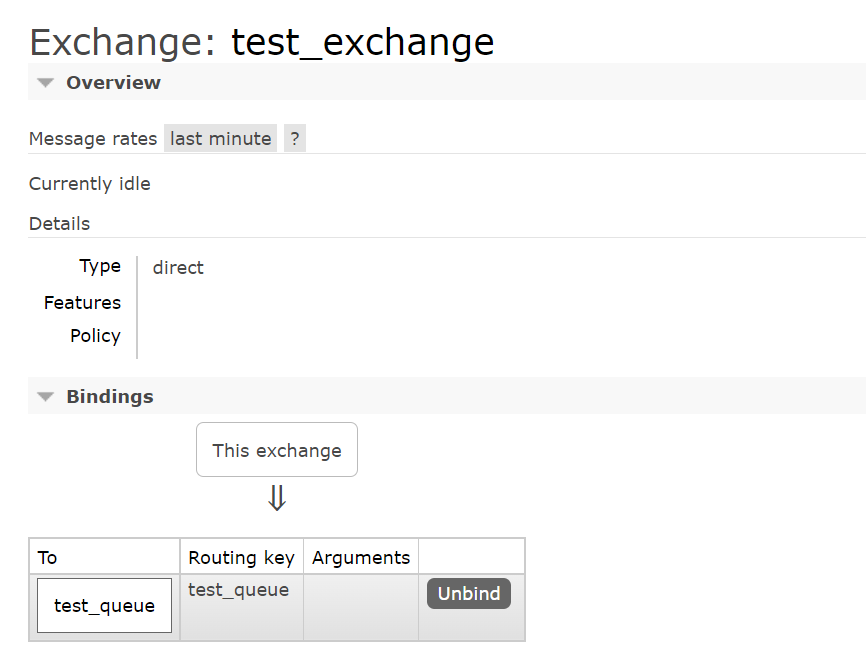
本人CSDN原地址:https://blog.csdn.net/l1345411028/article/details/126601981

 浙公网安备 33010602011771号
浙公网安备 33010602011771号