
鸢尾花-k近邻预测算法
环境
编程语言: python3.10
运行平台: windows10
依赖库安装: matplotlib pandas numpy scikit-learn
介绍
根据花瓣的长度和宽度以及花萼的长度和宽度,得出花的品种属于setosa、versicolor 或virginica 三个品种之一。
散点图源码
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import pandas as pd
import matplotlib.pyplot as plt
# 获取鸢尾花数据集
iris_dataset = load_iris()
# 打乱数据集,获取训练集与预测集,可以添加test_size train_size参数指定测试集大小,默认25%
X_train, X_test, y_train, y_test = train_test_split(
iris_dataset['data'], iris_dataset['target'], random_state=0)
# 利用X_train中的数据创建DataFrame
# 利用iris_dataset.feature_names中的字符串对数据列进行标记
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
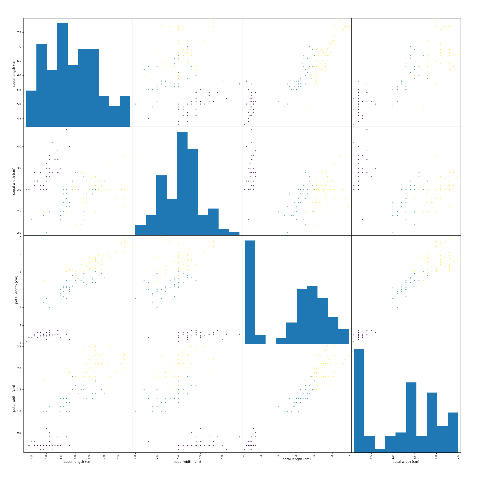
# 利用DataFrame创建散点图矩阵,按y_train着色
grr = pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(24, 24), alpha=.8)
# 创建窗口
plt.figure(figsize=(24, 24))
# 展示窗口
plt.show()
数据集数据结构
{
'data': array([[5.1, 3.5, 1.4, 0.2],
......
[5.9, 3. , 5.1, 1.8]]),
'target': array([0, 0, ... 2, 2]),
'frame': None,
'target_names': array(['setosa', 'versicolor', 'virginica'], dtype='<U10'), 'DESCR': '... more ...',
'feature_names': ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'],
'filename': 'iris.csv',
'data_module': 'sklearn.datasets.data'
}
结构说明:
- data: 花瓣特征数据集
- target: 每个花瓣数据对应品种结果,保存的是target_names数组的下标
- target_names: 结果集,鸢尾花的三个品种
- DESCR: 数据集的简要说明
- feature_names: 每一个特征的简要说明
- filename: 数据集的文件名称
- data_module: 数据对应的module
散点图
k近邻算法
k近邻算法在训练集中寻找与这个新数据点距离最近的数据点,然后将找到的数据点的标签赋值给这个新数据点。k 近邻算法中k 的含义是,我们可以考虑训练集中与新数据点最近的任意k 个邻居,然后用这些邻居中数量最多的类别做出预测。
k近邻源码
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
iris_dataset = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris_dataset['data'], iris_dataset['target'], random_state=0)
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
grr = pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(24, 24), alpha=.8)
# 设置k近邻算法的k值
knn = KNeighborsClassifier(n_neighbors=5)
# 设置k近邻算法的训练数据集与训练结果集
knn.fit(X_train, y_train)
# 创建一个新的测试数据
X_new = np.array([[5, 2.9, 1, 0.2]])
# 根据测试数据预测结果
prediction = knn.predict(X_new)
# 输出预测结果
print("Prediction: {}".format(prediction))
print("Predicted target name: {}".format(iris_dataset['target_names'][prediction]))
# 根据测试数据集预测结果
y_pred = knn.predict(X_test)
# 输出预测结果与 预测准确性
print("Test set predictions:\n {}".format(y_pred))
print("Test set score: {:.2f}".format(np.mean(y_pred == y_test)))
输出结果
Prediction: [0]
Predicted target name: ['setosa']
Test set predictions:
[2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0
2]
Test set score: 0.97
结论
根据测试数据集的预测结果与测试数据集的正确结果比较,得到预测的准确性可以达到97%.
注意
安装sklearn的时候,可能会需要安装VC.
作者:红雨
出处:https://www.cnblogs.com/52why
微信公众号: 红雨python

 浙公网安备 33010602011771号
浙公网安备 33010602011771号