

基于农业病虫害知识图谱的智能问答系统开发流程
基于农业病虫害知识图谱的智能问答系统
后端技术:java、springboot、Neo4j图数据库、python爬虫、数据处理技术、朴素贝叶斯分类算法、HANLP分词工具。
前端技术:微信小程序界面设计、合法域名配置、阿里云服务器、域名、ssl证书。
注意:修改和扩充的前提是要读懂后端代码。
注意:修改和扩充的前提是要读懂后端代码。
注意:修改和扩充的前提是要读懂后端代码。
界面演示: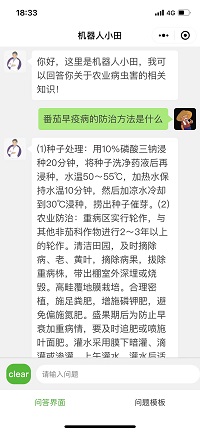
一、知识图谱的建立与后续扩充
1.爬虫编写,获取知识图谱的数据,整理成csv
[数据源](农业病虫害信息云数据库 (sinoverse.cn))
技术:python爬虫、selenium、数据处理
通过父网页爬取子网页url,遍历子网页url,进行爬取。
通过数据处理和re正则,提取关键信息,整理成csv文件,这里的作物名,疾病名、各种属性、关系都是自定义的,想扩充知识图谱的话,需要自己添加属性、实体、关系等信息,信息越多知识图谱越丰富。
爬父网页源代码(源代码中包含各种疾病的网页路径信息)
from selenium import webdriver
import time
f = open("plant.txt",encoding='utf-8')
# 调用文件的 readline()方法
lines = f.readlines() # 每次读取一行内容
print(lines)
text = [line.strip("\n") for line in lines]
print(text)
for i in text:
i = str(i)
print(i)
chromepath = 'D:\chrome\chromedriver.exe'
browser = webdriver.Chrome(executable_path=chromepath)
browser.get('http://cloud.sinoverse.cn/index_bch-list.html?k=' + i + '&ism=1')
time.sleep(3)
pageSource = browser.page_source
print(pageSource)
with open(r'D:\PycharmProjects\souhu\result/' + i + '.txt', 'a+', encoding='utf-8') as h:
h.write(pageSource)
browser.close()
提取子网页id
# coding=utf-8
import os
import csv
import pandas as pd
filenames=os.listdir(r'D:\PycharmProjects\souhu\result')
print(filenames)
# filenames = ['小麦.txt']
for name in filenames:
f = open('D:\PycharmProjects\souhu/result/'+ name , encoding='utf-8')
# 调用文件的 readline()方法
res = []
lines = f.readlines() # 每次读取一行内容
print(lines)
for i in lines:
print(i)
p = i.find('href="index_bch-show.html?id=')
if p > 0:
count = i.count('href="index_bch-show.html?id=')
print(count)
# a = 0
for x in range(count):
p = i.find('href="index_bch-show.html?id=')
res.append(i[p + 29:p + 61])
# res = text1[p + 29:p + 61]
# res.
i = i[p + 29:]
print(res)
print(len(res))
# 任意的多组列表
a = res
# 字典中的key值即为csv中列名
dataframe = pd.DataFrame({'a_name': a})
# 将DataFrame存储为csv,index表示是否显示行名,default=True
dataframe.to_csv('D:\PycharmProjects\souhu\id/' + name[:-4] + '.csv', index=False, sep=',')
爬取各种疾病详细信息
import json
import os
import csv
import pandas as pd
import requests
import csv
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36'}
url = 'http://app.sinoverse.cn:9090/api/cloud.jsp?t=bch_show'
filenames=os.listdir(r'D:\PycharmProjects\souhu\id')
print(filenames)
for name in filenames:
list = []
with open(r"D:\PycharmProjects\souhu\id/"+name, "r") as f:
reader = csv.reader(f)
for row in reader:
list.append(row)
print(list)
for i in list[1:-1]:
# print(type(i))
d = {'id': i}
r = requests.post(url, data=d, headers=headers)
c = r.json()
print(c['list'])
data = str(c['list'])
string = data
string = string.replace('\': \'', ':')
string = string.replace('\', \'', '\n')
print(string)
i = str(i)
with open(r'D:\PycharmProjects\souhu\disdata/' + name[:-4] + i + '.txt', 'a+', encoding='utf-8') as h:
h.write(string)
结果图:

提取主要信息
import json
import os
import csv
import pandas as pd
import requests
import csv
filenames=os.listdir(r'D:\PycharmProjects\souhu\disdata')
print(filenames)
pid = []
yname = []
disname = []
style =[]
factors = []
way = []
type =[]
ename = []
for name in filenames:
f = open('D:\PycharmProjects\souhu\disdata/'+name, encoding='utf-8')
lines= f.readlines() # 每次读取一行内容
# print(lines)
print(lines[3][4:])
pid.append(name[:-40])
# yname.append(lines[-6][6:])
disname.append(lines[11][5:])
style.append(lines[8][6:])
factors.append(lines[-3][8:])
way.append(lines[3][4:])
type.append(lines[9][6:])
ename.append(lines[-2][6:])
dataframe = pd.DataFrame({'pid':pid,'disname':disname,'style':style,'factors':factors,'way': way,'type':type,'ename':ename})
dataframe.to_csv('D:\PycharmProjects\souhu/final.csv', index=False, sep=',',encoding='gbk')
结果图:

2.将数据导入Neo4j图数据库
技术:Neo4j图数据库、cypher查询语言
会安装Neo4j图数据库,会简单使用(百度一下,10min学会)
上节整理好的数据
导入代码:
LOAD CSV WITH HEADERS FROM "file:///genre.csv" AS line
MERGE (p:Genre{gid:toInteger(line.gid),name:line.gname})
LOAD CSV WITH HEADERS FROM 'file:///plant.csv' AS line
MERGE (p:Plant { pid:toInteger(line.pid),pname:line.pname,
alias:line.alias,place:line.place,text:line.text})
LOAD CSV WITH HEADERS FROM "file:///disease.csv" AS line
MERGE (p:Disease{did:toInteger(line.did),disname:line.disname,style:line.style,
factors:line.factors,way:line.way,ename:line.ename})
LOAD CSV WITH HEADERS FROM "file:///plant_to_disease.csv" AS line
match (from:Plant{pid:toInteger(line.pid)}),(to:Disease{did:toInteger(line.did)})
merge (from)-[r:mayget{pid:toInteger(line.pid),did:toInteger(line.did)}]->(to)
LOAD CSV WITH HEADERS FROM "file:///disease_to_genre.csv" AS line
match (from:Disease{did:toInteger(line.did)}),(to:Genre{gid:toInteger(line.gid)})
merge (from)-[r:is{did:toInteger(line.did),gid:toInteger(line.gid)}]->(to)
通过网页查看:
可视化
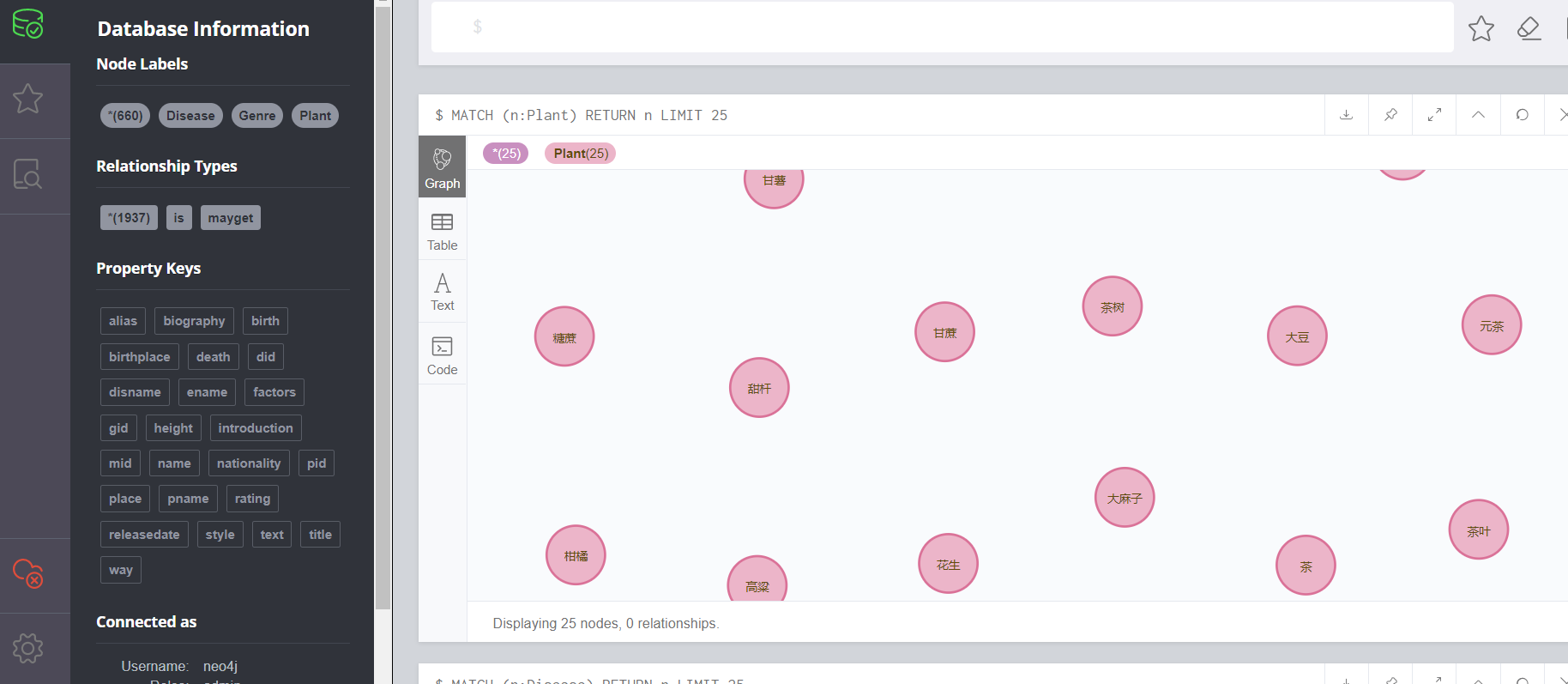
知识图谱构建完毕,想要扩充内容,可以将csv文件内容扩充,按以上步骤重新导入即可。
二、环境配置
1.Spark、hadoop环境安装
后期会涉及到spark的朴素贝叶斯分类器,而该分类器可以通过训练问题集合进行问题模板概率匹配,因此,系统中是否搭建了spark环境对项目是否能run起来至关重要。
下载地址: 下载地址
环境搭建流程简单,参考这篇文章[Spark/Hadoop安装]((75条消息) Spark在Windows下的环境搭建_xuweimdm的博客-CSDN博客_spark在windows下的环境搭建)
2.Hanlp分词器安装
由于项目是基于模板匹配的,后面会有中文分词和词性替换过程,会使用到Hanlp分词工具。
需要下载Hanlp的字典包和springboot配置文件,项目中已经包含。
如下图:hanlp配置
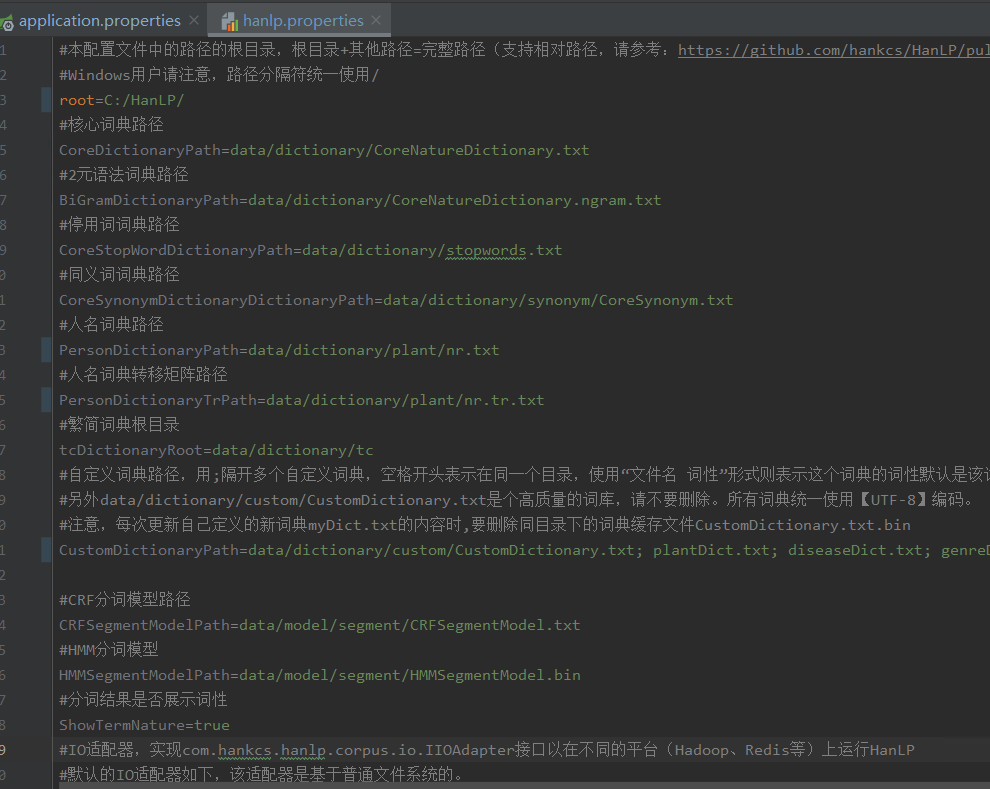
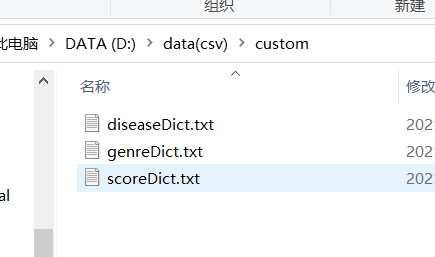
custom文件中会有各种实体词典用于词性替换,当需要扩充知识图谱时,需要把新实体加入custom的词典中。
三.朴素贝叶斯和问题模板
1.朴素贝叶斯分类算法
百度一下,需要理解原理。
2.问题模板
理解了朴素贝叶斯再来看问题模板
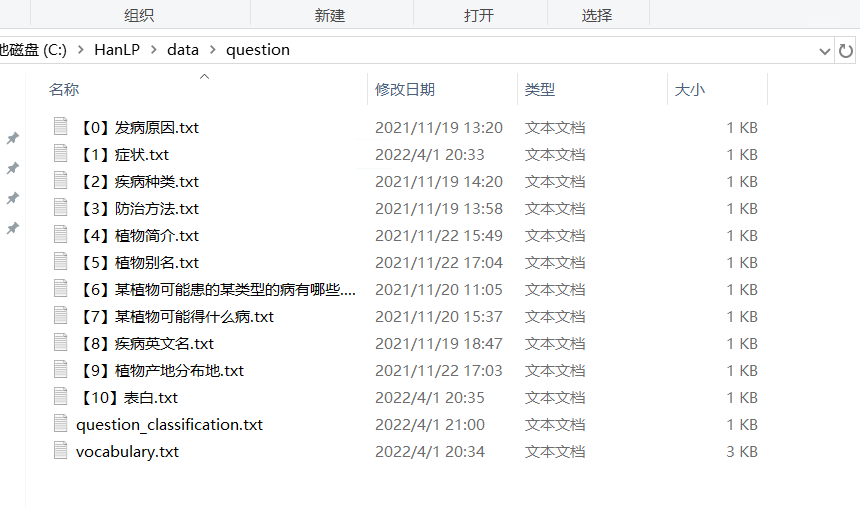
共十个问题模板,每个模板里有各种问题的不同问法,也就是朴素贝叶斯训练集,question_classification里面是各种类别,看懂朴素贝叶斯,这里就明白了,想要扩充问题集的话,就在每个模板里加入不同的问法,想扩充模板就添加新问题模板,例如“【11】XXXXX.txt”,在vocabulary中加入新添加的问题特征。
四、具体运行步骤
1.配置maven
2.配置项目文件
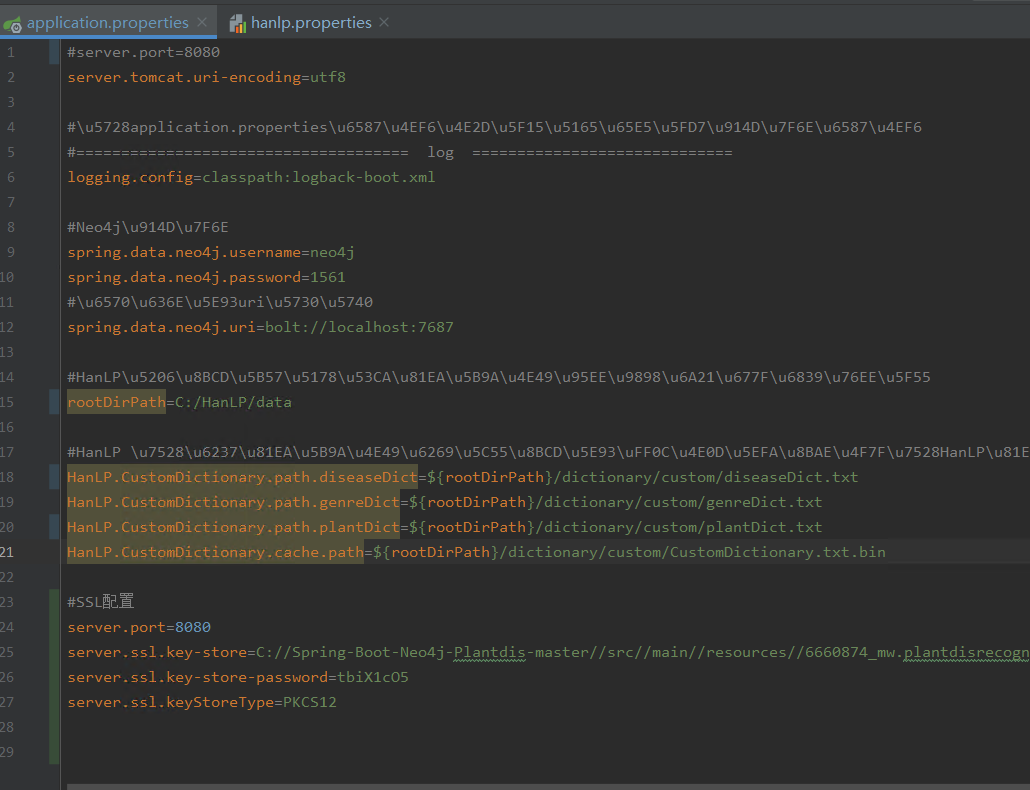
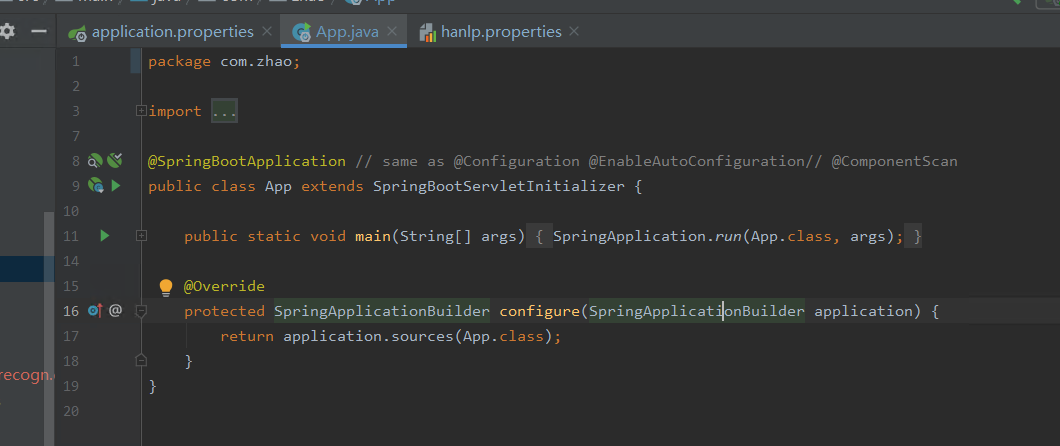
3.启动springboot
五、前端交互
1.接口配置
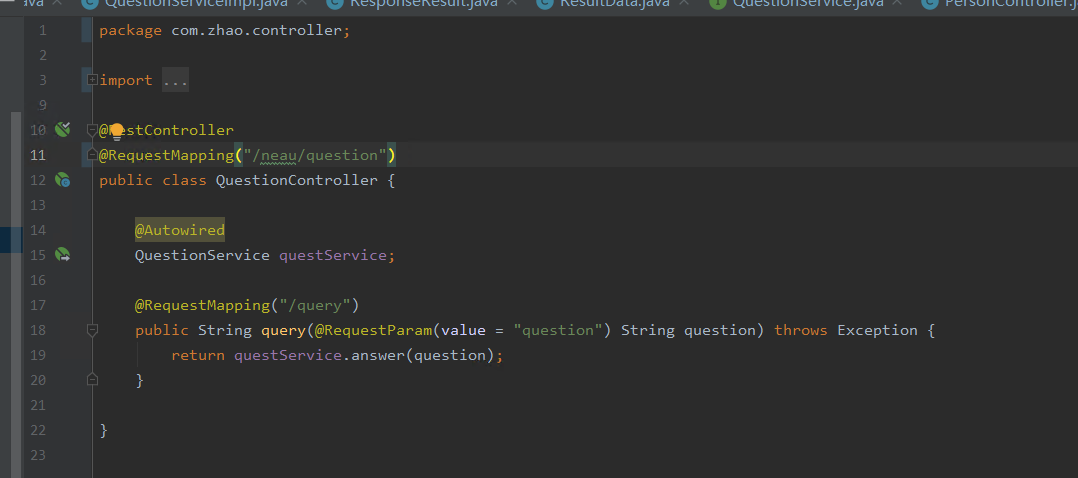
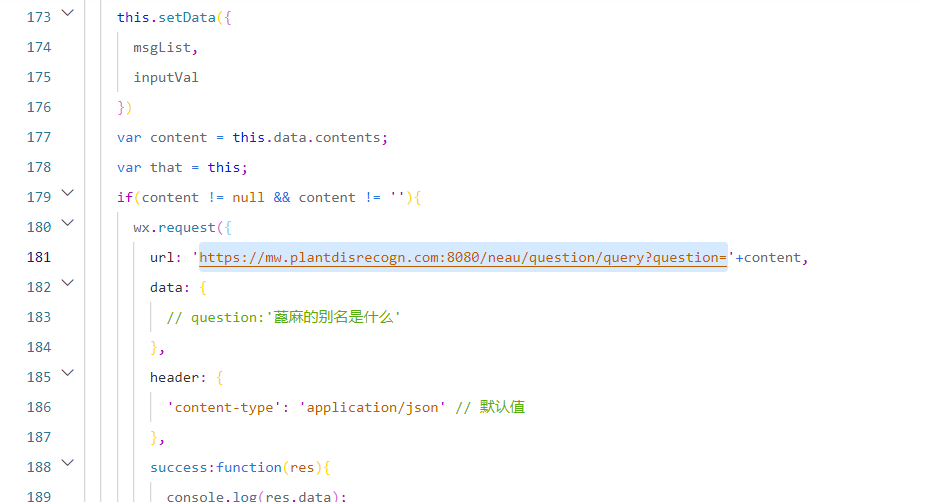
小程序基本不用动,只需要将接口地址放进去即可。
2.合法域名
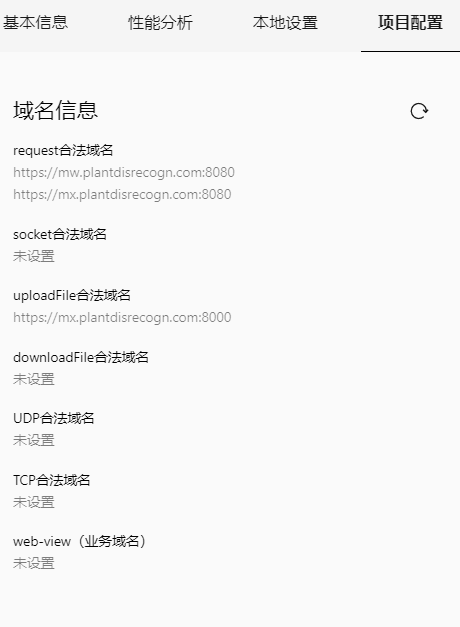
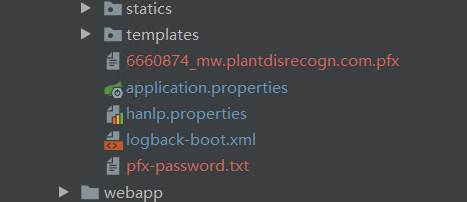
3.安全证书
去阿里云服务器申请,免费证书,定期更换pfx文件。
百度一下过程,10min。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY