
scrapy框架的运行与调试
scrapy框架的运行与调试
1、运行scrapy框架的第一种方法是在终端输入命令:
scrapy crawl 爬虫文件名
# 忽略运行详细信息
scrapy crawl 爬虫文件名 --nolog
2、第二种方法是在项目文件最高层目录下创建运行文件:
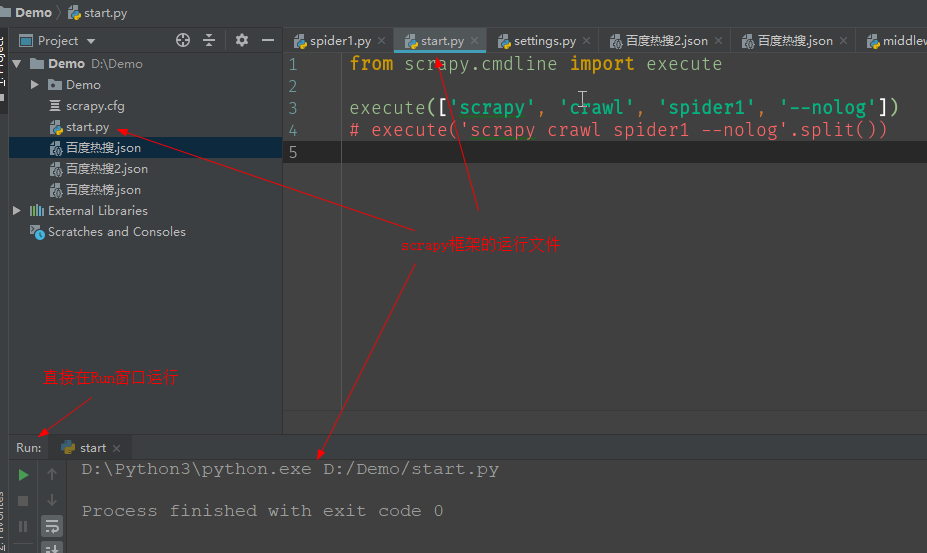
# start.py
from scrapy.cmdline import execute
# 将命令的每个单词存进一个列表传给execute()
execute(['scrapy', 'crawl', '爬虫文件名', '--nolog']) # 相当于在终端输入命令
# # 更加简洁的写法,在命令字符串后加上split()方法
# execute('scrapy crawl spider1 --nolog'.split())
只要运行start.py文件就可以运行scrapy框架了。
3、在第一种方法下,如果scrapy框架运行出错,就会结束程序,但不会报错。是不方便调试的。
而第二种方法,是能够调试的。文件的运行都会反映在运行窗口,如果出错,是会报错的。设置断点,进行调试是可以停下的。
如果觉得本文有用,万望看官慷慨解囊,不吝打赏,激励本编提供更加优质的内容
[点击进行打赏](https://www.cnblogs.com/52note/p/16507868.html)
