

scrapy爬虫框架
scrapy爬虫框架
1、下载安装scrapy
在命令行cmd中安装 scrapy
pip install scrapy -i https://pypi.douban.com/simple
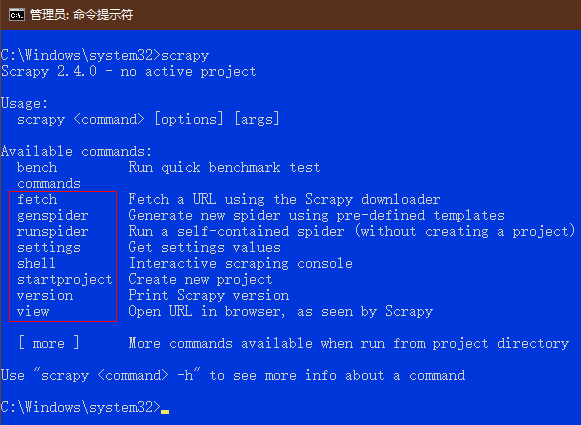
输入 scrapy 确认安装好了,红色方框框住的是常用的命令
2、创建scrapy项目
scrapy startproject 项目名
如图所示,仍然是在cmd窗口。先转到项目存放的路径,再创建项目。如图是在D盘根目录下创建一个Demo项目。scrapy还给出了下一步的提示:创建一个爬虫的方法

3、创建爬虫
scrapy genspider 爬虫文件名 爬取的域名 # 域名可随便写,之后可以在文件里修改
如图所示,先cd进入项目Demo文件内,再创建一个爬虫。

打开Demo项目,可以看到scrapy框架,和刚刚创建的爬虫文件
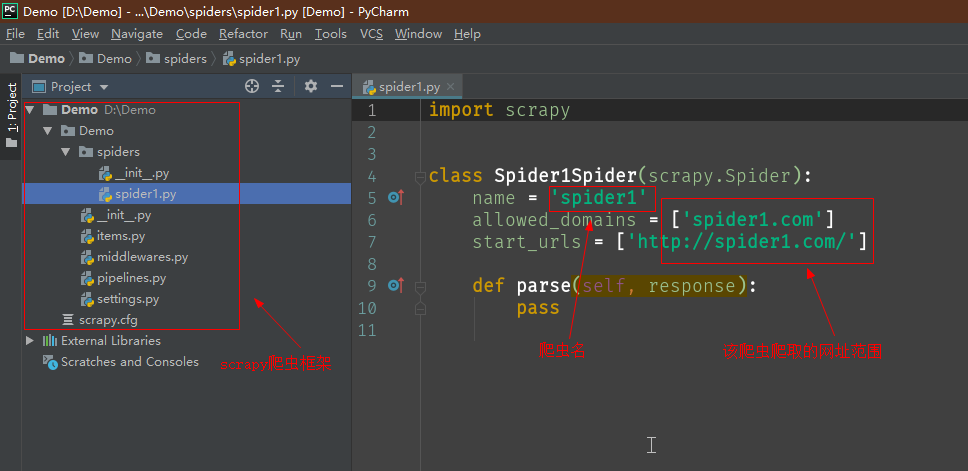
4、设置开始url和域名
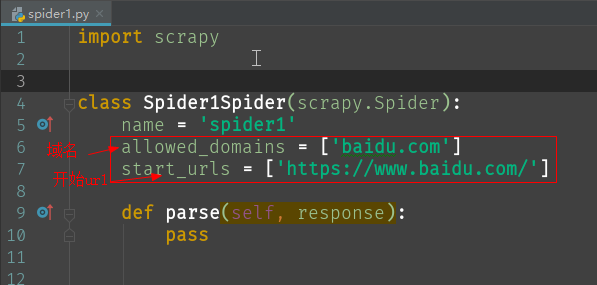
start_urls = ['http://www.baidu.com'] # 开始爬取的url
allowed_domains = ['baidu.com'] # 设定域名,只爬取指定域名中的url。
以百度首页为例。如图所示,设置好开始url 和 允许的域名。
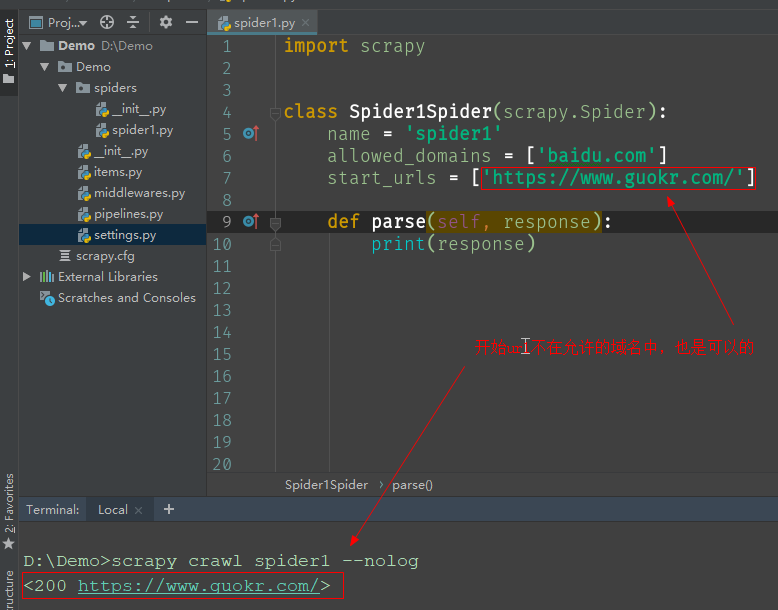
经测试开始url可以不在允许的域名中。
5、关闭robot协议
ROBOTSTXT_OBEY = False
打开settings文件,找到True 改成 False,如图所示:
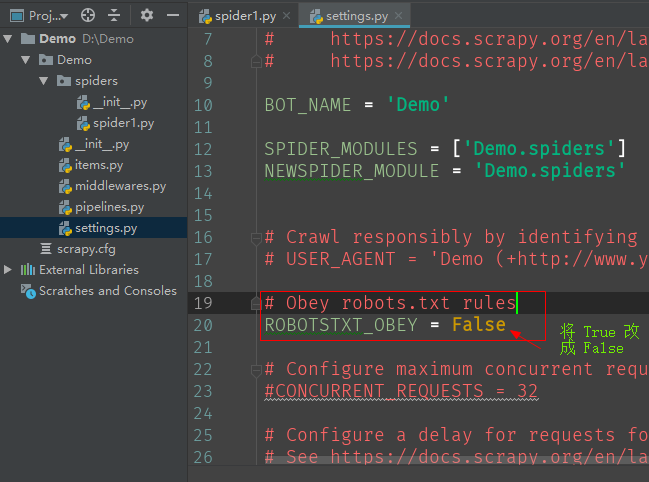
这样就可以获取到百度首页的响应了。
6、运行爬虫文件
scrapy crawl 爬虫文件名 --nolog # 运行爬虫文件
# --nolg 表示不显示scrapy爬取过程日志。去掉--nolog就可以查看爬取的详细过程
必须在命令行cmd或Pycharm终端Terminal中输入命令,才能运行爬虫文件。还需确认是否在项目文件的最高层目录下。
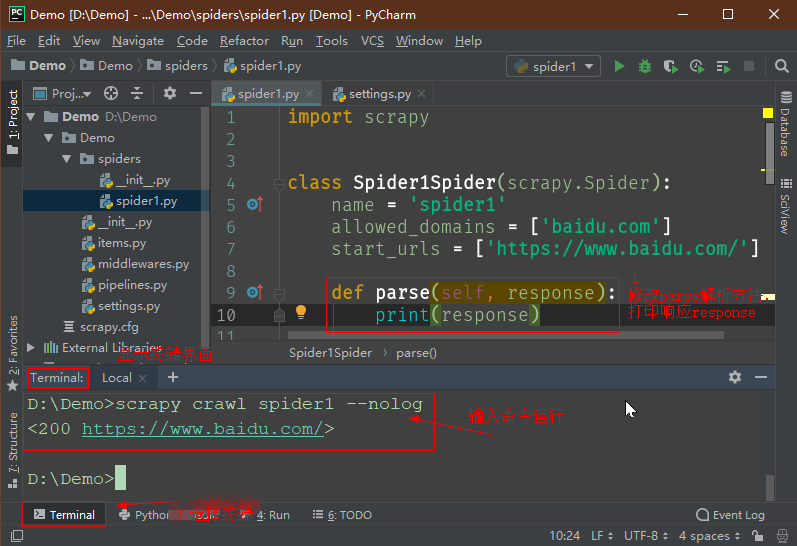
打开爬虫文件,修改parse方法,让其打印response响应,然后运行爬虫文件。如图是在Pycharm中运行。
如果得不到响应,可能还需要设置用户代理。
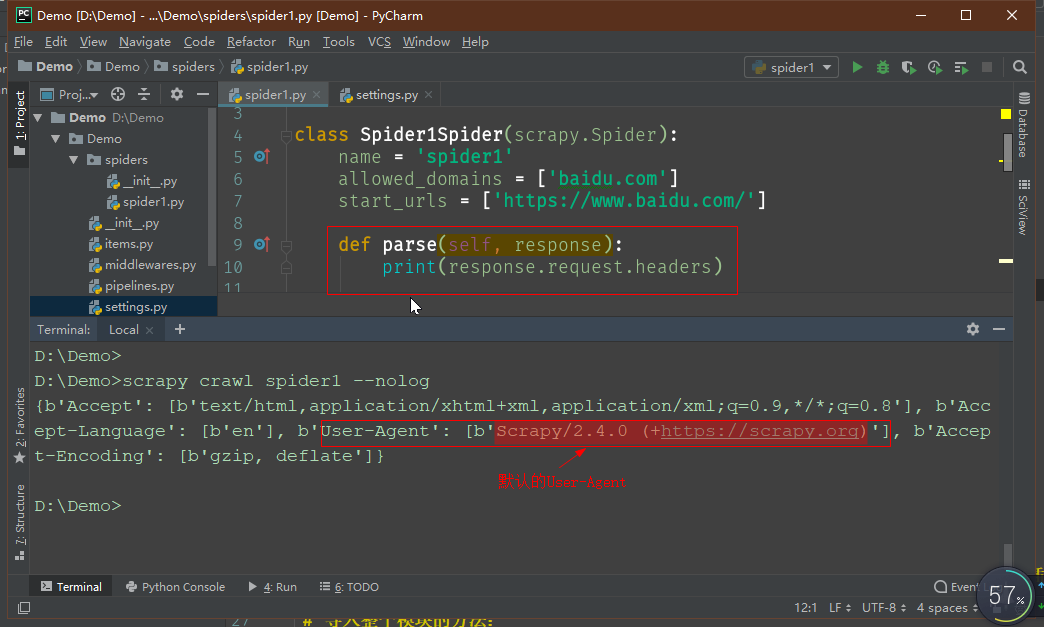
在命令行cmd中运行

6、设置用户代理
# settings.py
USER_AGENT = '' # 设置用户代理 user-agnet
未设置user-agent,默认使用:
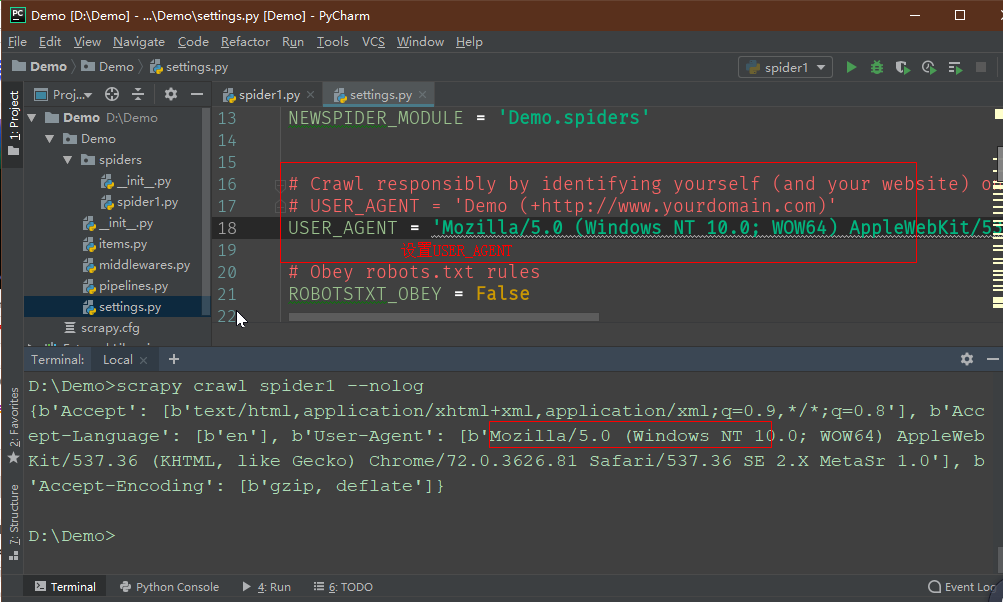
还是打开那个settings.py文件,可以找到被注释的USER_AGENT,复制名称,设置用户代理:
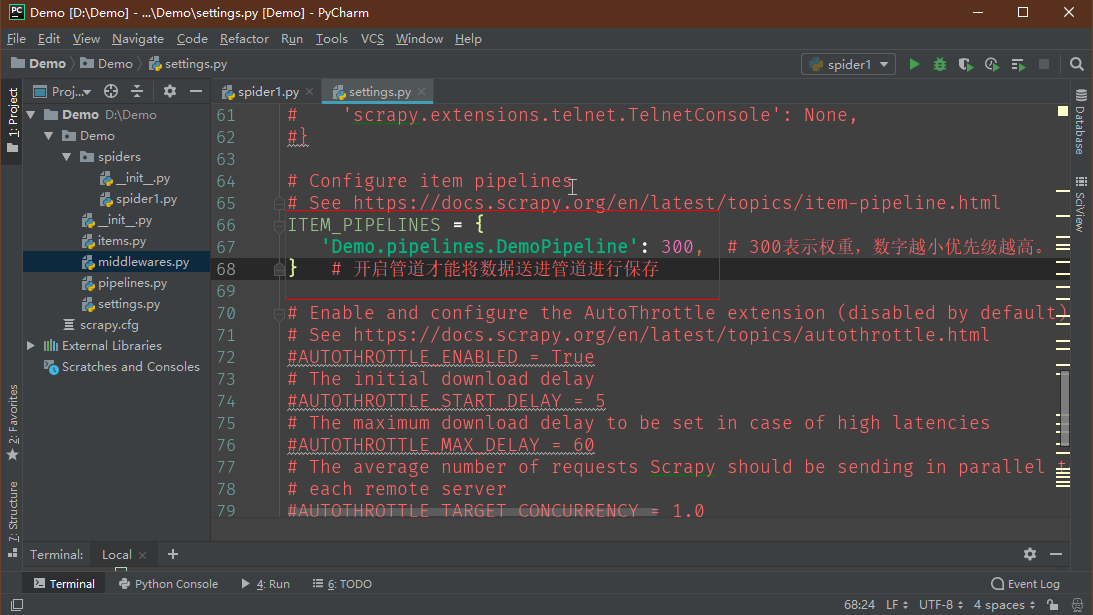
7、打开管道
打开settings.py文件,找到 ITEM 开头的,取消其注释
8、解析数据
这里以抓取百度热榜为例。scrapy提供的response可以直接调用xpath。
但是返回的列表元素是对象,需要使用再调用getall()获取目标字符串列表
responde.xpath() # 返回一个列表,但列表元素是其他对象,而不是字符串 responde.xpath().getall() # 返回一个列表,由目标字符串组成
# 其他解析方法
responde.xpath().extract() # extract()功能与getall()相同
responde.xpath().extract_first() # 返回列表第一个字符串,也就是搜索到的第一个结果
responde.xpath().get() # 返回列表第一个字符串
responde.css('.class::text').getall() # 用css解析,获取class值对应的文本
responde.css('.class::attr("")').get() # css解析,获取class值对应的属性
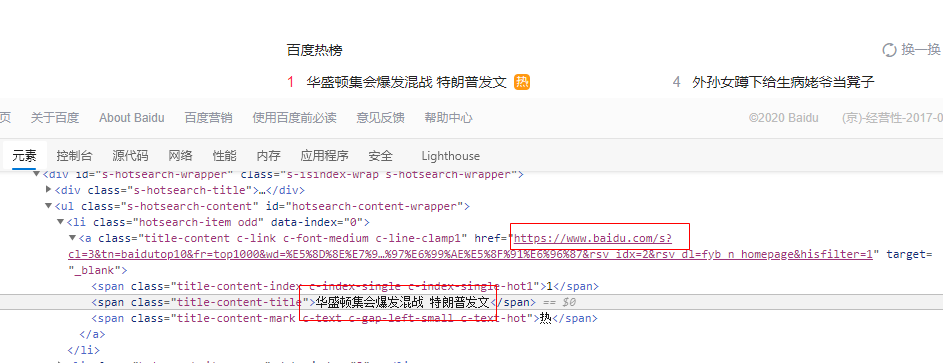
打开百度首页,并定位热榜元素位置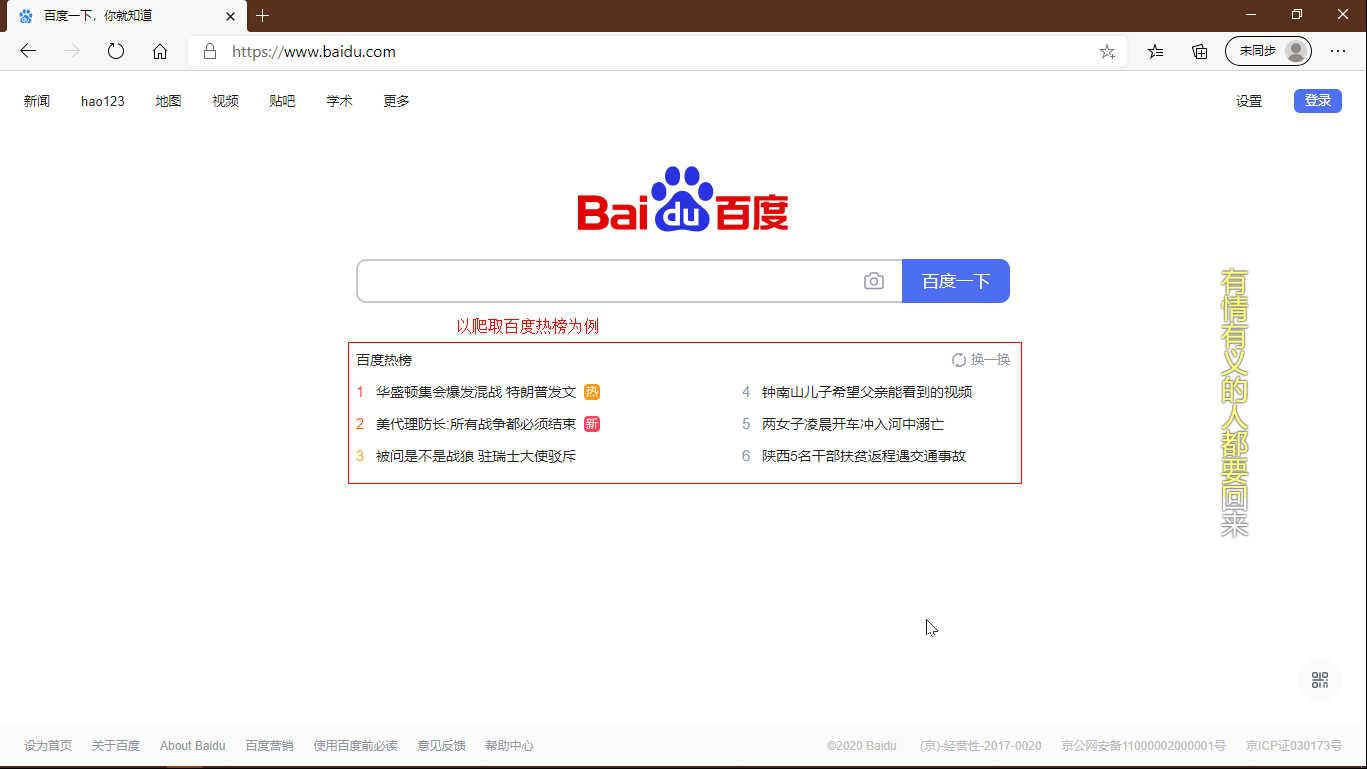
如图所示,在爬虫文件中修改解析方法parse(),利用xpath获取百度热榜标题和链接。
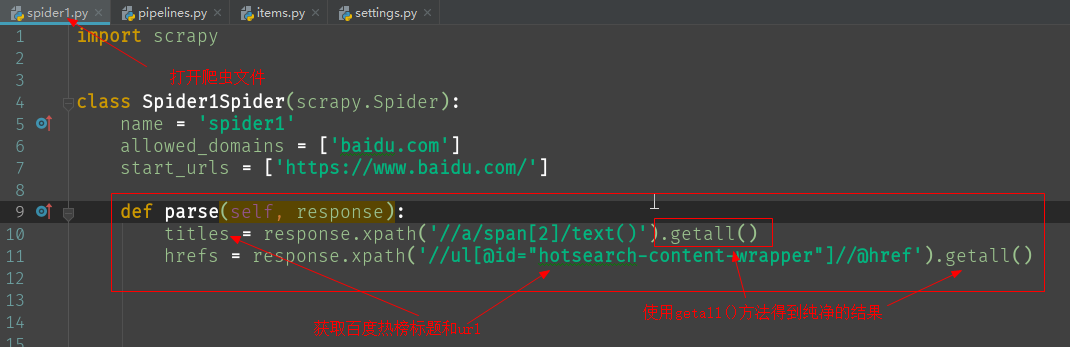
没有调用getall()则返回的是一组对象
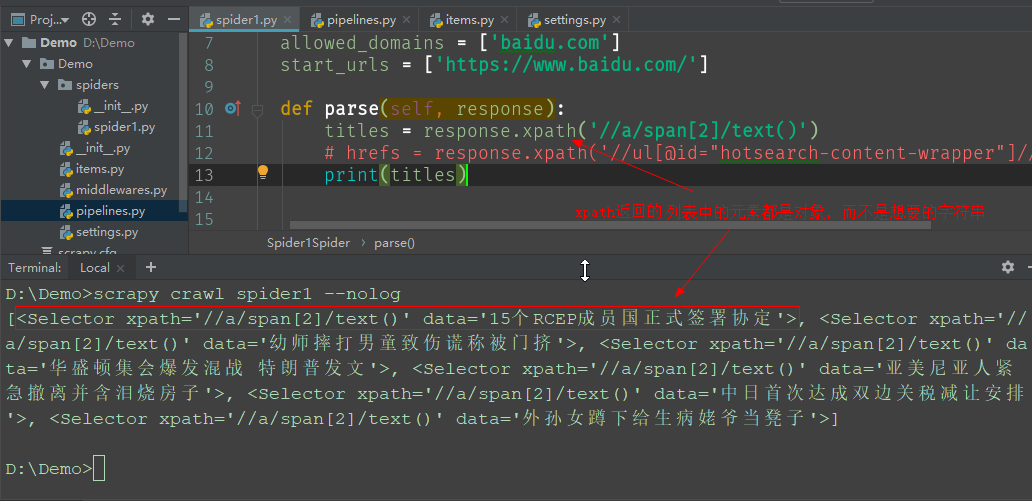
9、设置字段
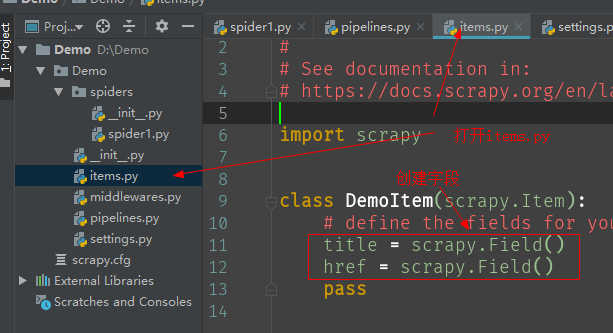
要把获取到的数据通过管道,需要创建字段对象。字段对象被定义在items.py文件中,需要添加字段。
字段 = scrapy.Field() # 添加字段
打开items.py,在DemoItem类定义中添加字段
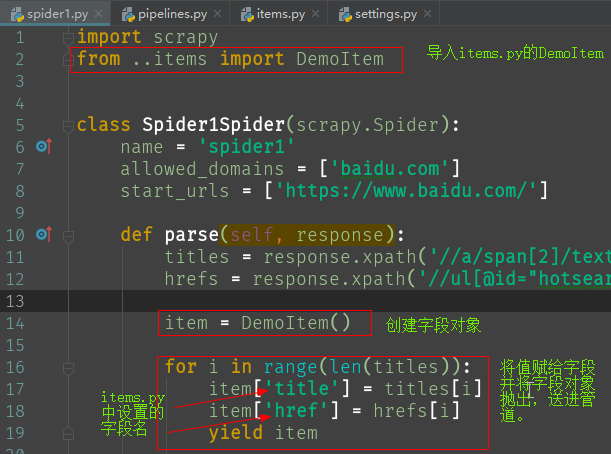
10、创建字段对象,并把数据赋给字段对象,再抛出,送进管道
from ..items import * # 先导入items
item = xxxItem() # 创建字段对象
item['字段'] = 值 # 将值赋给字段对象的一个字段,即类属性。字段对象的使用像极了字典,但键名是先定义好了的。
yield item # 将字段对象送进管道
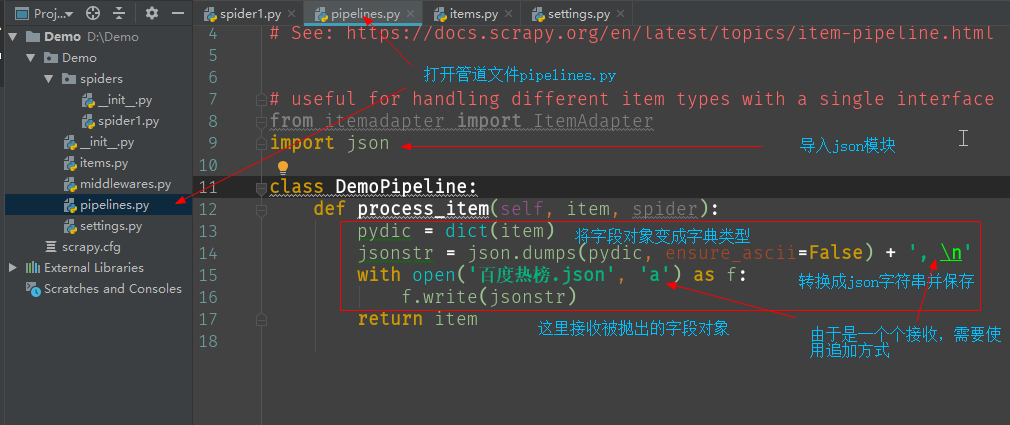
11、修改管道类
进入pipelines.py,添加保存数据的代码。
pydic = dict(item) # 将字段对象转化成字典类型
jsonstr = json.dumps(pydic, ensure_ascii=False) + ', \n' # 保存为json格式
with open('百度热榜.json', 'a') as f: # 写入文件。
f.write(jsonstr)
12、完成。
运行爬虫文件,打开百度热榜.json文件。这篇随笔写了很久,热榜也已经发生变化了。
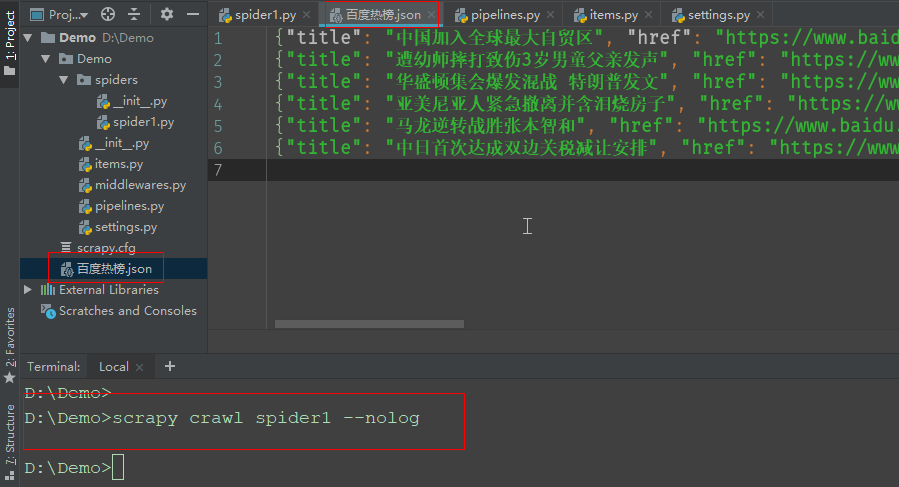
13、不借助管道,直接保存文件
在关闭管道的情况下,在命令行cmd终端输入以下命令会自动将每次抛出的字段对象item保存到文件
scrapy crawll 爬虫文件 -o 保存文件名 --nolog
但是文件无法显示中文,需要修改编码:
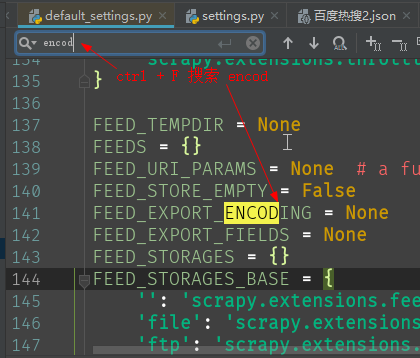
先找到scrapy模块的默认设置文件,搜索encoding。找出默认编码的变量名。复制到项目的settings.py中并修改编码
# scrapy模块在python安装路径下的Lib文件夹下,详细路径如下:
Python\Lib\site-packages\scrapy\settings\default_settings.py
# default_settings.py 中搜索 encod , 并将第一个结果复制到项目settings.py中,修改编码为 utf-8
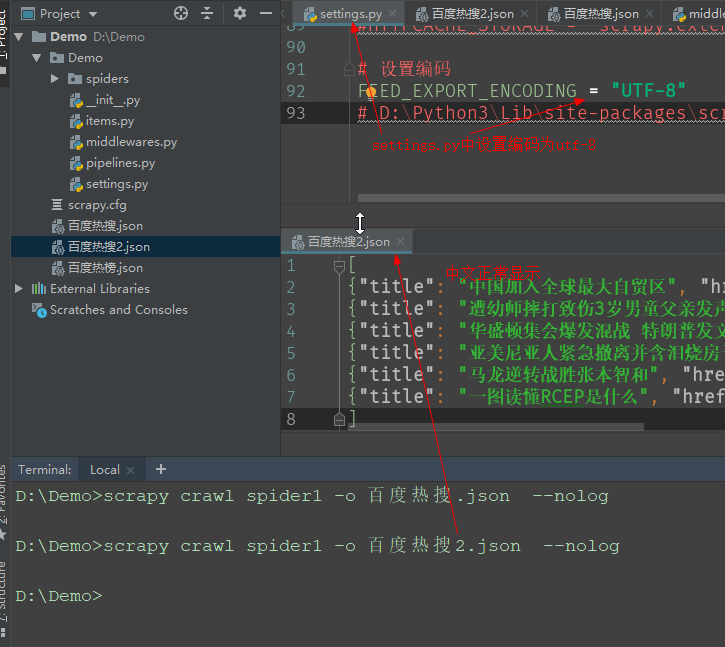
FEED_EXPORT_ENCODING = 'utf-8'
未设置编码得到的文件
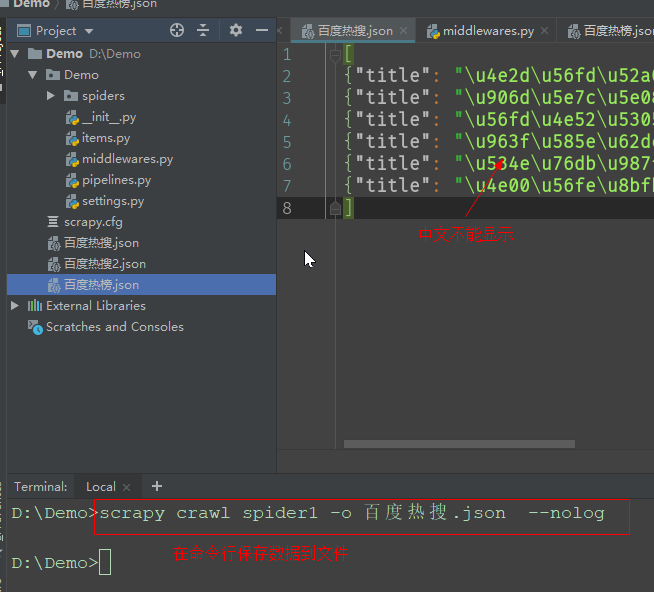
设置编码后得到的文件
14、文件源码
# spider1.py
import scrapy
from ..items import DemoItem
class Spider1Spider(scrapy.Spider):
name = 'spider1'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com/']
def parse(self, response):
titles = response.xpath('//a/span[2]/text()').getall()
hrefs = response.xpath('//ul[@id="hotsearch-content-wrapper"]//@href').getall()
item = DemoItem()
for i in range(len(titles)):
item['title'] = titles[i]
item['href'] = hrefs[i]
yield item
# items.py
import scrapy
class DemoItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
href = scrapy.Field()
pass
# pipelines.py
from itemadapter import ItemAdapter
import json
class DemoPipeline:
def process_item(self, item, spider):
pydic = dict(item)
jsonstr = json.dumps(pydic, ensure_ascii=False) + ', \n'
with open('百度热榜.json', 'a') as f:
f.write(jsonstr)
return item
# settings.py BOT_NAME = 'Demo' SPIDER_MODULES = ['Demo.spiders'] NEWSPIDER_MODULE = 'Demo.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent # USER_AGENT = 'Demo (+http://www.yourdomain.com)' USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 SE 2.X MetaSr 1.0' # Obey robots.txt rules ROBOTSTXT_OBEY = False # Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'Demo.pipelines.DemoPipeline': 300, # 300表示权重,数字越小优先级越高。 } # 开启管道才能将数据送进管道进行保存
