storm案例分析
wordcount例子
sqout组件
package com.xiaojie.mm;
import java.util.Map;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
public class MySpout extends BaseRichSpout {
//collector收集spout发出的数据tuple
SpoutOutputCollector collector;
@Override
public void nextTuple() {
//storm不断地发数据给bolt
collector.emit(new Values("i am miao ying jie w am mm"));
}
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
//初始化方法,storm框架只会调用一次
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//bolt中使用getStringByField拿数据时根据这个Fields拿Values里面对应位置的值;
//declare和emit方法里的参数位置对应
declarer.declare(new Fields("test1"));
}
}
bolt组件(1)
package com.xiaojie.mm;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class MySplitBolt extends BaseRichBolt {
OutputCollector collector;
@Override
public void execute(Tuple input) {
//storm框架循环调用该方法
String line = input.getString(0);
//拿test1对应的value
//input.getStringByField("test1");
String[] split = line.split(" ");
for(String word:split) {
collector.emit(new Values(word,1));
}
}
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
//初始化方法
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//word对应emit里面的word number对应emit里面的1
declarer.declare(new Fields("word","number"));
}
}
bolt组件(2)
package com.xiaojie.mm;
import java.util.HashMap;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Tuple;
public class MyCountBolt extends BaseRichBolt {
OutputCollector collector;
Map<String,Integer> map = new HashMap<String, Integer>();
@Override
public void execute(Tuple input) {
String word = input.getString(0);
Integer number = input.getInteger(1);
if(map.containsKey(word)) {
Integer count = map.get(word);
map.put(word, count+number);
}else {
map.put(word, number);
}
// System.out.println("count:"+map);
}
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
//初始化方法
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer arg0) {
//不输出就不写
}
}
驱动方法
package com.xiaojie.mm;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
public class WordCountTopologyMain {
public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException {
TopologyBuilder topologyBuilder = new TopologyBuilder();
//第一个参数是给spout起的名字 1表示启动一个mySpout
topologyBuilder.setSpout("mySpout", new MySpout(),1);
//shuffleGrouping表示mySpout发出的数据随机分发给myBolt1 2表示启动两个myBolt1
topologyBuilder.setBolt("myBolt1", new MySplitBolt(),2).shuffleGrouping("mySpout");
//根据myBolt1的发出的数据中的word属性进行分发 根据该字段的值进行hash算法分发,相同的单词会发给同一个bolt
topologyBuilder.setBolt("myBolt2", new MyCountBolt(),2).fieldsGrouping("myBolt1",new Fields("word"));
//==========================================================================================
builder.setSpout("spout", new RandomSentenceSpout(), 5).setNumTasks(6);
//executors数目设置为5,即线程数为5,task为6,1个线程可以执行1个component的1个或多个task实例
builder.setBolt("split", new SplitSentence(), 8).shuffleGrouping("spout");
//executors数目设置为8,即线程数为8,task默认和线程数相同为8
builder.setBolt("count", new WordCount(), 4).fieldsGrouping("spout", new Fields("word")).setNumTasks(2);
//executors数目设置为4,即线程数为4,executor的数量必须小于等于task的数量,如果分配的executor的线程数比task数量多的话也只能分配和task数量相等的executor,所以只能分配2个线程executor的数量必须小于等于task的数量!
//============================================================================================
Config config = new Config();
//设置需要几个worker
config.setNumWorkers(2);
//本地模式
// LocalCluster localCluster = new LocalCluster();
//给该任务起个名字mywordcount
// localCluster.submitTopology("mywordcount", config, topologyBuilder.createTopology());
//集群模式
StormSubmitter.submitTopology("mywordcount", config, topologyBuilder.createTopology());
}
}
topology与worker,excutor,task的关系
- Storm集群中的其中1台机器可能运行着属于多个拓扑(可能为1个)的多个worker进程(可能为1个)。每个worker进程运行着特定的某个拓扑的executors。
- 1个或多个excutor可能运行于1个单独的worker进程,每1个executor从属于1个被worker process生成的线程中。每1个executor运行着相同的组件(spout或bolt)的1个或多个task。
- executor的数量必须小于等于task的数量,如果分配的executor的线程数比task数量多的话也只能分配和task数量相等的executor
配置并发度
-
对于并发度的配置, 在storm里面可以在多个地方进行配置, 优先级为:
defaults.yaml < storm.yaml < topology-specific configuration
< internal component-specific configuration < external component-specific configuration -
worker processes的数目, 可以通过配置文件和代码中配置, worker就是执行进程, 所以考虑并发的效果, 数目至少应该大亍machines的数目.
-
executor的数目, component的并发线程数,只能在代码中配置(通过setBolt和setSpout的参数), 例如, setBolt("green-bolt", new GreenBolt(), 2)
-
tasks的数目, 可以不配置, 默认和executor1:1, 也可以通过setNumTasks()配置.
-
Topology的worker数通过config设置,即执行该topology的worker(java)进程数。它可以通过 storm rebalance 命令任意调整。
Config conf = newConfig(); conf.setNumWorkers(2); //用2个worker topologyBuilder.setSpout("blue-spout", newBlueSpout(), 2); //设置2个并发度 topologyBuilder.setBolt("green-bolt", newGreenBolt(), 2).setNumTasks(4).shuffleGrouping("blue-spout"); //设置2个并发度,4个任务 topologyBuilder.setBolt("yellow-bolt", newYellowBolt(), 6).shuffleGrouping("green-bolt"); //设置6个并发度 StormSubmitter.submitTopology("mytopology", conf, topologyBuilder.createTopology());
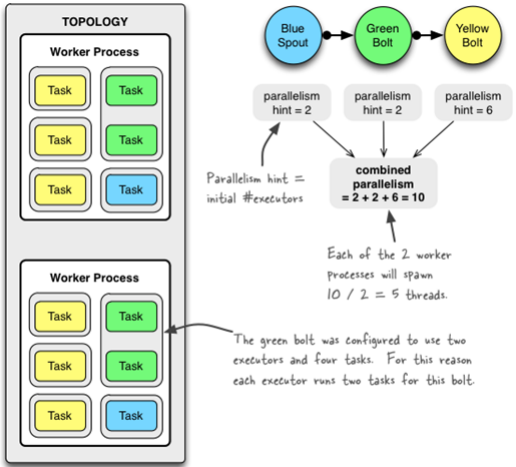
3个组件的并发度加起来是10,就是说拓扑一共有10个executor,一共有2个worker,每个worker产生10 / 2 = 5条线程。
绿色的bolt配置成2个executor和4个task。为此每个executor为这个bolt运行2个task。
Storm支持在不 restart topology 的情况下, 动态的改变(增减) worker processes 的数目和 executors 的数目, 称为rebalancing. 通过Storm web UI,或者通过storm rebalance命令实现:
storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10
Stream Grouping详解
Storm里面有7种类型的stream grouping
- Shuffle Grouping: 随机分组, 随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。
- Fields Grouping:按字段分组,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts里的一个task,而不同的userid则会被分配到不同的bolts里的task。
- All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。
- Global Grouping:全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
- Non Grouping:不分组,这stream grouping个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
- Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)。
- Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发送给这些tasks。否则,和普通的Shuffle Grouping行为一致。
storm通信机制
Worker间的通信经常需要通过网络跨节点进行,Storm使用ZeroMQ或Netty(0.9以后默认使用)作为进程间通信的消息框架。
Worker进程内部通信:不同worker的thread通信使用LMAX Disruptor来完成。
不同topologey之间的通信,Storm不负责,需要自己想办法实现,例如使用kafka等;
worker进程间通信
-
对于worker进程来说,为了管理流入和传出的消息,每个worker进程有一个独立的接收线程,一个worker进程运行一个专用的接收线程来负责将外部发送过来的消息移动到对应的executor线程的incoming-queue中,(对配置的TCP端口supervisor.slots.ports进行监听);
-
对应Worker接收线程,每个worker存在一个独立的发送线程[transfer-queue的大小由参数topology.transfer.buffer.size来设置。transfer-queue的每个元素实际上代表一个tuple的集合],它负责从worker的transfer-queue中读取消息,并通过网络发送给其他worker.
-
每个executor有自己的incoming-queue[executor的incoming-queue的大小用户可以自定义配置。]和outgoing-queue[executor的outgoing-queue的大小用户可以自定义配置]。
-
Worker接收线程将收到的消息通过task编号传递给对应的executor(一个或多个)的incoming-queues;
-
每个executor有单独的线程分别来处理spout/bolt的业务逻辑,业务逻辑输出的中间数据会存放在outgoing-queue中,当executor的outgoing-queue中的tuple达到一定的阀值,executor的发送线程将批量获取outgoing-queue中的tuple,并发送到transfer-queue中。
-
每个worker进程控制一个或多个executor线程,用户可在代码中进行配置。其实就是我们在代码中设置的并发度个数。
通信分析
1、Worker接受线程通过网络接受数据,并根据Tuple中包含的taskId,匹配到对应的executor;然后根据executor找到对应的incoming-queue,将数据存发送到incoming-queue队列中。
2、业务逻辑执行现成消费incoming-queue的数据,通过调用Bolt的execute(xxxx)方法,将Tuple作为参数传输给用户自定义的方法.
3、业务逻辑执行完毕之后,将计算的中间数据发送给outgoing-queue队列,当outgoing-queue中的tuple达到一定的阀值,executor的发送线程将批量获取outgoing-queue中的tuple,并发送到Worker的transfer-queue中.
4、Worker发送线程消费transfer-queue中数据,计算Tuple的目的地,连接不同的node+port将数据通过网络传输的方式传送给另一个的Worker。
5、另一个worker执行以上步骤1的操作。
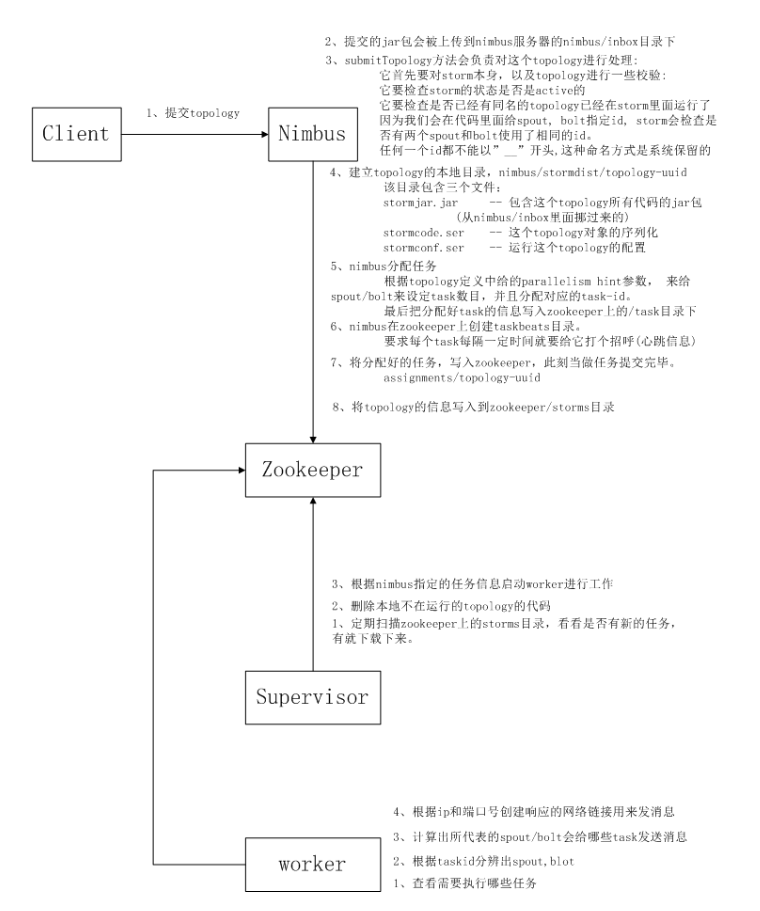
storm任务提交
storm容错机制(ack-fail)
假设我们在这个系统中有一种spout和一种bolt,如果你不使用ack-fail机制那么一个spout中有三个方法,分别是
open(),nextTuple()和outputFields()
open的作用是初始化那个outputCollector,nextTuple方法就是不断地取值然后发给下一个bolt或者就结束了,declareOutputFields方法就是声明一下我发射出去的数据id,如果你使用了ack-fail机制那就多了俩方法,ack()和fail(),发送成功了就调ack方法,不成功就调fail,你在fail里可以进行重发或者什么的,当然这些都是你自己决定,你要是不想做处理函数里就啥都不写,我们这里进行重发:
Myspout{
Map<String,Values> buffer = new HashMap<>(); //缓存正在发送的tuple
open();
nextTuple(){
String messageId = UUID.randomUUID().toString().replace("-", ""); //随机生成一个msgid
buffer.put(messageId,tuple); //放到缓存中
collector.emit(value,messageId); //发射出去
}
fail(Object msgid){
String value = buffer.get(msgid); //取出value
collector.emit(value,msgid); //重发
}
ack(Object msgid){
buffer.remove(msgid); //从buffer中拿出来
}
declareOutputFields();
}
MyBolt方法本来的三个方法是prepare(),execute(),declareOutputFields()
prepare方法主要也就是初始化那个outputCollector,execute方法就是执行处理过程,declareOutputFields也一样就是声明一下我发出去的是啥,而在应用了ack-fail机制的bolt中,这里要显示的声明我处理完了:
MyBolt{
void execute(Tuple input){
collector.emit(input,value);
collector.ack(input);
}
}
然后是ack-fail的处理过程方面:
spout---->tuple1---->bolt1---->ack(tuple1)
bolt1---->tuple1-1---->bolt2-1---->ack(tuple1-1);
bolt1---->tuple1-2---->bolt2-1---->ack(tuple1-2);
..........................
只有当每一个bolt都正确ack了,整个发送过程才算成功,任何一个bolt处理不成功,则不成功,重新处理。
那么ack这个东西他如何判断前者发射的tuple和ack返回的tuple是不是同一个呢,这里主要的概念是异或处理,对于每一个spout发射任务,ack维护了这样一组数据.
<spoutTaskId,<RootID,ackValue>>
spoutTaskId标志着唯一的一个spouttask,RootId标志着整个过程的结果,ackValue记录着整个过程中不同的tuple相异或的时候结果的变化,当ackValue最终等于0的时候,就标志着整个过程成功了,那么这个RootID如何计算呢,我们知道每一个tuple的发射过
程bolt都给了相应的返回tupleid,当这两个tupleid相同时就表明这一小阶段的任务完成了,而tuplid转化成二进制是0101形式的,如果返回的tupleid和这个发送的tupleid相异或等于0,也就是ackValue等于0,就证明这两个是同一个id,也就表明这一小部分的任务成功了,但是整个过程中可能会有多层bolt,每一个bolt的执行速度可能不同,所以注意,如果这些所有结果相异或后,ackValue等于0,就表明这个传输任务完成了。
最后我们来从底层实现来讲一下ack-fail机制:
我们运行storm程序时会发现有这样一个任务-ackTask,看一下源码他是继承了Bolt,他就是一个和其他数据处理的bolt一起存在一起处理的进程,而实际上整个过程中是存在两种tuple的,分别是DataTuple和AckTuple,DataTuple主要负责数据的处理,AckTuple负责整个过程的排错,我们先来看这个AckTuple,
他其实封装了AckTuple<RootID,tupleId>,RootID标识了这个tuple属于哪个过程,而tupleId标识了每一个特定的tuple,这个AckTuple最终封装成一个messageId这样一个对象,而DataTuple中就含有这个messageId。接下来我们来看整个过程,两种线程是一起进行的,ack的线程比较简单,当spout发射一个DataTuple时同时就会发射一个AckTuple,然后他就在这等待响应,spout将DataTuple(messageId(AckTuple))发送给bolt,bolt.execute(dataTuple)。之后会应答也就是bolt.ack(dataTuple),而dataTuple中封装了ackTuple,就可以还原出这个ackTuple,这样acktask就等到了ack应答,也就是说这一阶段处理成功,以此类推。
上述过程示意:
spout.emit(dataTuple(messageId(ackTuple)))--->bolt.excute--->bolt.ack(dataTuple(ackTuple))
spout.emit(ackTuple)
关闭ack-fail机制
- 将参数Config.TOPOLOGY_ACKERS设置为0,通过此方法,当Spout发送一个消息的时候,它的ack方法将立刻被调用;
- Spout发送一个消息时,不指定此消息的messageID。当需要关闭特定消息可靠性的时候,可以使用此方法;
- 最后,如果你不在意某个消息派生出来的子孙消息的可靠性,则此消息派生出来的子消息在发送时不要做锚定,即在emit方法中不指定输入消息。因为这些子孙消息没有被锚定在任何tuple tree中,因此他们的失败不会引起任何spout重新发送消息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号