一、新手必会Python基础
博客内容:
1、基础语法
2、运算符
3、流程控制
4、列表、元组、字典、集合
5、字符串
6、文件操作
一、基础语法
1、标识符
命名规则:
- 以字母、下划线开头
- 其他部分由字母、数字或下划线组成
- 不能使用关键字命名;
- 常量一般全部是大写;
- 命名要有意义,不宜过长。
定义:可以改变的量:
age=19 #定义一个名为age的量,他的值为19
常量:不可以改变的量(命名字母全大写)
2、注释
Python中单行注释以 # 开头
行注释可以用多个 # 号,还有 ''' 和 """
![]() 注释# 单行注释 ''' 多行注释 ''' """ 多行注释 """
注释# 单行注释 ''' 多行注释 ''' """ 多行注释 """

3、行与缩进
python缩进来表示代码块,不使用大括号 {} 。
缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。
4、数字(Number)类型
python中数字有四种类型:整数、布尔型、浮点数和复数。
- int (整数), 如 1
- bool (布尔), 如 True
- float (浮点数), 如 1.23、3E-2
- complex (复数), 如 1 + 2j、 1.1 + 2.2j
age = 19
ps:类型的转换
- int(x) 将x转换为一个整数。
- float(x) 将x转换到一个浮点数。
- complex(x) 将x转换到一个复数,实数部分为 x,虚数部分为 0。
- complex(x, y) 将 x 和 y 转换到一个复数,实数部分为 x,虚数部分为 y。x 和 y 是数字表达式。
5、字符串(String)
"oeasys"
- python中单引号和双引号使用完全相同。
- 使用三引号('''或""")可以指定一个多行字符串
- 转义符 '\' 反斜杠可以用来转义
- Python中的字符串不能改变
- 字符串可以用 + 运算符连接在一起,用 * 运算符重复以及格式化输出
ps:格式化输出
字符串 %s;整数 %d、;浮点数%f
name = "oeasys" print ("i am %s " ,% name) #输出: i am oeasys
6、布尔值
一个True(真)
一个False(假)
7、用户输入与输出
input() 等待用户输入
print() 打印输出
二、运算符
1、Python算术运算符

2、Python比较运算符

3、Python赋值运算符
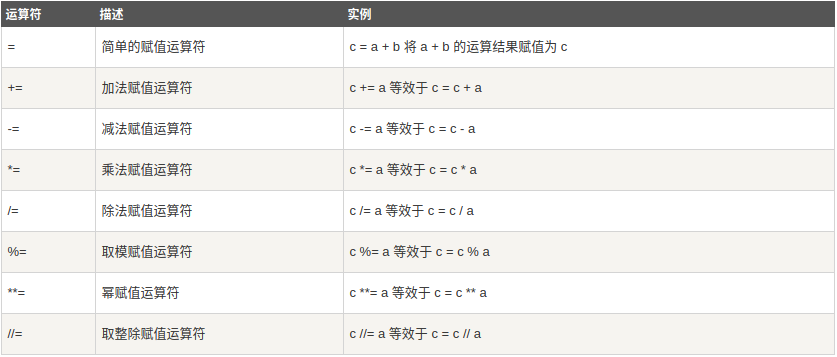
4、Python位运算符

5、Python逻辑运算符

6、Python成员运算符

7、Python身份运算符

8、Python运算符优先级
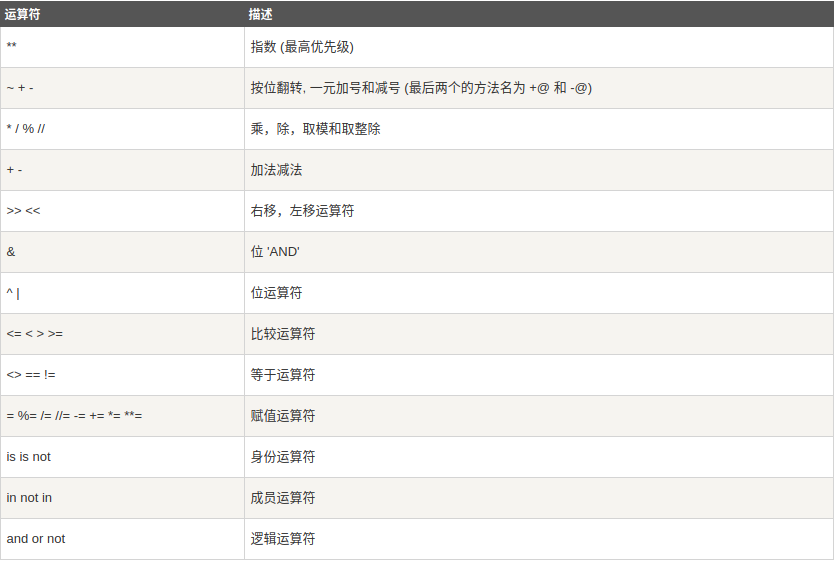
三、流程控制
1、条件控制
![]() if-elif-else1 if 如果: # 如果为真,执行如果代码 2 执行如果代码 3 elif 否则如果: # 否则如果为真,执行否则如果代码 4 执行否则如果代码 5 else: # 前面都不为真,执行否则代码 6 执行否则代码
if-elif-else1 if 如果: # 如果为真,执行如果代码 2 执行如果代码 3 elif 否则如果: # 否则如果为真,执行否则如果代码 4 执行否则如果代码 5 else: # 前面都不为真,执行否则代码 6 执行否则代码![]() 三元运算1 result = 值1 if 条件 else 值2 2 3 # 如果条件成立,那么将 “值1” 赋值给result变量,否则,将“值2”赋值给result变量
三元运算1 result = 值1 if 条件 else 值2 2 3 # 如果条件成立,那么将 “值1” 赋值给result变量,否则,将“值2”赋值给result变量
2、循环控制
1、while 循环
while 判断条件:
语句
2、while 循环使用 else 语句
while 如果为真: # 如果为真,执行循环语句 执行循环语句 else: #while循环为假,执行否则语句 执行否则语句
3、for 语句
for i in range(10):
执行语句
ps:range()函数
内置range()函数,它会生成数列
![]() 1 for i in range(5): 2 print(i) 3 ... 4 0 5 1 6 2 7 3 8 4
1 for i in range(5): 2 print(i) 3 ... 4 0 5 1 6 2 7 3 8 4使用range指定区间的值
![]() 1 for i in range(5,9) : 2 print(i) 3 4 5 5 6 6 7 7 8 8
1 for i in range(5,9) : 2 print(i) 3 4 5 5 6 6 7 7 8 8range以指定数字开始并指定不同的增量(甚至可以是负数,有时这也叫做'步长')
![]() 1 for i in range(0, 10, 3) : 2 print(i) 3 4 5 0 6 3 7 6 8 9
1 for i in range(0, 10, 3) : 2 print(i) 3 4 5 0 6 3 7 6 8 9您可以结合range()和len()函数以遍历一个序列的索引
![]() 1 a = ['Google', 'Baidu', 'Runoob', 'Taobao', 'QQ'] 2 for i in range(len(a)): 3 ... print(i, a[i]) 4 ... 5 0 Google 6 1 Baidu 7 2 Runoob 8 3 Taobao 9 4 QQ
1 a = ['Google', 'Baidu', 'Runoob', 'Taobao', 'QQ'] 2 for i in range(len(a)): 3 ... print(i, a[i]) 4 ... 5 0 Google 6 1 Baidu 7 2 Runoob 8 3 Taobao 9 4 QQrange()函数来创建一个列表
![]() 1 >>>list(range(5)) 2 [0, 1, 2, 3, 4]
1 >>>list(range(5)) 2 [0, 1, 2, 3, 4]
enumerate:枚举,对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值。

1 li = ['张三','李四','王五','小明','18'] 2 for i in enumerate(li): 3 print(i) 4 for index,name in enumerate(li,1): 5 print(index,name) 6 for index, name in enumerate(li, 100): # 起始位置默认是0,可更改 7 print(index, name)
4、break和continue语句
- break 语句可以跳出 for 和 while 的循环体
- continue语句被用来告诉Python跳过当前循环块中的剩余语句,然后继续进行下一轮循环。
5、pass 语句
Python pass是空语句,是为了保持程序结构的完整性。
pass 不做任何事情,一般用做占位语句
四、列表、元组、字典、集合
1、列表
创建列表
names = ['张三',"李四",'王五']通过下标访问列表中的元素,下标从0开始计数
>>> names[0] '张三' >>> names[2] '王五' >>> names[-1] '王五' >>> names[-2] #还可以倒着取 '李四'
1 >>> num = ["1","2","3","4","5","6"] 2 >>> num[1:4] #取下标1至下标4之间的数字,包括1,不包括4 3 ['2', '3', '4'] 4 >>> num[1:-1] #取下标1至-1的值,不包括-1 5 ['2', '3', '4', '5'] 6 >>> num[0:3] 7 ['1', '2', '3'] 8 >>> num[:3] #如果是从头开始取,0可以忽略,跟上句效果一样 9 ['1', '2', '3'] 10 >>> num[3:] #如果想取最后一个,必须不能写-1,只能这么写 11 ['4', '5', '6'] 12 >>> num[3:-1] #这样-1就不会被包含了 13 ['4', '5'] 14 >>> num[0::2] #后面的2是代表,每隔一个元素,就取一个 15 ['1', '3', '5'] 16 >>> num[::2] #和上句效果一样 17 ['1', '3', '5']
1 num = ['1', '2', '3', '4', '5', '6'] 2 >>> num.append("7") 3 >>> num 4 ['1', '2', '3', '4', '5', '6', '7']
1 >>> num = ['1', '2', '3', '4', '5', '6', '7'] 2 >>> num.insert(2,"强行从3前面插入") 3 >>> num 4 ['1', '2', '强行从3前面插入', '3', '4', '5', '6', '7']
1 >>> num = ['1', '2', '3', '4', '5'] 2 >>> num[2] = "new" 3 >>> num 4 ['1', '2', 'new', '3', '4', '5']
1 >>> mun = ['1', '2', '3', '4', '5', '6', '7'] 2 >>>del num[2] 3 >>> num 4 num = ['1', '2', '3', '4', '5', '6', '7'] 5 6 7 8 >>> num.remove("4") #删除指定元素 9 >>> num 10 ['1', '2', '5', '6', '7'] 11 >>> num.pop() #删除列表最后一个值 12 '7' 13 >>> nun 14 ['1', '2', '5', '6']
1 >>> num = ['1', '2', '3', '4', '5'] 2 >>> num1 = [1,2,3] 3 >>> num.extend(num1) 4 >>> num 5 ['1', '2', '3', '4', '5', 1, 2, 3]
1 >>> num = ['1', '2', '3', '4', '5', 1, 2, 3] 2 3 >>> num_copy = num.copy() 4 >>> num_copy 5 ['1', '2', '3', '4', '5', 1, 2, 3]
1 >>> num = ['1', '2', '3', '4', '5','2'] 2 >>> num.count("2") 3 2
1 >>> num = ['4', '2', '1','9', '7', '5'] 2 >>> num.sort() 3 >>> num 4 ['1', '2', '4', '5', '7', '9']
1 >>> num = ['4', '2', '1','9', '7', '5'] 2 >>> num.reverse() 3 >>> num 4 ['5', '7', '9', '1', '2', '4']
1 >>> num = ['4', '2', '1','9', '7', '5'] 2 >>> num.index('9') 3 3
2、元组
Python 的元组与列表类似,元组的元素不能修改,又叫只读列表。
num = ("1","2","3")
只有2个方法:一个是count,一个是index
3、字典
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中
字典是无序的,key是唯一的
1 names = { 2 'name1': "zhangsan", 3 'name2': "李四", 4 'name3': "王五", 5 }
1 names = { 2 'name1': "zhangsan", 3 'name2': "李四", 4 'name3': "王五", 5 } 6 names["name4"] = "wangwu"
1 name['name2'] = "张三"
info.pop("name2") #删除方法1 del info['name3'] #删除方法2 info.popitem() #随机删除
1 >>> "name1" in names #查找1 2 True 3 >>> names.get("name2") #获取 4 5 >>> names["name9"] #获取,但是如果key不存在,就报错
1 values() 函数以列表返回字典中的所有值 2 3 keys() 函数以列表返回一个字典所有的键 4 5 setdefault(key,default) 函数, 如果键不存在于字典中,将会添加键并将值设为默认值 6 key -- 查找的键值。 7 default -- 键不存在时,设置的默认键值。 8 9 update() 函数把字典dict2的键/值对更新到dict里。 10 11 items() 函数以列表返回可遍历的(键, 值) 元组数组 12 13 has_key() 函数用于判断键是否存在于字典中,如果键在字典dict里返回true,否则返回false。 14 15 fromkeys() 函数用于创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值。 16 17 copy() 函数返回一个字典的浅复制。
| 序号 | 函数及描述 |
|---|---|
| 1 | cmp(dict1, dict2) 比较两个字典元素。 |
| 2 | len(dict) 计算字典元素个数,即键的总数。 |
| 3 | str(dict) 输出字典可打印的字符串表示。 |
| 4 | type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。 |
| 序号 | 函数及描述 |
|---|---|
| 1 | dict.clear() 删除字典内所有元素 |
| 2 | dict.copy() 返回一个字典的浅复制 |
| 3 | dict.fromkeys(seq[, val]) 创建一个新字典,以序列 seq 中元素做字典的键,val 为字典所有键对应的初始值 |
| 4 | dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值 |
| 5 | dict.has_key(key) 如果键在字典dict里返回true,否则返回false |
| 6 | dict.items() 以列表返回可遍历的(键, 值) 元组数组 |
| 7 | dict.keys() 以列表返回一个字典所有的键 |
| 8 | dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | dict.update(dict2) 把字典dict2的键/值对更新到dict里 |
| 10 | dict.values() 以列表返回字典中的所有值 |
| 11 | pop(key[,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| 12 | popitem() 随机返回并删除字典中的一对键和值。 |
4、集合
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
1 s = set([3,5,9,10]) #创建一个数值集合 2 3 t = set("Hello") #创建一个唯一字符的集合 4 5 6 a = t | s # t 和 s的并集 7 8 b = t & s # t 和 s的交集 9 10 c = t – s # 求差集(项在t中,但不在s中) 11 12 d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中) 13 14 15 16 基本操作: 17 18 t.add('x') # 添加一项 19 20 s.update([10,37,42]) # 在s中添加多项 21 22 23 24 使用remove()可以删除一项: 25 26 t.remove('H') 27 28 29 len(s) 30 set 的长度 31 32 x in s 33 测试 x 是否是 s 的成员 34 35 x not in s 36 测试 x 是否不是 s 的成员 37 38 s.issubset(t) 39 s <= t 40 测试是否 s 中的每一个元素都在 t 中 41 42 s.issuperset(t) 43 s >= t 44 测试是否 t 中的每一个元素都在 s 中 45 46 s.union(t) 47 s | t 48 返回一个新的 set 包含 s 和 t 中的每一个元素 49 50 s.intersection(t) 51 s & t 52 返回一个新的 set 包含 s 和 t 中的公共元素 53 54 s.difference(t) 55 s - t 56 返回一个新的 set 包含 s 中有但是 t 中没有的元素 57 58 s.symmetric_difference(t) 59 s ^ t 60 返回一个新的 set 包含 s 和 t 中不重复的元素 61 62 s.copy() 63 返回 set “s”的一个浅复制
五、字符串
1、Python转义字符
| 转义字符 | 描述 |
|---|---|
| \(在行尾时) | 续行符 |
| \\ | 反斜杠符号 |
| \' | 单引号 |
| \" | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,yy代表的字符,例如:\o12代表换行 |
| \xyy | 十六进制数,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
2、Python字符串运算符
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 |
>>>a + b 'HelloPython'
|
| * | 重复输出字符串 |
>>>a * 2 'HelloHello'
|
| [] | 通过索引获取字符串中字符 |
>>>a[1] 'e'
|
| [ : ] | 截取字符串中的一部分 |
>>>a[1:4] 'ell'
|
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True |
>>>"H" in a True
|
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True |
>>>"M" not in a True
|
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母"r"(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 |
>>>print r'\n' \n >>> print R'\n' \n
|
| % | 格式字符串 |
3、Python 字符串格式化
python 字符串格式化符号:
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %F 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
格式化操作符辅助指令:
| 符号 | 功能 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号( + ) |
| <sp> | 在正数前面显示空格 |
| # | 在八进制数前面显示零('0'),在十六进制前面显示'0x'或者'0X'(取决于用的是'x'还是'X') |
| 0 | 显示的数字前面填充'0'而不是默认的空格 |
| % | '%%'输出一个单一的'%' |
| (var) | 映射变量(字典参数) |
| m.n. | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
4、python的字符串内建函数
| 方法 | 描述 |
|---|---|
|
把字符串的第一个字符大写 |
|
|
返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
|
|
返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
|
|
以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除非 errors 指 定 的 是 'ignore' 或 者'replace' |
|
|
以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace' |
|
|
检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
|
|
把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 |
|
|
检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
|
|
格式化字符串 |
|
|
跟find()方法一样,只不过如果str不在 string中会报一个异常. |
|
|
如果 string 至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
|
|
如果 string 至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False |
|
|
如果 string 只包含十进制数字则返回 True 否则返回 False. |
|
|
如果 string 只包含数字则返回 True 否则返回 False. |
|
|
如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
|
|
如果 string 中只包含数字字符,则返回 True,否则返回 False |
|
|
如果 string 中只包含空格,则返回 True,否则返回 False. |
|
|
如果 string 是标题化的(见 title())则返回 True,否则返回 False |
|
|
如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
|
|
以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
|
|
返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
|
|
转换 string 中所有大写字符为小写. |
|
|
截掉 string 左边的空格 |
|
|
maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
|
|
返回字符串 str 中最大的字母。 |
|
|
返回字符串 str 中最小的字母。 |
|
|
有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. |
|
|
把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. |
|
|
类似于 find()函数,不过是从右边开始查找. |
|
|
类似于 index(),不过是从右边开始. |
|
|
返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
|
|
类似于 partition()函数,不过是从右边开始查找 |
|
|
删除 string 字符串末尾的空格. |
|
|
以 str 为分隔符切片 string,如果 num 有指定值,则仅分隔 num+ 个子字符串 |
|
|
按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
|
|
检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. |
|
|
在 string 上执行 lstrip()和 rstrip() |
|
|
翻转 string 中的大小写 |
|
|
返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
|
|
根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 del 参数中 |
|
|
转换 string 中的小写字母为大写 |
|
|
返回长度为 width 的字符串,原字符串 string 右对齐,前面填充0 |
六、文件操作
1、初识⽂件操作
使⽤open()函数来打开⼀个⽂件:open(文件名(路径),mode=“打开文件的方式”,encoding=“字符集utf-8”)
打开⽂件的⽅式: r, w, a, r+, w+, a+, rb, wb, ab, r+b, w+b, a+b 默认使⽤的是r(只读)模式
rb, wb, ab, 用来读取非⽂本⽂件的时候. 比如读取MP3. 图像. 视频等信息的时候就需要⽤到。因为这种数据是没办法直接显⽰出来的. ⽂件上传下载的时候还会⽤到. 以及直播. 实际上都是这种数据.
2、绝对路径和相对路径
1. 绝对路径:从磁盘根⽬录开始⼀直到⽂件名.
2. 相对路径:同⼀个⽂件夹下的⽂件. 相对于当前这个程序所在的⽂件夹⽽⾔. 如果在同 ⼀个⽂件夹中. 则相对路径就是这个⽂件名. 如果在上⼀层⽂件夹. 则要../
3、只读(r, rb)
1 f = open("文件路径.txt",mode="r", encoding="utf-8") # 打开文件 2 content = f.read() # 读取内容,文件大时不要用 3 print(content) # 打印读取的内容 4 f.close() # 关闭文件 5 6 需要注意encoding表⽰编码集. 根据⽂件的实际保存编码进⾏获取数据, 对于我们⽽⾔. 更多的是utf-8.
1 f = open("文件名.txt",mode="rb" ) 2 content = f.read() 3 print(content) 4 f.close() 5 6 rb的作⽤: 在读取非⽂本⽂件的时候. 比如读取MP3. 图像. 视频等信息的时候就需要⽤到 7 rb. 因为这种数据是没办法直接显⽰出来的. 在后⾯我们⽂件上传下载的时候还会⽤到. 还有.我们看的直播. 实际上都是这种数据.
4、只写(w, wb)
1 f = open("文件", mode="w", encoding="utf-8") 2 f.write("oeasys.cn") 3 f.flush() # 刷新 4 f.close()
1 f = open("文件", mode="wb") 2 f.write("oeasys.cn".encode("utf-8")) 3 f.flush() 4 f.close()
5、追加(a, ab)
1 f = open("文件", mode="a", encoding="utf-8") 2 f.write("oeasys.cn") 3 f.flush() 4 f.close()
6、r+读写
1 f = open("文件", mode="r+", encoding="utf-8") 2 content = f.read() 3 f.write("oeasys.cn") 4 print(content) 5 f.flush() 6 f.close() 7 结果: 8 正常的读取之后, 写在结尾
7、w+写读
1 f = open("文件", mode="w+", encoding="utf-8") 2 f.write("oeasys.cn") 3 content = f.read() 4 print(content) 5 f.flush() 6 f.close()
8、a+写读(追加写读)
1 f = open("文件", mode="a+", encoding="utf-8") 2 f.write("oeasys.cn") 3 content = f.read() 4 print(content) 5 f.flush() 6 f.close()
9、读取⽂件的⽅法:
1 f = open("文件路径", mode="r", encoding="utf-8") 2 content = f.read() 3 print(content)
1 f = open("文件路径", mode="r", encoding="utf-8") 2 content = f.readline() 3 content2 = f.readline() 4 content3 = f.readline() 5 content4 = f.readline() 6 content5 = f.readline()
1 f = open("文件", mode="r", encoding="utf-8") 2 for line in f: 3 print(line.strip())
注意: 读取完的⽂件句柄⼀定要关闭 f.close()
10、其他操作⽅法
1. seek(n) 光标移动到n位置, 注意, 移动的单位是byte. 所以如果是UTF-8的中⽂部分要 是3的倍数.
通常我们使⽤seek都是移动到开头或者结尾.
seek(偏移量,位置)
移动到开头: seek(0)
移动到结尾: seek(0,2)
seek的第⼆个参数表⽰的是从哪个位置进⾏偏移, 默认是0, 表 ⽰开头, 1表⽰当前位置, 2表⽰结尾
2. tell()获取到当前光标位置
print(f.tell())
3. truncate() 截断⽂件
从开头截断到光标位置,删掉光标后⾯的所有内容
如果给参数,从开头截断到参数位置
在r+模式下. 如果读取了内容. 不论读取内容多少. 光标显⽰的是多少. 再写入 或者操作⽂件的时候都是在结尾进⾏的操作.
所以如果想做截断操作. 记住了. 要先挪动光标. 挪动到你想要截断的位置. 然后再进⾏截断

 浙公网安备 33010602011771号
浙公网安备 33010602011771号