


ELK系列一 ElasticSearch Kibana 低代码编程01
ElasticSearch 安装
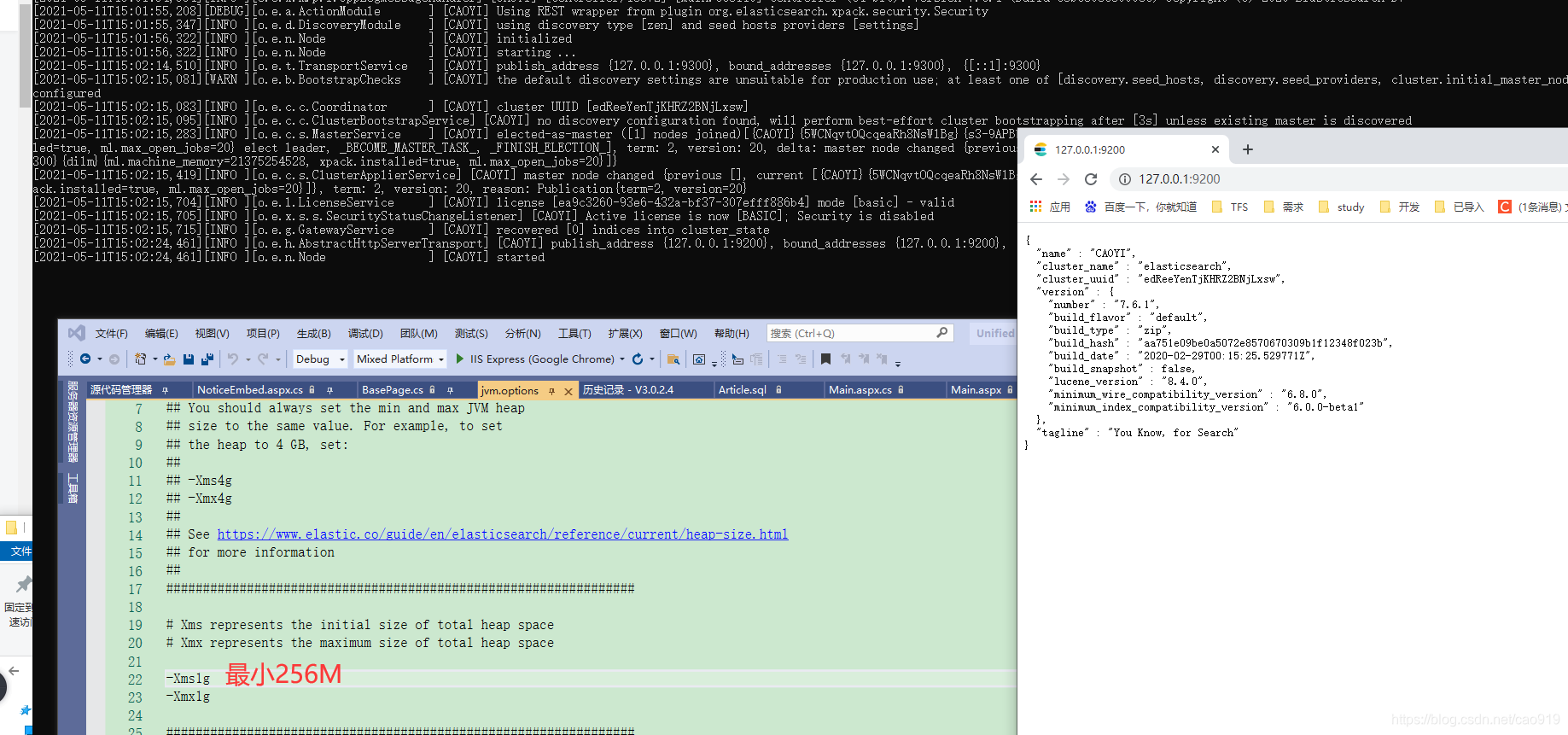
注意
es插件
npm install
npm run start
都可以
http://127.0.0.1:9200/
http://localhost:9200/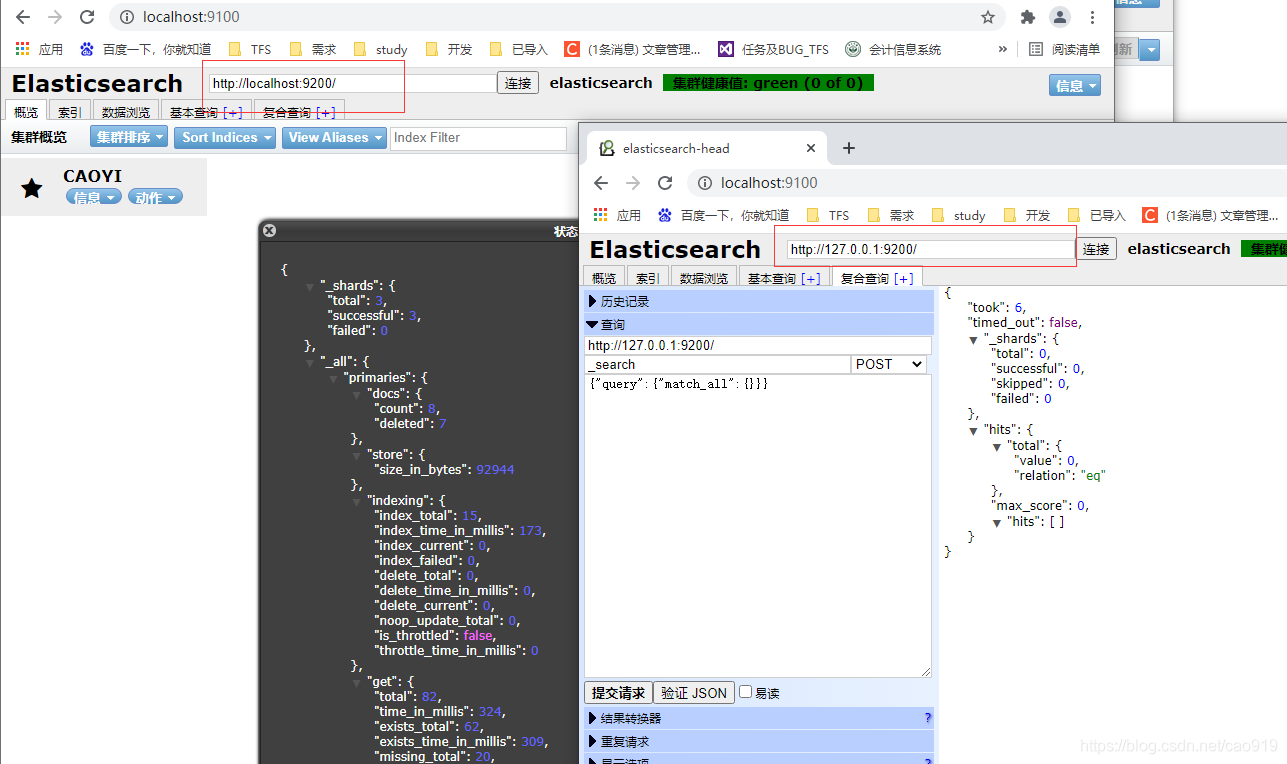
装上Kibana后
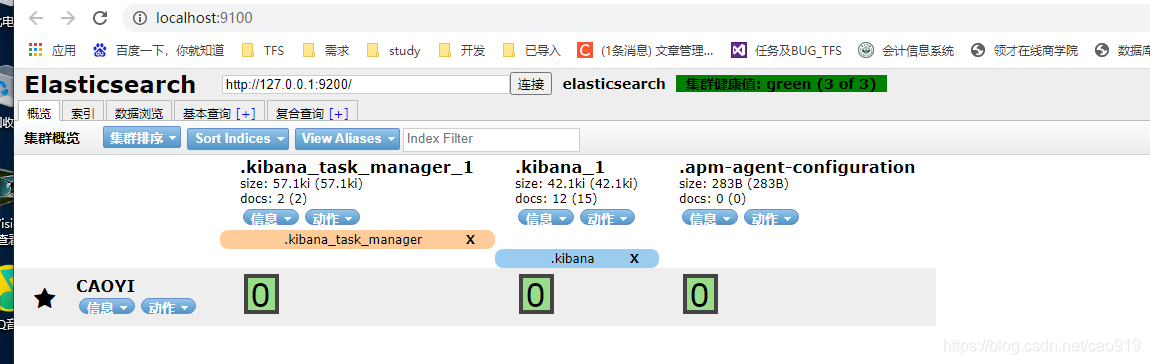
kibana 链接数据库
其他配置
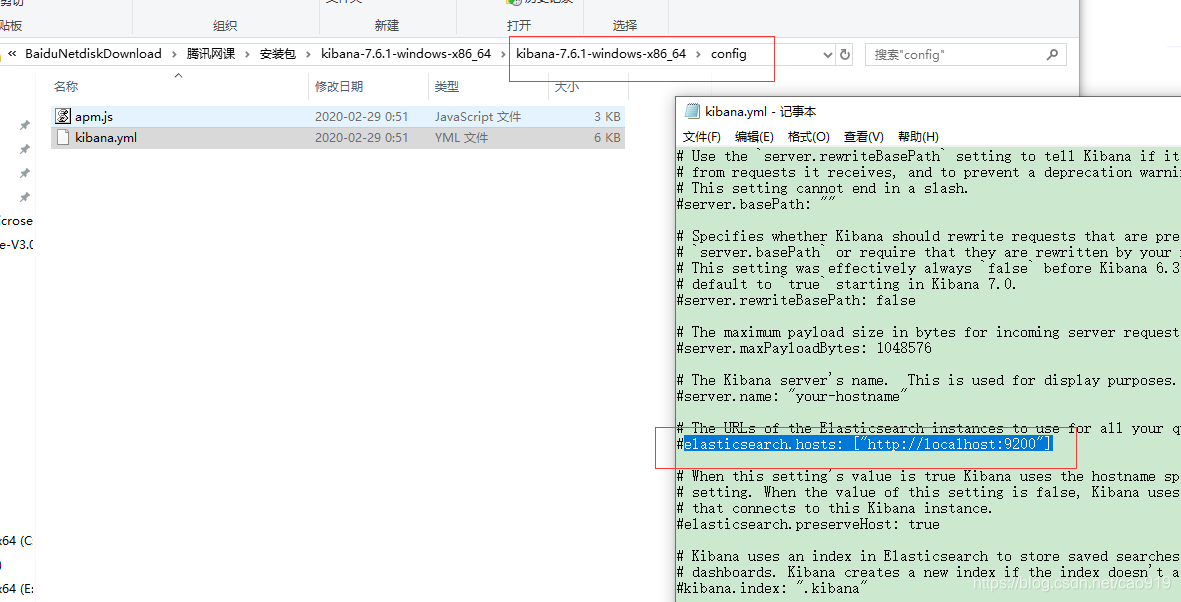
改为中文 i18n.locale: “zh”
安装 体会更多成长之 运气
体会更多成长之 运气
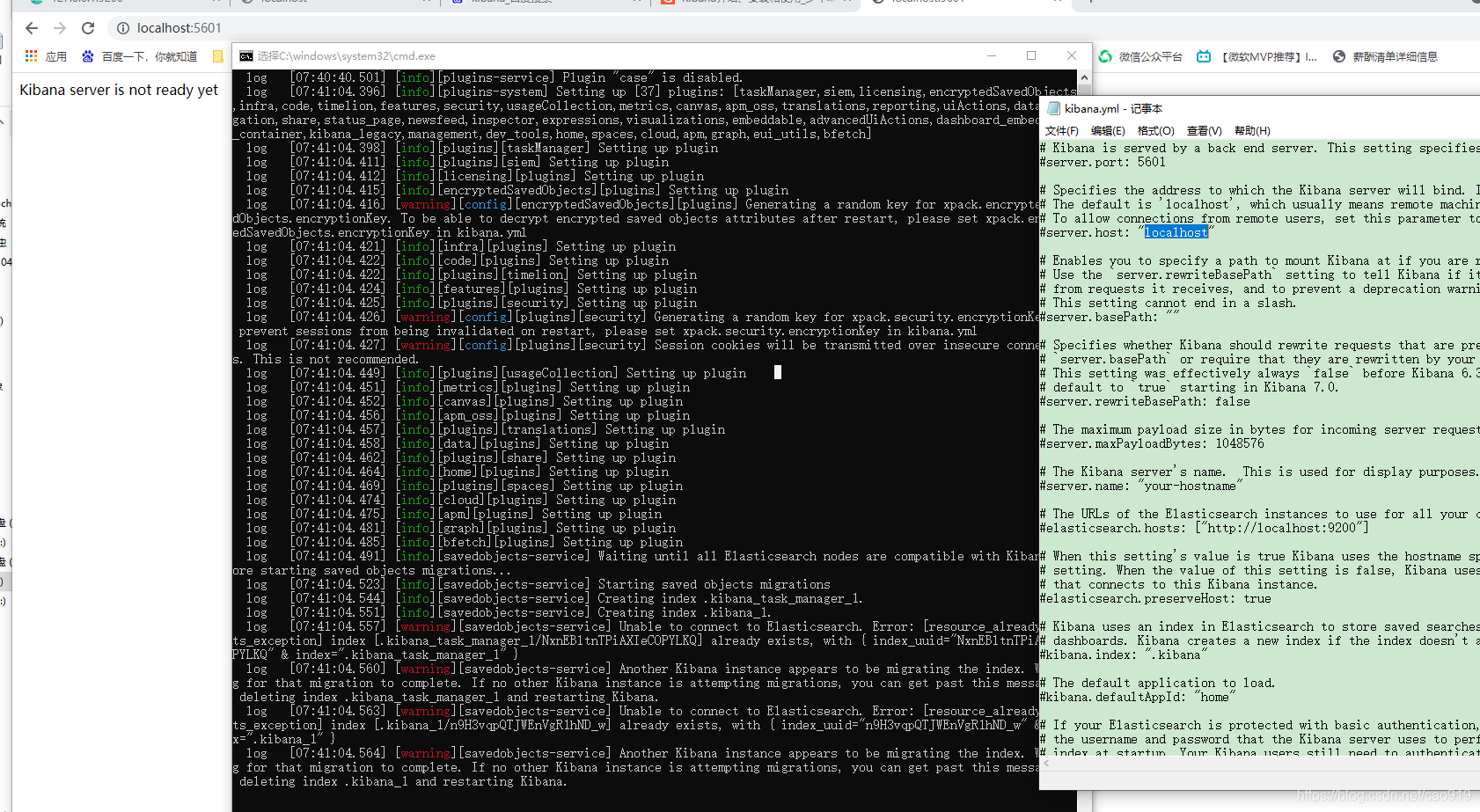
人品好才能进入这里 不好就各种从头再来吧QAQ
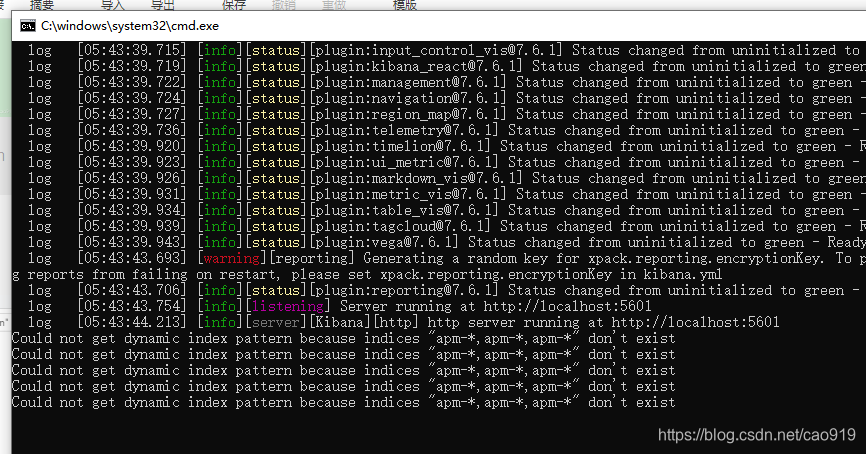
http://localhost:5601/
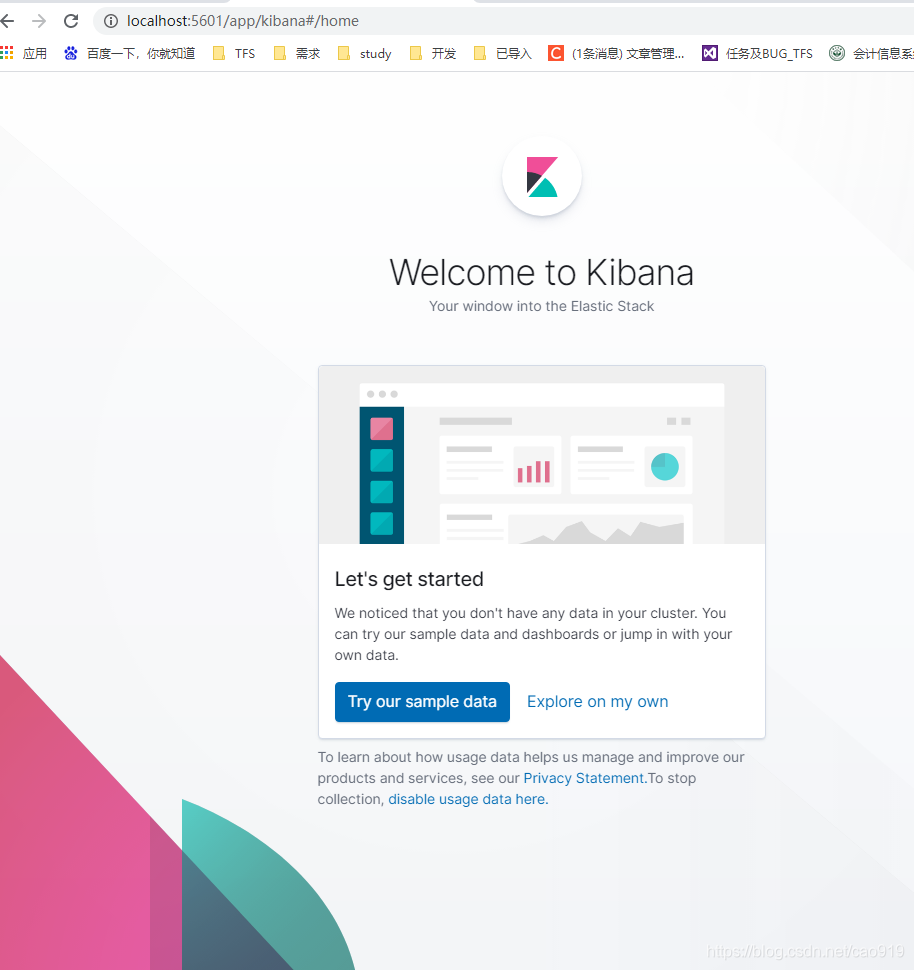
花里胡哨的登入页面 try 什么的
趴趴趴的功能
玩一下
插入数据
DELETE /clayindex
插入索引clayindex 和数据
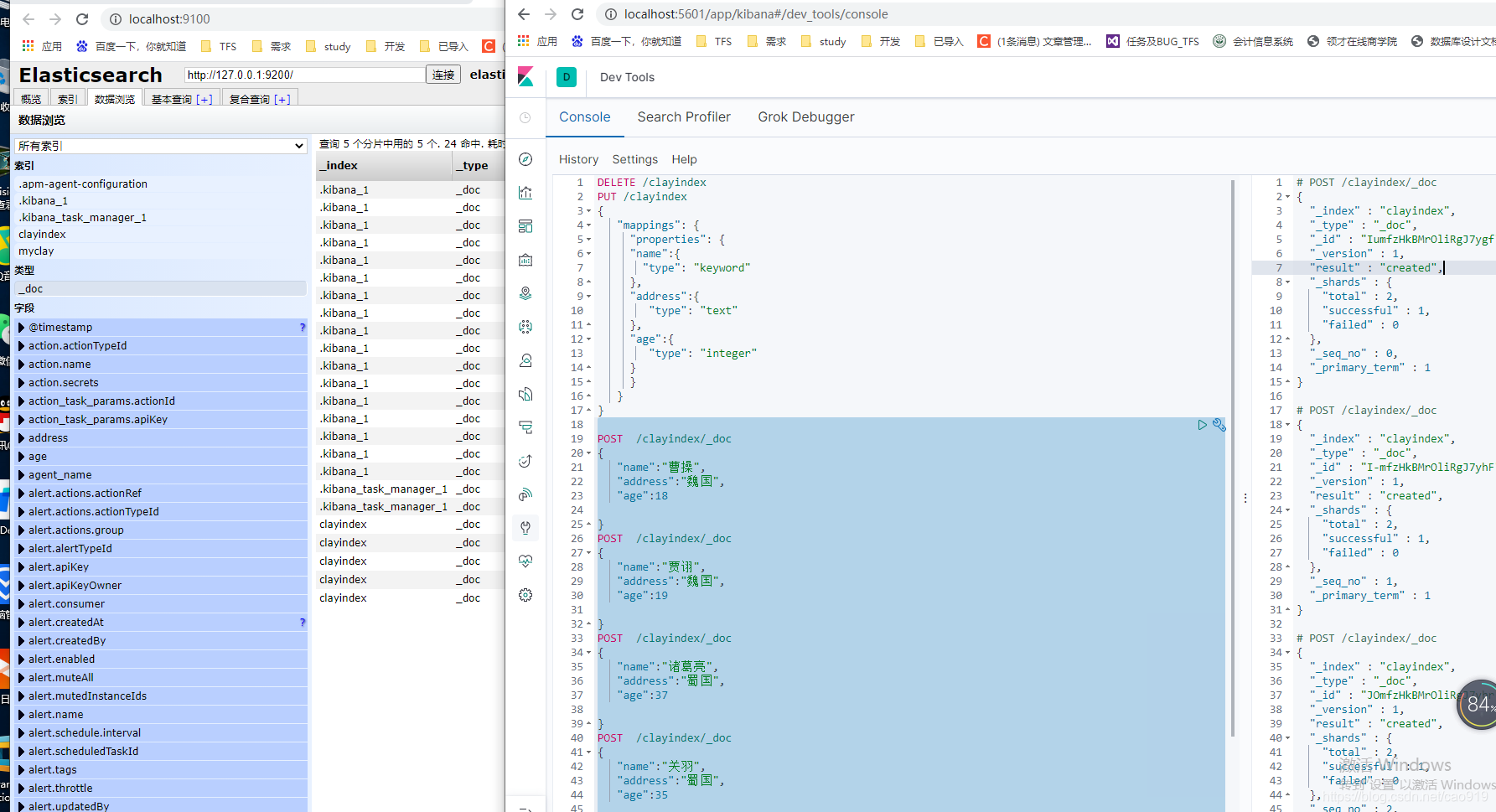
PUT /clayindex
{
“mappings”: {
“properties”: {
“name”:{
“type”: “keyword”
},
“address”:{
“type”: “text”
},
“age”:{
“type”: “integer”
}
}
}
}
-------------------插入数据
#插入数据 可以自己生成id //
POST /clayindex/_doc
{
“name”:“曹操”,
“address”:“魏国”,
“age”:18
}
POST /clayindex/_doc
{
“name”:“贾诩”,
“address”:“魏国”,
“age”:19
}
POST /clayindex/_doc
{
“name”:“诸葛亮”,
“address”:“蜀国”,
“age”:37
}
POST /clayindex/_doc
{
“name”:“关羽”,
“address”:“蜀国”,
“age”:35
}
POST /clayindex/_doc
{
“name”:“周瑜”,
“address”:[“吴国”,“蜀国”],
“age”:25
}
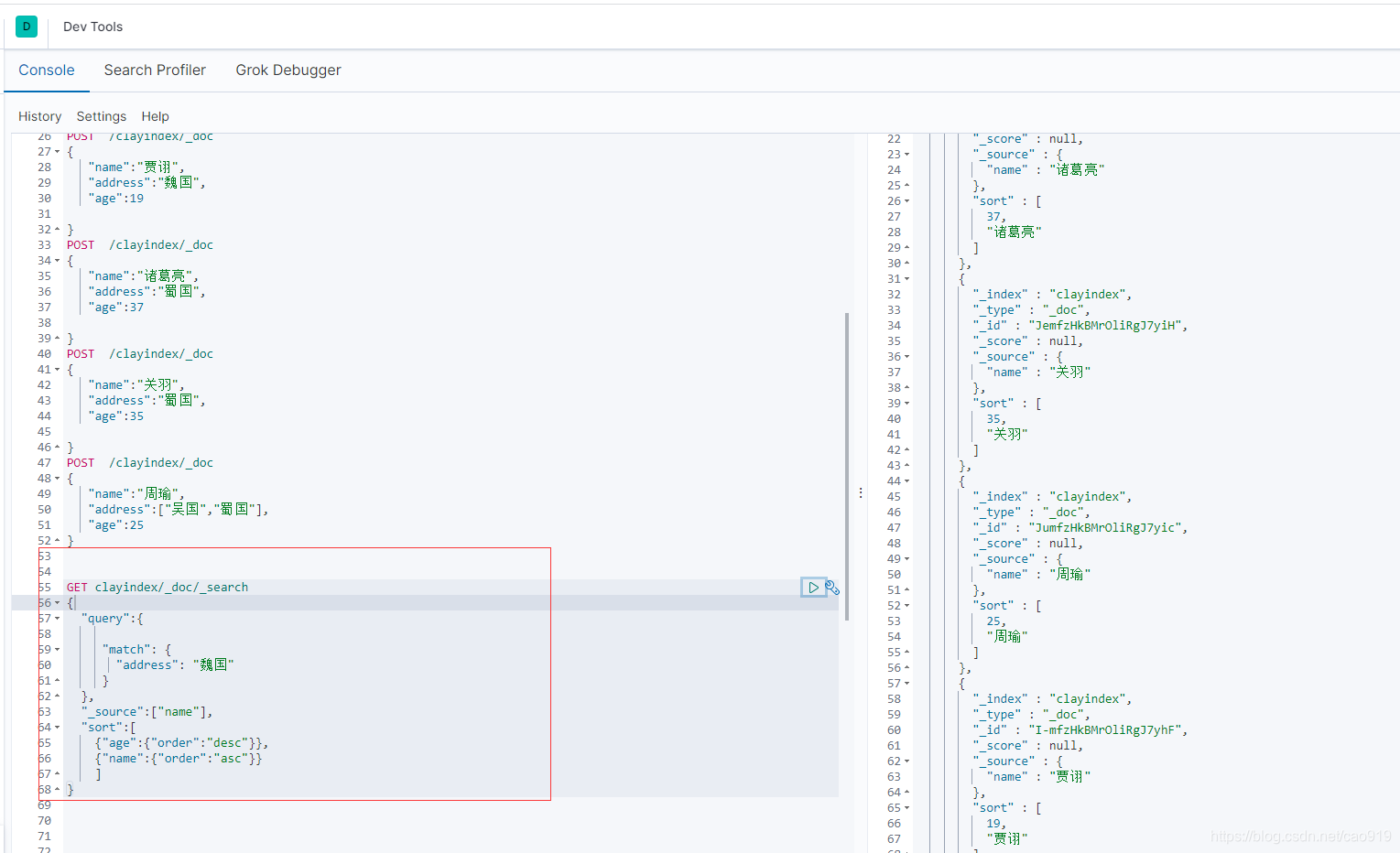
排序
GET clayindex/_doc/_search
{
“query”:{
“match”: {
“address”: “魏国”
}
},
“_source”:[“name”],
“sort”:[
{“age”:{“order”:“desc”}},
{“name”:{“order”:“asc”}}
]
}
#分页
GET clayindex/_doc/_search
{
“query”:{
“match”: {
“address”: “魏国”
}
},
“_source”:[“name”],
“sort”:[
{“age”:{“order”:“desc”}},
{“name”:{“order”:“asc”}}
],
“from”:0,
“size”:10
}
#条件1 or 条件2
GET clayindex/_doc/_search
{
“query”:{
“bool”: {
“should”: [
{
“match”: {
“address”: “魏国”
}
},{
"match": {
"name": "曹操"
}
}
]
}
},
“_source”:[“name”],
“sort”:[
{“age”:{“order”:“desc”}},
{“name”:{“order”:“asc”}}
],
“from”:0,
“size”:10
}
#排除 MUST_NOT
#查询名字不是曹操的信息
GET clayindex/_doc/_search
{
“query”:{
"bool": {
"must_not": [
{
"match": {
"name": "曹操"
}
}
]
}
}
}
#数据过滤FILTER
#gt 大于
#gte 大于等于
#lt 小于
#lte 小于等于!
查询名字是曹操,然后年龄大于等于10 小于等于30
GET clayindex/_doc/_search
{
“query”:{
"bool": {
"must": [
{
"match": {
"name": "曹操"
}
}
],
"filter": {
"range": {
"age": {
"gte": 10,
"lte": 20
}
}
}
}
}
}
高亮查询
#高亮查询
GET clayindex/_doc/_search
{
“query”:{
“match”: {
“name”: “曹操”
}
},
“highlight”:{
"fields": {
"name": {}
}
}
}
GET clayindex/_doc/_search
{
“query”:{
“match”: {
“address”: “魏国”
}
},
“highlight”:{
“fields”: {
“address”: {}
}
}
}
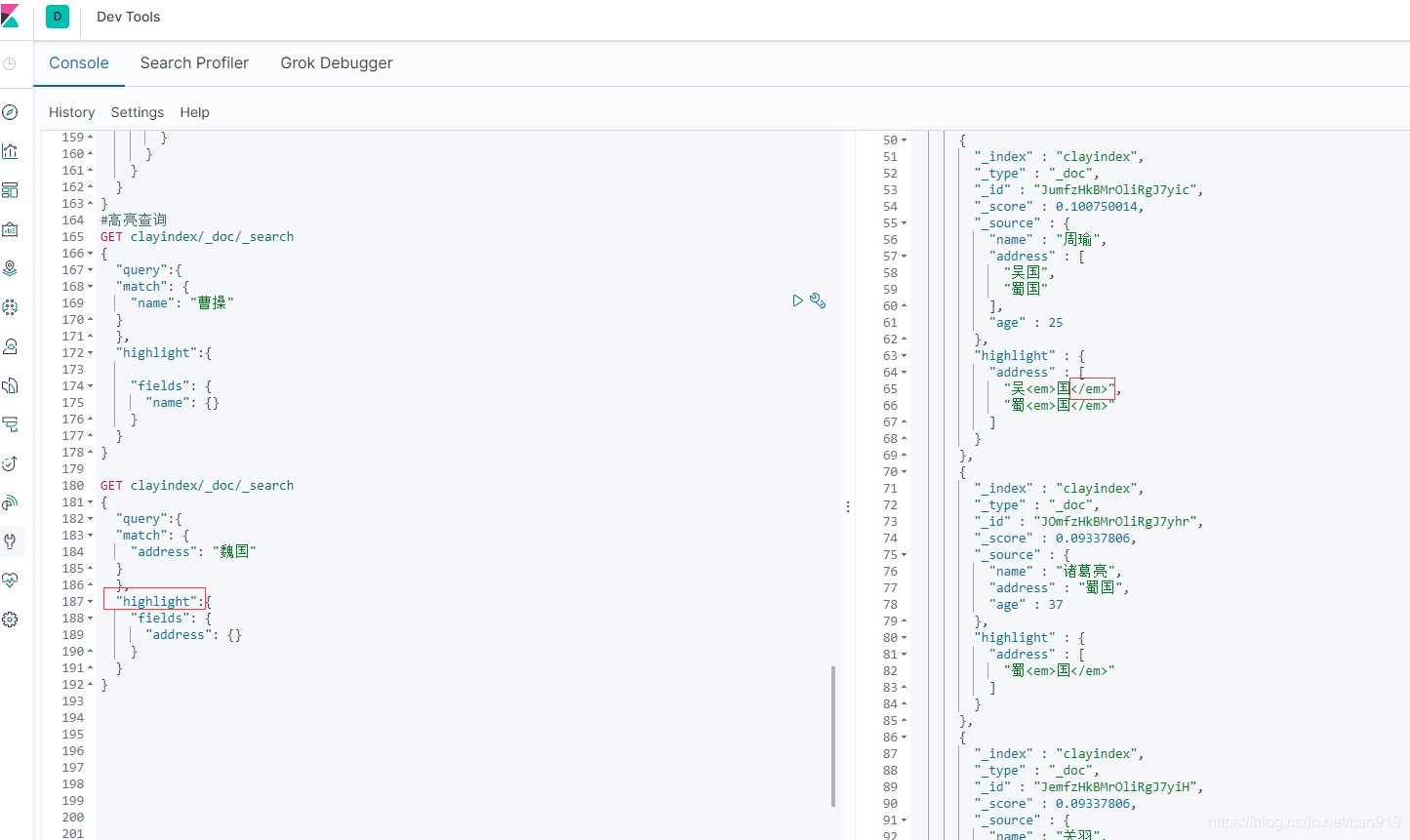
自定义高亮的风格
GET clayindex/_doc/_search
{
“query”:{
“match”: {
“name”: “曹操”
}
},
“highlight”:{
"pre_tags": "<p class='gaoliang'>",
"post_tags": "</p>",
"fields": {
"name": {}
}
}
}
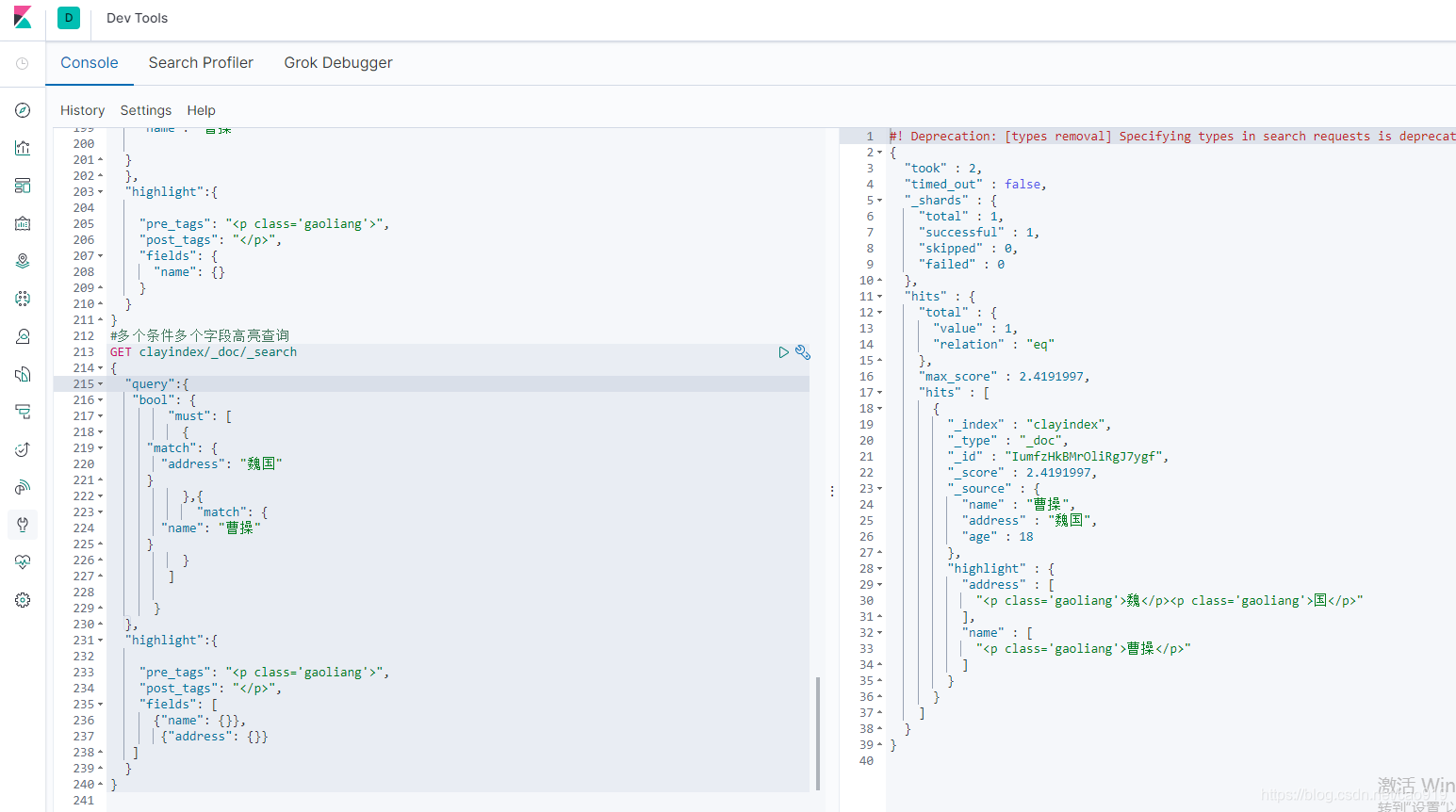
多个条件多个字段高亮查询
GET clayindex/_doc/_search
{
“query”:{
“bool”: {
“must”: [
{
“match”: {
“address”: “魏国”
}
},{
“match”: {
“name”: “曹操”
}
}
]
}
},
“highlight”:{
"pre_tags": "<p class='gaoliang'>",
"post_tags": "</p>",
"fields": [
{"name": {}},
{"address": {}}
]
}
}
聚合查询
bucket:
数据分组,一些数据按照某个字段进行bucket划分,这个字段值相同的数据放到一个bucket中。类似于Mysql中的group by后的查询结果。
metric:
对一个数据分组执行的统计,比如计算最大值,最小值,平均值等
类似于Mysql中的max(),min(),avg()函数的值,都是在group by后使用的。

