
为了实现主从切换,我们引入了哨兵;为了避免单个哨兵故障后无法进行主从切换,以及为了减少误判率,又引入了哨兵集群;哨兵集群又需要有一些机制来支撑它的正常运行。
基于 pub/sub 机制的哨兵集群组成
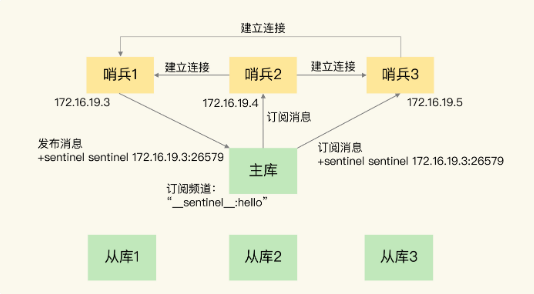
哨兵实例之间可以相互发现,要归功于 Redis 提供的 pub/sub 机制,也就是发布 / 订阅机制。
只有订阅了同一个频道的应用,才能通过发布的消息进行信息交换。
在主从集群中,主库上有一个名为“__sentinel__:hello”的频道,不同哨兵就是通过它来相互发现,实现互相通信的。
哨兵是如何知道从库的 IP 地址和端口的呢?
这是由哨兵向主库发送 INFO 命令来完成的。就像下图所示,哨兵 2 给主库发送 INFO 命令,主库接受到这个命令后,就会把从库列表返回给哨兵。接着,哨兵就可以根据从库列表中的连接信息,和每个从库建立连接,并在这个连接上持续地对从库进行监控。哨兵 1 和 3 可以通过相同的方法和从库建立连接。

基于 pub/sub 机制的客户端事件通知
从本质上说,哨兵就是一个运行在特定模式下的 Redis 实例,只不过它并不服务请求操作,只是完成监控、选主和通知的任务。所以,每个哨兵实例也提供 pub/sub 机制,客户端可以从哨兵订阅消息。哨兵提供的消息订阅频道有很多,不同频道包含了主从库切换过程中的不同关键事件。
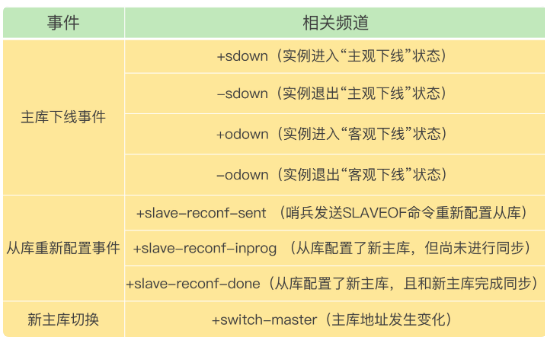
客户端读取哨兵的配置文件后,可以获得哨兵的地址和端口,和哨兵建立网络连接。然后,我们可以在客户端执行订阅命令,来获取不同的事件消息。
由哪个哨兵执行主从切换?
Leader 选举
任何一个实例只要自身判断主库“主观下线”后,就会给其他实例发送 is-master-down-by-addr 命令。接着,其他实例会根据自己和主库的连接情况,做出 Y 或 N 的响应,Y 相当于赞成票,N 相当于反对票。
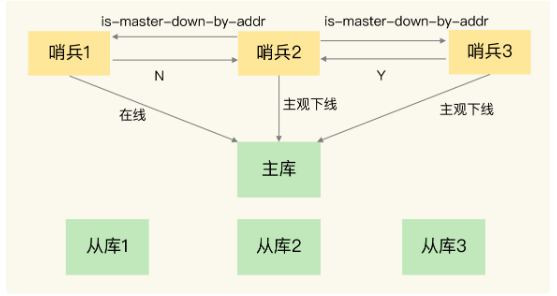
一个哨兵获得了仲裁所需的赞成票数后,就可以标记主库为“客观下线”。这个所需的赞成票数是通过哨兵配置文件中的 quorum 配置项设定的。
在一个哨兵判定出主库“客观下线”后,会立即发命令给其他哨兵,表明希望由自己来执行主从切换,并让所有其他哨兵进行投票。这个投票过程称为“Leader 选举”。因为最终执行主从切换的哨兵称为 Leader,投票过程就是确定 Leader。
在投票过程中,任何一个想成为 Leader 的哨兵,要满足两个条件:
第一,拿到半数以上的赞成票;
第二,拿到的票数同时还需要大于等于哨兵配置文件中的 quorum 值。
注意:每个哨兵只有一张赞成票。
经验分享:
要保证所有哨兵实例的配置是一致的,尤其是主观下线的判断值 down-after-milliseconds。
评论精选
Redis 1主4从,5个哨兵,哨兵配置quorum为2,如果3个哨兵故障,当主库宕机时,哨兵能否判断主库“客观下线”?能否自动切换?
经过实际测试,我的结论如下:
1、哨兵集群可以判定主库“主观下线”。由于quorum=2,所以当一个哨兵判断主库“主观下线”后,询问另外一个哨兵后也会得到同样的结果,2个哨兵都判定“主观下线”,达到了quorum的值,因此,哨兵集群可以判定主库为“客观下线”。
2、但哨兵不能完成主从切换。哨兵标记主库“客观下线后”,在选举“哨兵领导者”时,一个哨兵必须拿到超过多数的选票(5/2+1=3票)。但目前只有2个哨兵活着,无论怎么投票,一个哨兵最多只能拿到2票,永远无法达到多数选票的结果。
但是投票选举过程的细节并不是大家认为的:每个哨兵各自1票,这个情况是不一定的。下面具体说一下:
场景a:哨兵A先判定主库“主观下线”,然后马上询问哨兵B(注意,此时哨兵B只是被动接受询问,并没有去询问哨兵A,也就是它还没有进入判定“客观下线”的流程),哨兵B回复主库已“主观下线”,达到quorum=2后哨兵A此时可以判定主库“客观下线”。此时,哨兵A马上可以向其他哨兵发起成为“哨兵领导者”的投票,哨兵B收到投票请求后,由于自己还没有询问哨兵A进入判定“客观下线”的流程,所以哨兵B是可以给哨兵A投票确认的,这样哨兵A就已经拿到2票了。等稍后哨兵B也判定“主观下线”后想成为领导者时,因为它已经给别人投过票了,所以这一轮自己就不能再成为领导者了。
场景b:哨兵A和哨兵B同时判定主库“主观下线”,然后同时询问对方后都得到可以“客观下线”的结论,此时它们各自给自己投上1票后,然后向其他哨兵发起投票请求,但是因为各自都给自己投过票了,因此各自都拒绝了对方的投票请求,这样2个哨兵各自持有1票。
场景a是1个哨兵拿到2票,场景b是2个哨兵各自有1票,这2种情况都不满足大多数选票(3票)的结果,因此无法完成主从切换。
经过测试发现,场景b发生的概率非常小,只有2个哨兵同时进入判定“主观下线”的流程时才可以发生。我测试几次后发现,都是复现的场景a。
哨兵实例是不是越多越好?
并不是,我们也看到了,哨兵在判定“主观下线”和选举“哨兵领导者”时,都需要和其他节点进行通信,交换信息,哨兵实例越多,通信的次数也就越多,而且部署多个哨兵时,会分布在不同机器上,节点越多带来的机器故障风险也会越大,这些问题都会影响到哨兵的通信和选举,出问题时也就意味着选举时间会变长,切换主从的时间变久。
调大down-after-milliseconds值,对减少误判是不是有好处?
是有好处的,适当调大down-after-milliseconds值,当哨兵与主库之间网络存在短时波动时,可以降低误判的概率。但是调大down-after-milliseconds值也意味着主从切换的时间会变长,对业务的影响时间越久,我们需要根据实际场景进行权衡,设置合理的阈值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号