Hadoop伪分布式搭建
作者:gqk:
单机环境:可以直接执行mareduce-examples.jar案例
伪分布式:一个服务器上运行多个进程
HDFS:伪分布式配置
Hadoop配置文件的配置:
a,配置核心文件(路径/opt/module/hadoop-2.7.5/etc/hadoop)
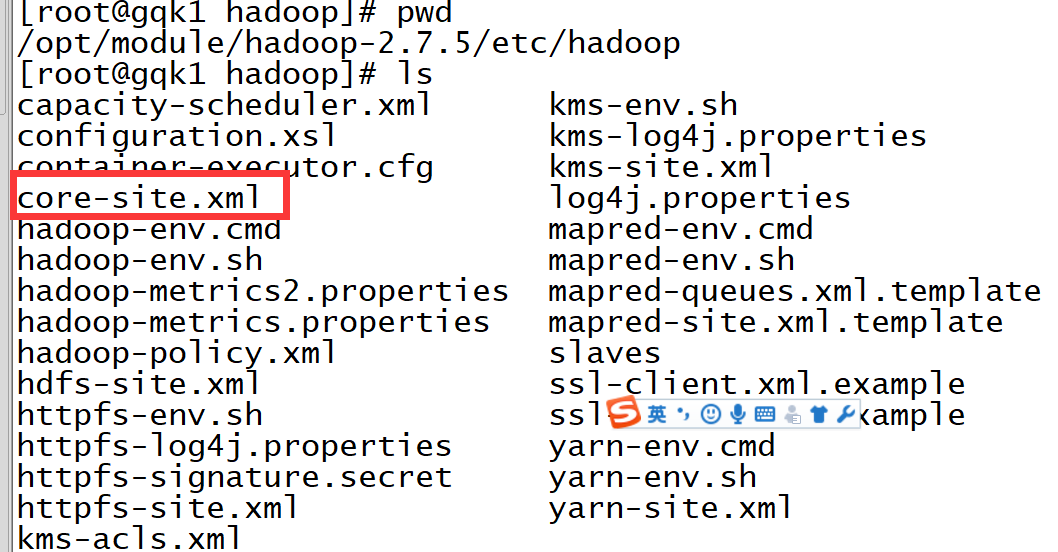
配置:vim core-site.xml
<configuration>
<!--指定namenode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://gqk1:8020</value>
</property>
</configuration>
配置:hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
格式化NameNode--------清空主节点NameNode目录下的所有数据生成目录结构初始化一些数据到文件中
进入:/opt/module/hadoop-2.7.5/bin 有个hdfs的文件

执行./hdfs
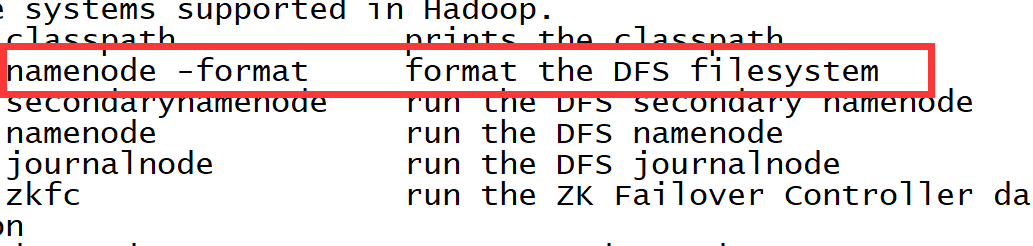
执行: ./hdfs namenode -format 格式化(查看官网 查找生成文件的目录)
在hdfs-site.xml 查找

在core-site.xml 查找

启动HDFS各个进程
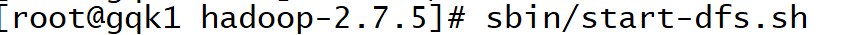
启动后必须输入密码(没有配置ssh免秘钥链接)
启动完成查看进程 jps
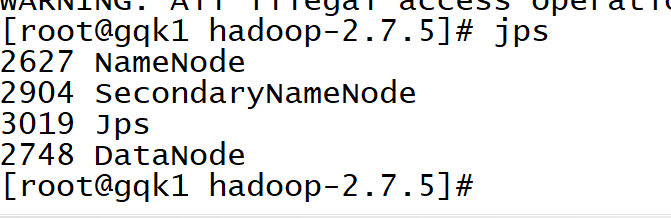
如果用主机名称访问需要映射:

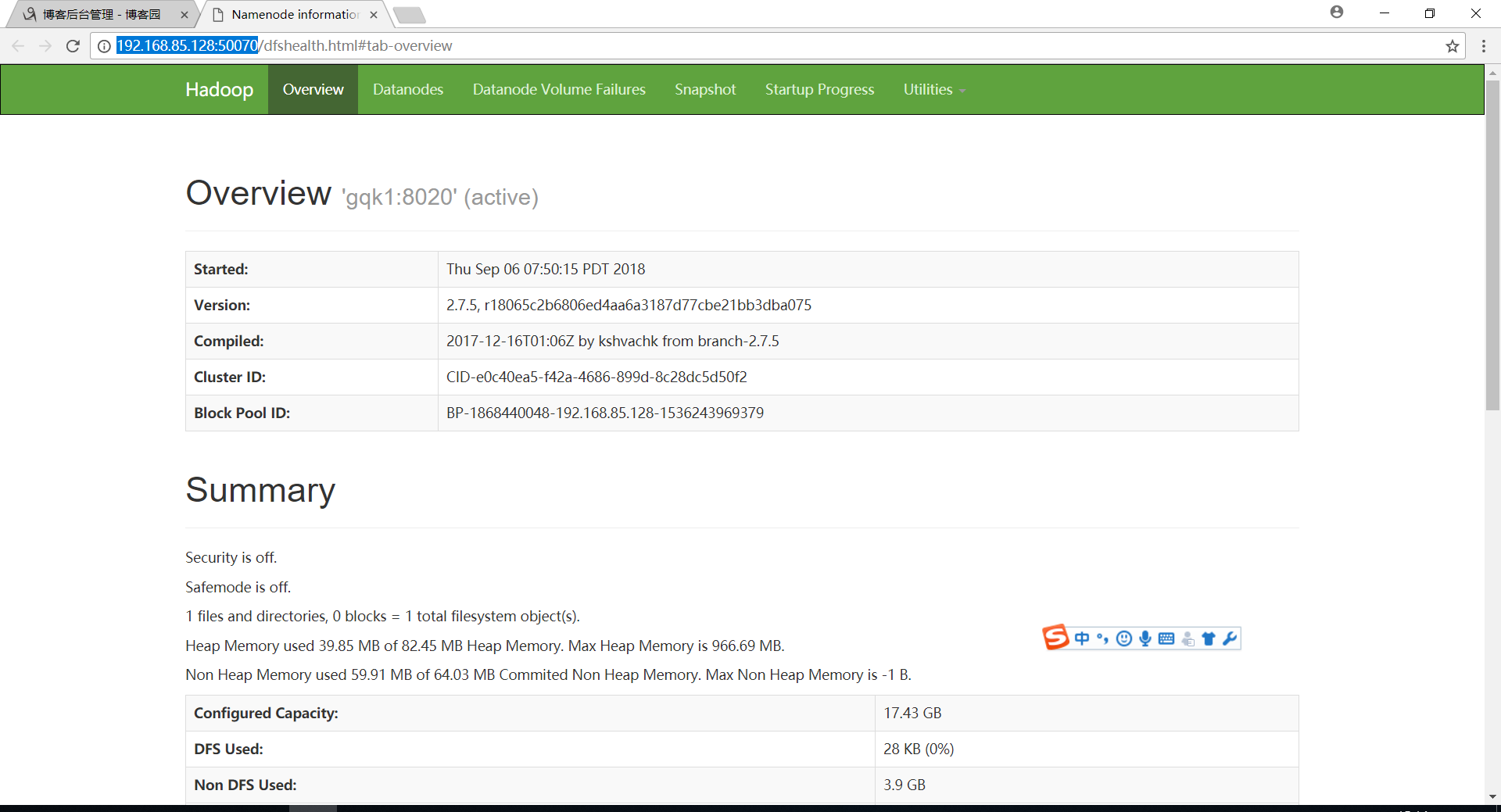
通过主机名称或者ip地址访问50070端口
http://192.168.85.128:50070
![]()
如果出现window系统不能访问虚拟机上可以执行:
关闭命令: service iptables stop
永久关闭防火墙:chkconfig iptables off
./stop-dfs.sh 停止进程;
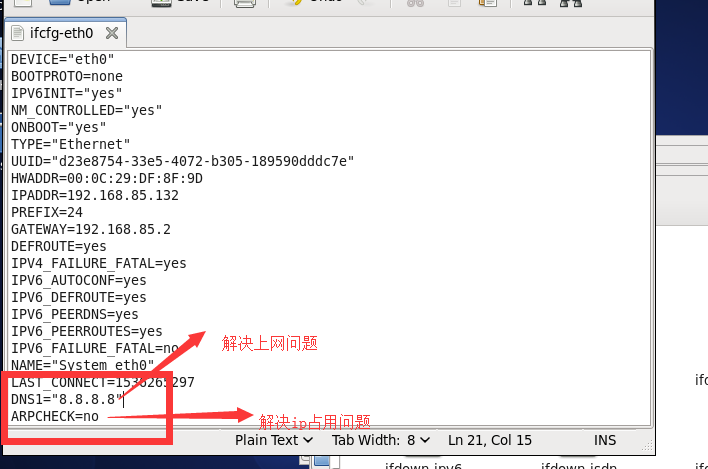
如果虚拟机不能上网的话:
yarn的伪分布式配置:
mapred-site.xml配置(/opt/module/hadoop-2.7.5/etc/hadoop)
需要对文件进行改名:mv mapred-site.xml.template mapred-site.xml
编辑:
mapreduce运行在yarn之上,默认伪local
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml配置
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
配置完成后;启动yarn的服务:
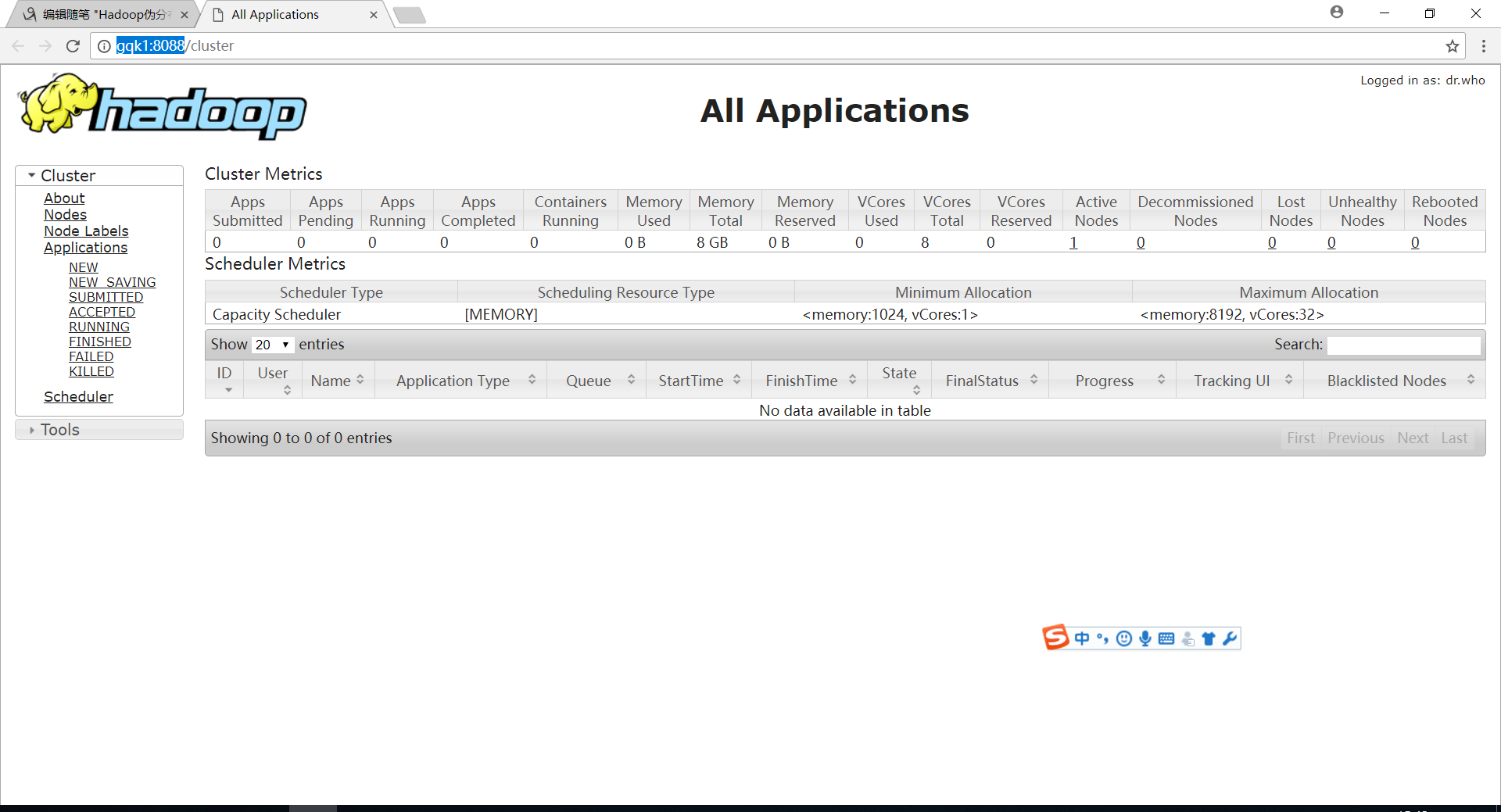
[root@gqk1 sbin]# ./start-yarn.sh 出现一下节点:
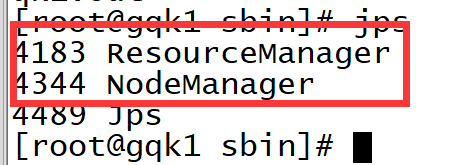
访问yarn HTTP端口8088:http://gqk1:8088