linux xshell jdk hadoop(环境搭建) 虚拟机 安装(大数据搭建环境)
【hadoop是2.6.5版本 xshell是6版本 jdk是1.8.0.131 虚拟机是CentOS-6.9-x86_64-bin-DVD1.iso vmware10】
1.创建虚拟机
第一步:在VMware中创建一台新的虚拟机。如图2.2所示。
 图2.2
图2.2
第二步:选择“自定义安装”,然后单击“下一步”按钮,如图2.3所示。
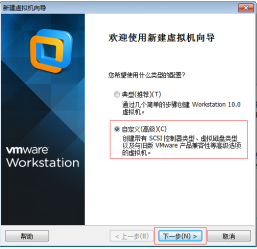 图2.3
图2.3
第三步:单击“下一步” 按钮,如图2.4所示。
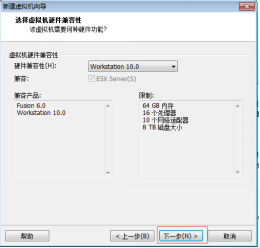 图2.4
图2.4
第四步:选择“稍后安装操作系统”,然后单击“下一步” 按钮,如图2.5所示。
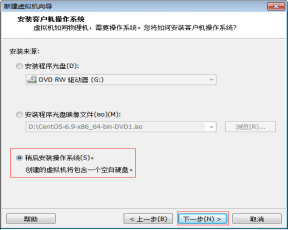 图2.5
图2.5
第五步:客户机操作系统选择Linux,版本选择“CentOS 64位”,然后单击“下一步” 按钮,如图2.6所示。
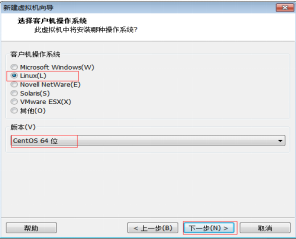 图2.6
图2.6
第六步:在这里可以选择“修改虚拟机名称”和“虚拟机存储的物理地址”,如图2.7所示。
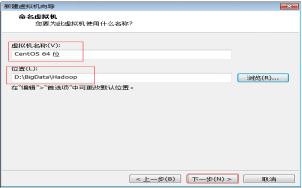 图2.7
图2.7
第七步:根据本机电脑情况给Linux虚拟机分配“处理器个数”和每个处理器的“核心数量”。注意不能超过自己电脑的核数,推荐处理数量为1,每个处理器的核心数量为1,如图2.8所示。
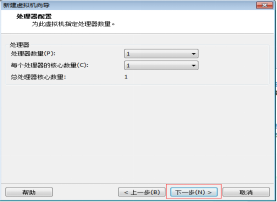 图2.8
图2.8
第八步:给Linux虚拟机分配内存。分配的内存大小不能超过自己本机的内存大小,多台运行的虚拟机的内存总合不能超过自己本机的内存大小,如图2.9所示。
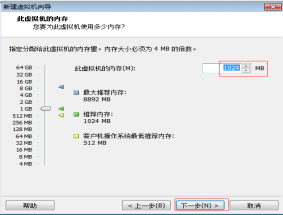 图2.9
图2.9
第九步:使用NAT方式为客户机操作系统提供主机IP地址访问主机拨号或外部以太网网络连接,如图2.10所示。
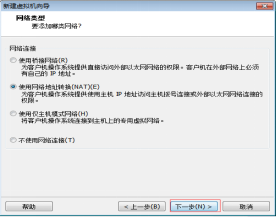 图2.10
图2.10
第十步:选择“SCSI控制器为LSI Logic(L)”,然后单击“下一步” 按钮,如图2.11所示。
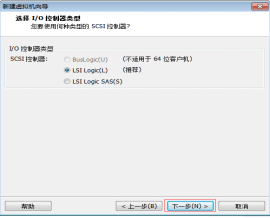 图2.11
图2.11
第十一步:选择“虚拟磁盘类型为SCSI(S)”,然后单击“下一步” 按钮,如图2.12所示。
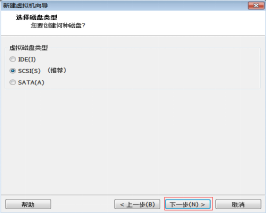 图2.12
图2.12
第十二步:选择“创建新虚拟磁盘”,然后单击“下一步” 按钮,如图2.13所示。
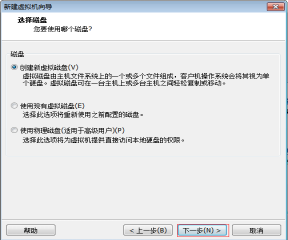 图2.13
图2.13
第十三步:根据本机的磁盘大小给Linux虚拟机分配磁盘,并选择“将虚拟机磁盘拆分为多个文件”,然后单击“下一步”按钮,如图2.14所示。
 图2.14
图2.14
第十四步:根据需要修改存储磁盘文件的位置。如果不更改,默认存储在Linux虚拟机安装文件目录,如图2.15所示。
 图2.15
图2.15
第十五步:单击“完成”按钮,完成新虚拟机向导,如图2.16所示。
 图2.16
图2.16
第十六步:在虚拟机名字上单击鼠标右键,选择“设置”来设置安装的ISO文件。选择“CD/DVD à 使用ISO镜像文件”,选择自己的镜像文件,然后单击“确定”按钮,如图2.17所示。
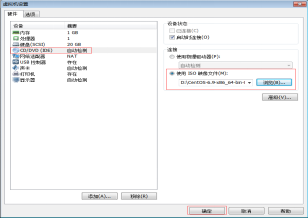 图2.17
图2.17
第十七步:开启设置好的虚拟机,进行Linux虚拟机安装,如图2.18所示。
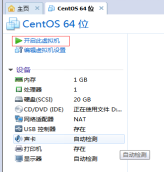 图2.18
图2.18
第十八步:选择“不再显示此消息”,然后单击“取消” 按钮。
第十九步:进入到VMware虚拟机选择“Instell or upgrade an existing system”单击“回车” 键进行安装。或者不作任何操作,它将倒计时90秒后自动安装。进入到VMware后可以用“Ctrl+Alt”组合键退出VMware,如图2.19所示。
 图2.19
图2.19
第二十步:进入到安装前测试页面,通过方向键选择“Skip”按钮跳过测试,如图2.20所示。
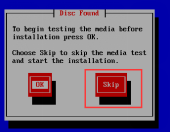 图2.20
图2.20
第二十一步:用鼠标单击“Next” 按钮进行下一步操作,如图2.21所示。
 图2.21
图2.21
第二十二步:用鼠标选择“中文简体”,然后单击“下一步”按钮,如图2.22所示。
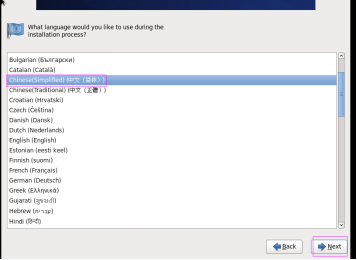
图2.22
第二十三步:键盘选择“美国英语式”,然后单击“下一步” 按钮,如图2.23所示。
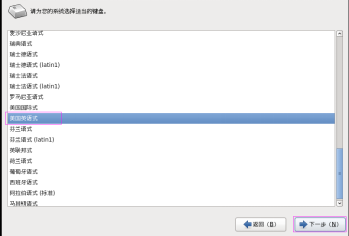
图2.23
第二十四步:选择“基本存储设备”,然后单击“下一步” 按钮,如图2.24所示。
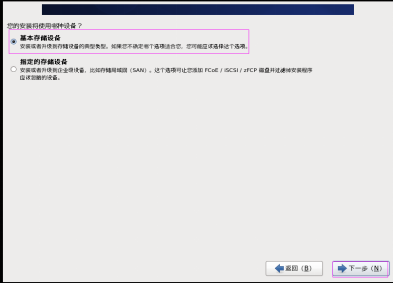
图2.24
第二十五步:单击“忽略所有数据” 按钮,如图2.25所示。
 图2.25
图2.25
第二十六步:设置Linux虚拟机的“主本名”,然后单击“下一步” 按钮,如图2.26所示。
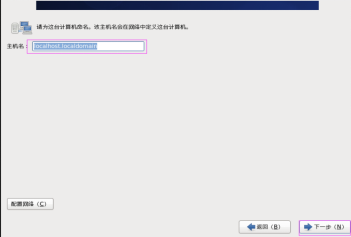 图2.26
图2.26
第二十七步:设置时间区域,勾选系统使用UTC时间,然后单击“下一步”按钮,如图2.27所示。
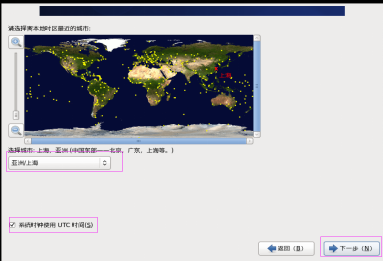 图2.27
图2.27
第二十八步:设置管理员用户root的密码,如图2.28所示。(统一使用123456)
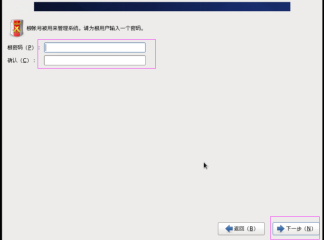 图2.28
图2.28
第二十九步:选择“使用所有空间”,然后单击“下一步”按钮,如图2.29所示。
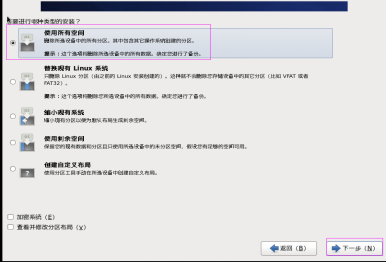 图2.29
图2.29
第三十步:单击“将修改写入磁盘”按钮,如图2.30所示。
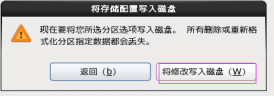 图2.30
图2.30
第三十一步:选择Minimal,然后单击“下一步” 按钮。这里安装的是纯命令行版,也可以安装桌面版,可以选择Desktop或者Minimal Desktop,如图2.31所示。
 图2.31
图2.31
第三十二步:进行安装界面,这里一共需要安装332个软件包,如图2.32所示。
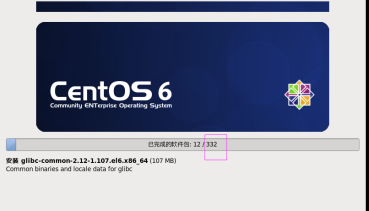 图2.32
图2.32
第三十三步:单击“重新引导” 按钮,完成安装,如图2.33所示。
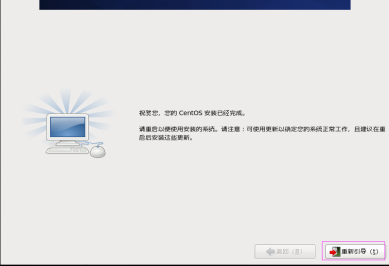
图2.33
第三十四步:测试安装是否成功。输入用户root和用户密码,如果能进入到如下界面,说明安装成功,如图2.34所示。
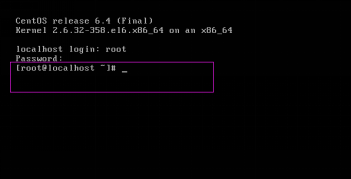 图2.34
图2.34
[root@localhost ~]#
root:是登录到Linux系统的用户名。
localhost:是Linux系统的主机名。
~:是root用户所在的位置。“~”是表示root的家目录,root家目录实际路径是/home/root。
2.linux虚拟机 安装JDK和Hadoop
为在生产环境中hadoop大数据集群是由多台服务器组成的集群,为了方便学习这里采用在VMware平台中搭建虚拟机的方式模拟hadoop大数据集群。若要想实现hadoop大数据集群环境,至少需要4台虚拟机,其中1台Master节点,3台Slave节点,每台节点配置环境。为了实现hadoop集群须有一台Master节点和多台Slave节点(其中IP地址第三段“153”需要跟自己的VMware工具平台网段一致,可以通过在VMware工作平台中单击“编辑-->虚拟网络编辑器-->VMware8-->子网”来查看)。

具体配置如表5.1所示。
表5.1 集群节点信息
|
主机名 |
IP地址 |
|
Master001 |
192.168.153.200 |
|
Slave001 |
192.168.153.201 |
|
Slave002 |
192.168.153.202 |
|
Slave003 |
192.168.153.203 |
1. 基础信息配置。
首先在一台虚拟机中设置基础信息,假设这台虚拟机为Master001。在基础信息中需要设置主机名、IP地址和名称解析等配置,这些配置文件只有root用户才有改写权限,所以需要使用root用户登录来编写这些配置文件。
1)修改主机名
通过编辑network文件,将HOSTNAME值修改为新的主机名,具体操作如下。
[root@localhost ~]# vi /etc/sysconfig/network
改写:
HOSTNAME=Master001
2)设置静态IP
通过编辑ifcfg-eth0文件来设置IP地址,具体操作如下。
[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-eth0
改写:
ONBOOT=yes
BOOTPROTO=static
插入:
IPADDR=192.168.153.200
NETMASK=255.255.255.0
GATEWAY=192.168.153.2
DNS1=192.168.153.2
3)设置hosts
hosts文件是Linux系统中负责IP地址与域名快速解析的文件,需要配置其它的几个节点的主机名和IP来快速访问集群中的其它节点。
具体操作如下:
[root@localhost ~]# vi /etc/hosts
插入:
192.168.153.200 Master001
192.168.153.201 Slave001
192.168.153.202 Slave002
192.168.153.203 Slave003
4)使设置生效
只是修改IP地址可以重启网络服务即可以生效,操作如下:
[root@localhost ~]# service network restart
如果修改了主机名,必须重启虚拟机才能生效,操作如下:
[root@localhost ~]# reboot
5)验证设置是否成功
启动成功后信息栏从“[root@localhost ~]#”变成了“[root@Master001 ~]#”,这时主机名修改成功。
验证IP地址设置是否成功可以通过ifconfig命令查看IP地址,如果出现“eth0”网络名称和IP地址,说明静态IP设置成功,这时可以使用ping命令进一步验证是否能联通内网。,具体操作如下:
[root@Master001 ~]# ifconfig
eth0 Link encap:Ethernet HWaddr 00:0C:29:45:78:7B
inet addr:192.168.153.101 Bcast:192.168.153.255 Mask:255.255.255.0
......
RX bytes:8610 (8.4 KiB) TX bytes:9849 (9.6 KiB)
lo Link encap:Local Loopback
net addr:127.0.0.1 Mask:255.0.0.0
......
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
[root@Master001 ~]# ping 192.168.153.1 (此处的153 应改为你们 NAT 模式下子网的第三段)
PING 192.168.153.1 (192.168.153.1) 56(84) bytes of data.
64 bytes from 192.168.153.1: icmp_seq=1 ttl=128 time=0.450 ms
......
64 bytes from 192.168.153.1: icmp_seq=4 ttl=128 time=0.522 ms
^C
--- 192.168.153.1 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 4019ms
rtt min/avg/max/mdev = 0.450/0.501/0.572/0.055 ms
验证外网是否联通。VMware平台中的虚拟是通过与虚拟机共享主机的IP地址来访问外网,虚拟机要连接网络必须保证宿主机能够正常访问网络,虚拟机是否能访问外网可以通过“ping www.baidu.com”命令来验证,如果能ping通百度说明外网访问成功。
[root@Master001 ~]# ping www.baidu.com
PING www.baidu.com (180.97.33.107) 56(84) bytes of data.
64 bytes from 180.97.33.107: icmp_seq=1 ttl=128 time=36.2 ms
......
64 bytes from 180.97.33.107: icmp_seq=6 ttl=128 time=41.2 ms
^C
--- www.baidu.com ping statistics ---
6 packets transmitted, 6 received, 0% packet loss, time 5729ms
rtt min/avg/max/mdev = 36.278/38.147/41.229/1.858 ms
6)创建普通用户
计算机的操作难免会有失误,如果关于内核的操作不当,就会对系统造成重大破坏,如一些工具不能使用,系统无法启动等等。为了减少误操作对系统造成的伤害,出于安全性需要建立普通用户。
(1)创建用户名叫hadoop的用户。
[root@Master001 ~]# adduser hadoop
(2)给hadoop用户指定密码(密码:123456)。
[root@Master001 ~]# passwd hadoop
更改用户 hadoop 的密码。
新的 密码:
无效的密码: 过于简单化/系统化
无效的密码: 过于简单
重新输入新的 密码:
passwd: 所有的身份验证令牌已经成功更新。
(3)验证用户是否创建成功,如果能成功切换表示用户创建成功。
[root@Master001 ~]# su hadoop
[hadoop@Master001 ~]#
7)安装Xshell
XShell是系统的用户界面,提供了用户与内核进行交互操作的一种接口,它接收用户输入的命令并把它送入内核去执行。可以把XShell理解为一个客户端,可以通过这个客户端来远程操作Linux系统,就像用Navicat去连接MySQL服务器一样,可以远程操作MySQL数据库。
3. 安装XShell上传文件
1.安装
(1)在安装文件目录中找到Xme4.exe文件,并双击安装Xme4.exe。
(2)勾选同意,单击“下一步”按钮,如图2.35所示。
 图2.35
图2.35
(3)输入名字、公司和密钥,单击“下一步”按钮,如图2.36所示。
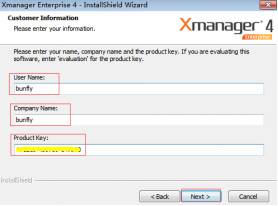
Product Key:101210-450789-147200
图2.36
(4)修改安装地址,单击“下一步”按钮,如图2.37所示。
 图2.37
图2.37
(5)选择经典安装模式,单击“下一步”按钮,如图2.38所示。
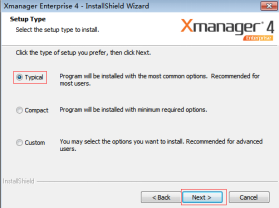 图2.38
图2.38
(6)以后操作均为默认选项,当出现“安装成功”后单击“完成”按钮即可。
3. 连接XSHell
(1)双击XShell图标,单击“新建连接”按钮,打开XShell终端,如图2.39所示。
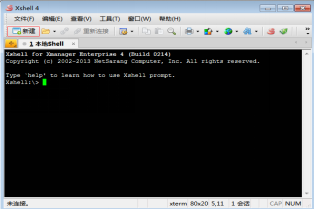 图2.39
图2.39
(2)配置需要连接的虚拟机IP地址、用户名和密码。
这里使用hadoop用户登录,连接成功后将进入到hadoop用户家目录,如果是root用户登录连接成功将进入root用户家目录,如图2.40、2.41所示。
(主机号应为你所配置的虚拟机IP(即IPADDR 后所写网段) 可在虚拟机中使用 ifconfig命令查看)

 图2.40
图2.40
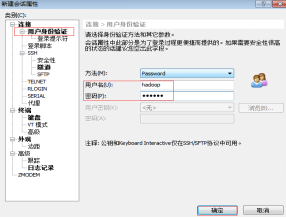 图2.41
图2.41
(3)选择连接XShell,如果信息栏出现“[hadoop@Master001 ~]$”表示连接成功。
(4)切换到家里目录,在家目录下创建一个名字叫software的文件夹,用于管理安装文件。
[hadoop@Master001 ~]$ cd ~
[hadoop@Master001 ~]$ mkdir software
(5)进入到softeware目录。
[hadoop@Master001 ~]$ cd software
[hadoop@Master001 software]$
4. 利用Xftp工具上传文件
1)XShell工具中自带Xftp工具快捷键,可以利用Xftp快捷键进入到Xftp工具中,Xftp工具可以从XShell工作界面,单击“Xftp快捷键”按钮登录,登录的用户与XShell登录的用户为同一用户。如图2.42所示。也可以单独通过双击Xftp工具输入IP地址、用户名和密码单独登录。
如果使用XShell快捷方式登录,用户登录上传的哪个文件权限将属于该用户也是经常失误的地方。
 图2.42
图2.42
2)图5.11中,左边界面是宿主机中的界面,右边界面是虚拟机中的界面,下面界面是传输数据的进度条界面。可以在宿主机中找到要上传的文件,通过双击或者拖拽的方式将文件上传到虚拟机中;也可以在虚拟机中拖拽文件到宿主机中下载文件,通过XShell快捷方式登录到Xftp工具。虚拟机界面中目录位置是登录之前的位置,如果这个位置不是想要的位置,可在Xftp中通过选择栏进行选择。
将hadoop-2.6.5.tar.gz和jdk-8u131-linux-x64.tar.gz安装包文件上传到虚拟机software文件夹中,如图2.43所示。
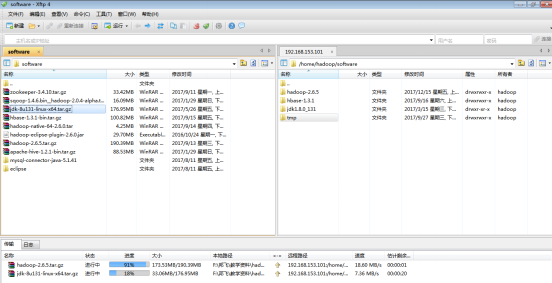 图2.43
图2.43
4. 安装JDK
1)在XShell中输入ls命令可以查看Xftp上传的文件内容,通过tar命令解压jdk-8u131-linux-x64.tar.gz压缩文件,操作如下:
[hadoop@Master001 software]$ ls
jdk-8u131-linux-x64.tar.gz
hadoop-2.6.5.tar.gz
[hadoop@Master001 software]$ tar -zxf jdk-8u131-linux-x64.tar.gz
[hadoop@Master001 software]$ ls
jdk-8u131-linux-x64.tar.gz
hadoop-2.6.5.tar.gz
jdk1.8.0_131
2)复制JDK安装目录
进入到jdk1.8.0_131目录,使用pwd命令打印jdk安装路径,利用鼠标选择复制路径。
[hadoop@Master001 software]$ cd jdk1.8.0_131/
[hadoop@Master001 jdk1.8.0_131]$ pwd
/home/hadoop/software/jdk1.8.0_131
3)配置环境变量
Linux系统中环境变量分为两种:全局变量和局部变量。profile文件是全局变量配置文件,只有管理员用户对profile文件才有写入权限,所以要编写profile文件需要切换到root用户,因为在全局变量中配置的环境变量对所有用户都有效。.bashrc文件是局部变量配置文件,在.bashrc文件配置的环境变量只对当前用户有效。
本文是配置的全局环境变量。操作如下:
[hadoop@Master001 jdk1.8.0_131]$ su root
密码:
[root@Master001 ~]# vi /etc/profile
插入(在最下面):
#java
export JAVA_HOME=/home/hadoop/software/jdk1.8.0_131
export PATH=$PATH:$JAVA_HOME/bin
4)使用环境变量生效
[root@Master001 ~]# source /etc/profile
5)验证JDK是否安装成功
输入java或者java -version,如果出现java命令的详细说明或者出现JDK版本号,表示安装成功,如果出现“-bash: dddd: command not found”表示安装失败。
6. 安装hadoop
1)切换到hadoop用户,并进入到software目录,使用ls命令可以查看Xftp上传的文件内容,通过tar命令解压hadoop-2.6.5.tar.gz压缩文件。操作如下:
[root@Master001 ~]# su hadoop
[hadoop@Master001 ~]$ cd software/
[hadoop@Master001 software]$ ls
jdk-8u131-linux-x64.tar.gz jdk1.8.0_131
hadoop-2.6.5.tar.gz
[hadoop@Master001 software]$ tar -zxf hadoop-2.6.5.tar.gz
[hadoop@Master001 software]$ ls
jdk-8u131-linux-x64.tar.gz jdk1.8.0_131
hadoop-2.6.5.tar.gz hadoop-2.6.5
2)进入hadoop安装目录
进入到hadoop-2.6.5目录,使用pwd命令打印hadoop安装路径,利用鼠标选择复制路径。
[hadoop@Master001 software]$ cd hadoop-2.6.5
[hadoop@Master001 hadoop-2.6.5]$ pwd
/home/hadoop/software/hadoop-2.6.5
3)配置hadoop环境变量
切换到root用户,编辑profile文件,并插入hadoop配置文件。操作如下:
[hadoop@Master001 hadoop-2.6.5]$ su root
密码:
[root@Master001 ~]# vi /etc/profile
插入:
#hadoop
export HADOOP_HOME=/home/hadoop/software/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
4)使环境变量生效
[root@Master001 ~]# source /etc/profile
5)验证hadoop安装是否成功
输入hadoop命令,如果出现hadoop命令相关的详细信息,表示安装成功;如果出现“-bash: dddd: command not found”,表示安装失败。
6)配置core-site.xml文件
关于Hadoop配置文件的讲解视频可扫描二维码观看。【配置Hadoop文件】
切换到hadoop用户,进入到hadoop-2.6.5/etc/hadoop/目录,编辑core-site.xml文件。
[root@Master001 ~]# su hadoop
[hadoop@Master001 ~]$ cd software/hadoop-2.6.5/etc/hadoop/
[hadoop@Master001 hadoop]$ ls
core-site.xml mapred-site.xml salves
hadoop-env.cmd hdfs-site.xml yarn-site.xml
......
[hadoop@Master001 hadoop]$ vi core-site.xml
插入:
<configuration>
<!--指定HDFS存储入口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master001:9000</value>
</property>
<!--指定hadoop临时目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/software/hadoop-2.6.5/tmp</value>
</property>
</configuration>
7)配置hadoop-env.sh文件
编辑hadoop-env.sh文件,修改java_home地址,java_home地址是解压的jdk地址,配置java_home是为了使用java的现实。
修改:
# The java implementation to use.
export JAVA_HOME=/home/hadoop/software/jdk1.8.0_131
8)配置hdfs-site.xml文件
hdfs-site.xml文件是hadoop2.0以后版本的必备配置文件之一,可以在hdfs-site.xml配置集群名字空间、访问端口、URL地址、故障转移等配置。
[hadoop@Master001 hadoop]# vi hdfs-site.xml
插入:
<configuration>
<!--配置数据备份数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--设置secondaryNamenode运行的节点-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Slave002:50070</value>
</property>
</configuration>
9)配置mapred-site.xml文件
在hadoop包里是没有mapred-site.xml文件,需要通过mapred-site.xml.template模版文件复制出mapred-site.xml文件。操作如下:
[hadoop@Master001 hadoop]# cp mapred-site.xml.template mapred-site.xml
[hadoop@Master001 hadoop]# vi mapred-site.xml
插入:
<configuration>
<!--设置jar程序启动Runner类的main方法运行在yarn集群中-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
10)配置slaves文件
hadoop集群中所有的datanode节点都需要写入到slaves文件中,因为它是用来指定存储数据的节点文件,Master会读取salves文件来获取存储信息,根据slaves文件来做资源平衡。
注意:
(1)slaves文件名全部是小写,有很多初学者使用vi Slaves来编辑slaves文件,它将会在hadoop目录中重新创建一个首字母为大写的slaves文件,这样是错误的;
(2)slaves文件打开后里面有一个“localhost”,这个localhost需要把删除,如果没有删除集群会把Master也当做DataNode节点,这样会造成Master节点负载过重。
[hadoop@Master001 hadoop]# vi slaves
删除:
localhost
插入:
Slave001
Slave002
Slave003
11)配置yarn-site.xml
yarn-site.xml文件是ResourceManager进程相关配置参数。
[hadoop@Master001 hadoop]# vi yarn-site.xml
插入:
<configuration>
<!--设置对外暴露的访问地址为Master001-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master001</value>
</property>
<!--NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
6. 安装ssh
ssh是一种远程传输通信协,用于两台或多台节点之间数据传输。通过yum方式在线安装ssh,yum是在线安装工具,因此使用yum安装时必须连接网络。yum是一个Shell前端软件包管理器,它能够从yum服务器自动下载rpm包然后安装,一次安装完成所有需要的软件包,不必一次次的下载,非常的简单方便。
1)yum工具属于root用户工具,所以需要切换到root用户进行在线安装。
[hadoop@Master001 hadoop]$ su root
密码:
[root@Master001 ~]#
2)在安装ssh之前需要先查找yum库有哪些ssh软件的rpm包。
[root@Master001 ~]# yum list | grep ssh
openssh.x86_64 5.3p1-84.1.el6 updates
openssh-server.x86_64 5.3p1-123.el6_9 updates
openssh-clients.x86_64 5.3p1-123.el6_9 updates
......
3)使用yum工具在线安装server和clients软件。
[root@Master001 ~]# yum install -y openssh-clients.x86_64
[root@Master001 ~]# yum install -y openssh-server.x86_64
安装过程如图2.44所示。
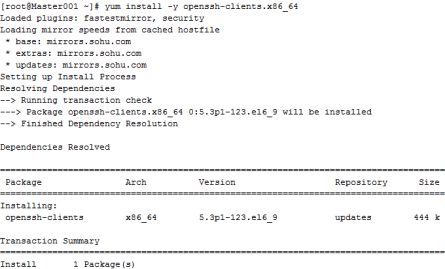 图2.44
图2.44
4)验证ssh是否安装成功
验证方法一:输入ssh命令,如果出现ssh命令的详细信息表示安装成功,如果出现" -bash: dddd: command not found"则表示安装失败。
[root@Master001 ~]# ssh
usage: ssh [-1246AaCfgKkMNnqsTtVvXxYy] [-b bind_address] [-c cipher_spec]
[-D [bind_address:]port] [-e escape_char] [-F configfile]
[-I pkcs11] [-i identity_file]
[-L [bind_address:]port:host:hostport]
[-l login_name] [-m mac_spec] [-O ctl_cmd] [-o option] [-p port]
[-R [bind_address:]port:host:hostport] [-S ctl_path]
[-W host:port] [-w local_tun[:remote_tun]]
[user@]hostname [command]
验证方法二:使用rpm工具验证。输入rpm -qa | grep ssh命令查找已经安装的ssh相关程序,如果出现server和clients表示安装成功。
[root@Master001 ~]# rpm -qa | grep ssh
openssh-server-5.3p1-123.el6_9.x86_64
openssh-clients-5.3p1-123.el6_9.x86_64
libssh2-1.4.2-1.el6.x86_64
openssh-5.3p1-123.el6_9.x86_64
7 复制虚拟机
现在已经安装好一台节点虚拟机的配置,其它四台节点虚拟机可以通过复制的方式来安装,但在复制虚拟机之前需要先把虚拟机关机。
1. 关闭虚拟机(halt命令需要root权限)
[root@Master001 ~]# halt
2. 复制虚拟机
复制出另它四台虚拟机,并把复制的文件夹重新命名为Master001、Slave001、Slave002、Slave003方便管理,如图2.45所示。
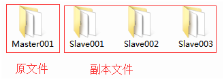 图2.45
图2.45
3. 打开虚拟机
1)通过“文件-->打开”选择复制的虚拟机来打开虚拟机。为了方便管理需将虚拟名字修改为文件夹名称,如图2.46所示。
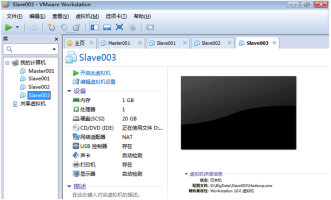 图2.46
图2.46
2)启动虚拟机
单击左边虚拟机名称,待右边出现对应的界面后,单击“开启此虚拟机”按钮打开虚拟机,如图2.47所示。
 图2.47
图2.47
3)选择“我已复制该虚拟机”
每一台计算机都有一个唯一的MAC地址,虚拟机也是一样。虽然它是虚拟状态的,但它同样有内存、处理器、硬盘和MAC地址等。虚拟机是通过复制出另一台一模一样的虚拟机,包括MAC地址,所以需要在启动副本虚拟机时选择“我已复制该虚拟机”按钮来告诉VMware平台“我这台虚拟机需要重新生成一个新的MAC地址”。如果选择“我已移动该虚拟机”按钮,VMware平台将不会为新虚拟机生成新的MAC地址,如图2.48所示。
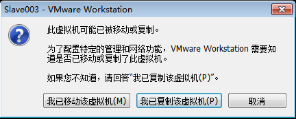 图2.48
图2.48
4. 修改虚拟配置
1)查看MAC地址
修改MAC地址之前需要到70-persistent-net.reles文件去查看最新的MAC地址,最后的一条为最新的MAC地址,并记住ATTR和NAME的值,如图2.49所示。
[root@Master001 ~]# cat /etc/udev/rules.d/70-persistent-net.rules
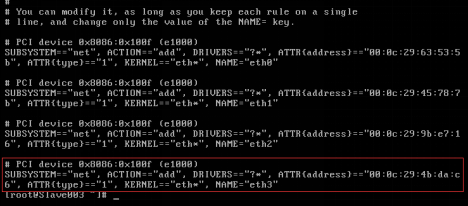 图2.49
图2.49
2)修改MAC地址和IP地址
需要到profile文件中修改最新的MAC地址和网络名称,按之前约定的配置规则来修改IP地址,如图2.50所示。
[root@Master001 ~]# vi /etc/sysconfig/network-scripts/ifcfg-eth0
改写:
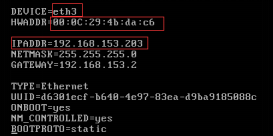 图2.50
图2.50
3)修改主机名
按之前约定的配置规则来修改主机名。
[root@Master001 ~]# vi /etc/sysconfig/network
改写:
HOSTNAME=Slave003
4)使修改生效
如果只是修改profile文件,可以重启网络服务即可使修改生效。如果修改主机名,需要重启虚拟机才能生效。
[root@Master001 ~]# reboot
5)验证修改是否成功
如果登录主机名变成修改的主机名表示主机名修改成功,如图2.51所示。
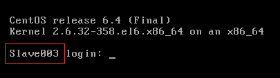 图2.51
图2.51
输入用户名和密码登录后,输入ifconfig命令,如果出现修改后的网络名称和IP地址表示静态IP修改成功,如图2.52所示。
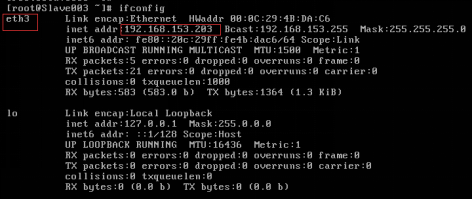 图2.52
图2.52
5. 修改其它虚拟机
依次操作“5.2.3.2小节、复制虚拟机”修改其它几台虚拟机,当所有虚拟机都修改完成后可以互相ping IP地址或主机名来验证内网是否联通。
[hadoop@Slave003 ~]$ ping 192.168.153.101
PING 192.168.153.101 (192.168.153.101) 56(84) bytes of data.
64 bytes from 192.168.153.101: icmp_seq=1 ttl=64 time=0.797 ms
64 bytes from 192.168.153.101: icmp_seq=2 ttl=64 time=0.774 ms
^C
--- 192.168.153.101 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1876ms
rtt min/avg/max/mdev = 0.774/0.785/0.797/0.030 ms
[hadoop@Slave003 ~]$ ping Master001
PING Master001 (192.168.153.101) 56(84) bytes of data.
64 bytes from Master001 (192.168.153.101): icmp_seq=1 ttl=64 time=1.69 ms
64 bytes from Master001 (192.168.153.101): icmp_seq=2 ttl=64 time=0.703 ms
^C
--- Master001 ping statistics ---
2 packets transmitted, 3 received, 0% packet loss, time 2391ms
rtt min/avg/max/mdev = 0.703/1.061/1.697/0.452 ms
2.5 设置SSH免密
安装Hadoop之前,由于集群中大量主机进行分布式计算需要相互进行数据通信,服务器之间的连接需要通过ssh来进行,所以要安装ssh服务。默认情况下通过ssh登录服务器需要输入用户名和密码进行连接,如果不配置免密码登录,每次启动hadoop都要输入密码用来访问每台机器的DataNode,因为Hadoop集群都有上百或者上千台机器,靠人力输入密码工程耗大,所以一般都会配置ssh的免密码登录。在hadoop集群中Master节点需要对所有节点进行访问,了解每个节点的健康状态,所以只需要对Master做免密设置,该集群是高可用集群,有两个Master。这两个Master都需要生成自己的私密,然后对所有节点(包括自己)传输密钥,以Master001为例,Master002只需要执行Master001相同操作即可。具体操作如下。
1. 生成密钥
密钥就像是进入一扇门的钥匙,生成密钥就是生成这把钥匙。由于要对hadoop用户进行免密设置,所以需要切换到hadoop用户,并回到该用户的家目录。
执行ssh-keygen -t rsa -P '' 命令后将在/home/hadoop/.ssh/目录下以rsa方式生成id_rsa的密钥。
[hadoop@Master001 ~]$ cd ~
[hadoop@Master001 ~]$ ssh-keygen -t rsa -P ''
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): (出现此段后按enter继续)
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
2c:a9:91:36:4b:18:e6:09:60:f9:1a:22:23:3b:d6:af hadoop@Master001
The key's randomart image is:
+-------[ RSA 2048]-----+
|... |
|o. |
|. + |
|== = . o |
|+oB * o S |
|oo + = . |
|.. + |
| . |
| E. |
+-----------------------+
2. 对所有节点进行免密
将密钥分发给集群中所有节点(包括自己),就免去输入密码去访问其它虚拟机。执行ssh-copy-id命令后,会将id_rsa中的密钥传输到目标虚拟机的/home/hadoop/.ssh/authorized_keys文件中。
[hadoop@Master001 ~]$ ssh-copy-id Master001
hadoop@master001's password:(输入Master001密码)
Now try logging into the machine, with "ssh 'Master001'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[hadoop@Master001 ~]$ ssh-copy-id Slave001
hadoop@slave001's password: (输入Slave001密码)
Now try logging into the machine, with "ssh 'Slave001'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[hadoop@Master001 ~]$ ssh-copy-id Slave002
hadoop@slave002's password: (输入Slave002密码)
Now try logging into the machine, with "ssh 'Slave002'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[hadoop@Master001 ~]$ ssh-copy-id Slave003
hadoop@slave003's password: (输入Slave003密码)
Now try logging into the machine, with "ssh 'Slave003'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
3. 验证免密设置是否成功
验证免密是免密设置最关键的一步,如果不输入密码就能访问到目标虚拟机,表示免密设置成功。
[hadoop@Master001 ~]$ ssh Master001
Last login: Tue Dec 19 14:44:02 2017 from 192.168.153.1
[hadoop@Master001 ~]$ exit
logout
Connection to Master001 closed.
[hadoop@Master001 ~]$ ssh Slave001
Last login: Fri Dec 15 08:38:54 2017 from 192.168.153.1
[hadoop@Slave001 ~]$ exit
logout
Connection to Slave001 closed.
[hadoop@Master001 ~]$ ssh Slave002
Last login: Fri Dec 15 08:38:56 2017 from 192.168.153.1
[hadoop@Slave002 ~]$ exit
logout
Connection to Slave002 closed.
[hadoop@Master001 ~]$ ssh Slave003
Last login: Tue Dec 19 14:44:05 2017 from 192.168.153.1
[hadoop@Slave003 ~]$ exit
logout
Connection to Slave003 closed.
[hadoop@Master001 ~]$
2.6 启动Hadoop集群
1. 在Master001中格式化namenode
在Master001中格式化namenode会生成~/software/hadoop-2.6.5/tmp目录,该目录中存放版本号和元数据等相关信息。
[hadoop@Master001 ~]$ hdfs namenode -format
2. 传送tmp文件到其它节点
[hadoop@Master001 ~]$ cd ~/software/hadoop-2.6.5/
[hadoop@Master001 hadoop-2.6.5]$ ls
bin etc ... sbin share tmp
[hadoop@Master001 hadoop-2.6.5]$ scp -r tmp/ Slave001:~/software/hadoop-2.6.5/
[hadoop@Master001 hadoop-2.6.5]$ scp -r tmp/ Slave002:~/software/hadoop-2.6.5/
[hadoop@Master001 hadoop-2.6.5]$ scp -r tmp/ Slave003:~/software/hadoop-2.6.5/
3. 启动hdfs
启动hdfs只需要在Master001中执行start-dfs.sh 即可。它分别会在Master001启动namenode进程,在Slave001、Slave002和Slave003中启动datanode进程。
[hadoop@Master001 ~]$ start-dfs.sh
Starting namenodes on [Master001]
Master001: starting namenode, logging to /home/hadoop/software/hadoop-2.6.5/logs/hadoop-hadoop-namenode-Master001.out
Slave002: starting datanode, logging to /home/hadoop/software/hadoop-2.6.5/logs/hadoop-hadoop-datanode-Slave002.out
Slave003: starting datanode, logging to /home/hadoop/software/hadoop-2.6.5/logs/hadoop-hadoop-datanode-Slave003.out
Slave001: starting datanode, logging to /home/hadoop/software/hadoop-2.6.5/logs/hadoop-hadoop-datanode-Slave001.out
Starting journal nodes [Slave001 Slave002 Slave003]
Slave003: starting journalnode, logging to /home/hadoop/software/hadoop-2.6.5/logs/hadoop-hadoop-journalnode-Slave003.out
Slave001: starting journalnode, logging to /home/hadoop/software/hadoop-2.6.5/logs/hadoop-hadoop-journalnode-Slave001.out
Slave002: starting journalnode, logging to /home/hadoop/software/hadoop-2.6.5/logs/hadoop-hadoop-journalnode-Slave002.out
4. 启动MapReduce
启动MapReduce只需要在Master001中执行start-yarn.sh 即可。它分别会在Master001启动resourcemanager进程,在Slave001、Slave002和Slave003中启动nodemanager进程。
[hadoop@Master001 ~]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/software/hadoop-2.6.5/logs/yarn-hadoop-resourcemanager-Master001.out
Slave003: starting nodemanager, logging to /home/hadoop/software/hadoop-2.6.5/logs/yarn-hadoop-nodemanager-Slave003.out
Slave001: starting nodemanager, logging to /home/hadoop/software/hadoop-2.6.5/logs/yarn-hadoop-nodemanager-Slave001.out
Slave002: starting nodemanager, logging to /home/hadoop/software/hadoop-2.6.5/logs/yarn-hadoop-nodemanager-Slave002.out
4. 验证集群是否成功启动
当集群启动成功后每个节点中都有一些必须存在的进程。具体进程如下:
[hadoop@Master001 ~]$ jps
3766 Jps
3510 ResourceManager
3118 NameNode
[hadoop@Slave001 ~]$ jps
2610 NodeManager
2500 DateNode
2745 Jps
[hadoop@Slave002 ~]$ jps
2675 Jps
2549 NodeManager
2439 DateNode
2297 SencodaryManager
[hadoop@Slave003 ~]$ jps
2737 Jps
2611 NodeManager
2501 DateNode

 浙公网安备 33010602011771号
浙公网安备 33010602011771号