UCB-CS61C 笔记
Great Ideas in Computer Architecture (Machine Structure)
这个暑假来 Berkeley 上课,所以记录一下,也方便期中和期末考试复习(也许还能帮到当地的中国学生hhh)
老师是一个漂亮姐姐 + 两个看着就很 tech 的老哥,看名字就像中国人(难怪英语那么好懂,楽)
Number Representation
一些十六进制二进制之类的东西,还有原码反码补码,比较简单,注意以下几个术语的英文即可,都是国内数电课的东西,已经玩的很熟了
反码: Sign and Magnitude
补码: Two's Complement
移码: Bias Notation
一个有意思的东西: 在 C 中可以用 x==y 来当按位同或运算
Floating Point
这里有一个在线转换的网站: IEEE-754 Floating Point Converter
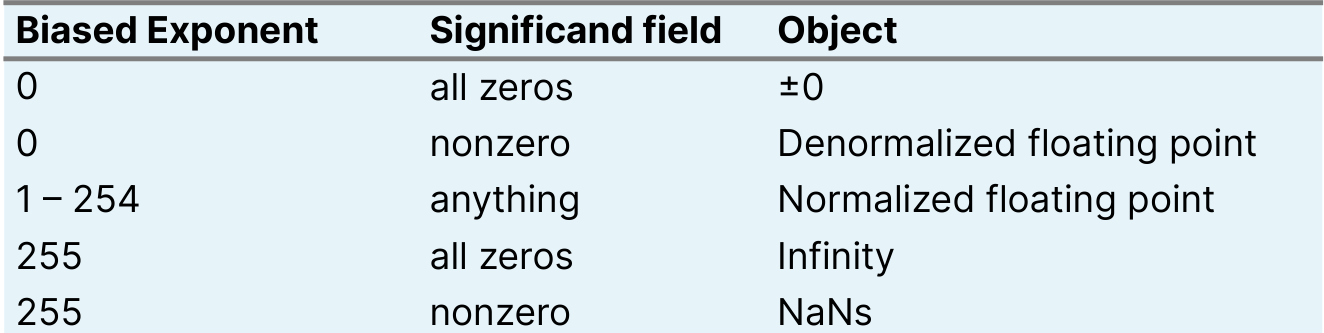
Normalized

值就是 \((-1)^s \times (1.significand) \times 2^{exponent-bias}\),其中 \(bias=2^{k-1}-1 = 127\)
C basic
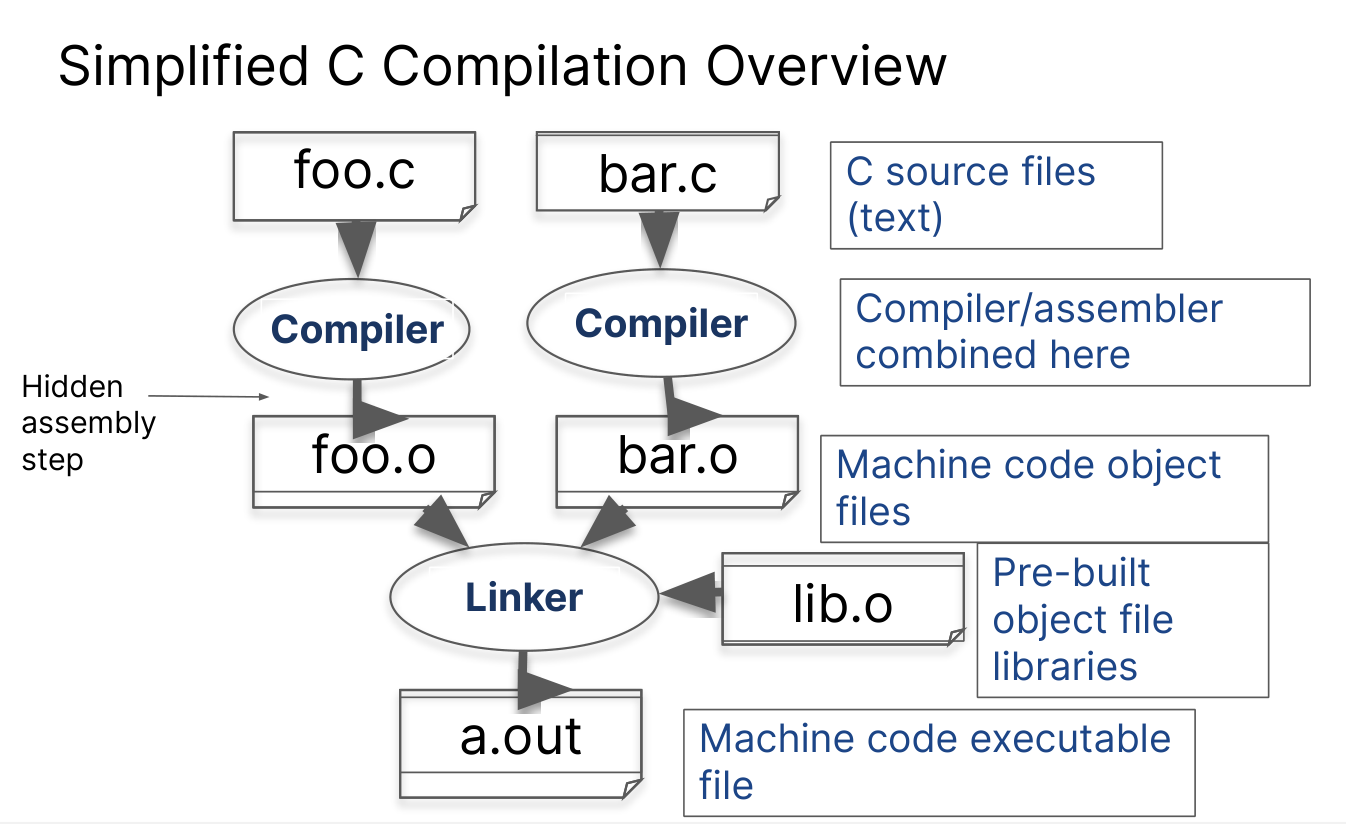
Compilation: Overview
With C, there is generally a 3-part process in handling a .c file
.cfiles are **compiled **into.sfiles ⇒ compilation by the compiler.sfiles are **assembled **into.ofiles ⇒ assembly by the assembler (this step is generally
hidden, so most of the time we directly convert.cfiles into.ofiles).ofiles are **linked **together to create an executable ⇒ linking by the linker
C Pre-Processor (CPP)
- C source files first pass through macro processor, CPP, **before **compiler sees code
- CPP replaces comments with a single space
- CPP commands begin with “#” (e.g. #include, #define)
- Use –save-temps option to gcc to see result of preprocessing
注意: CPP Macro 定义的“函数”实际上并不是函数,只是字符串替换,有时会产生意想不到的副作用,比如以下函数会调用 2 次 foo(z),而不是 1 次
#define min(X,Y) ((X)<(Y)?(X):(Y))
next = min(w, foo(z));
// CPP 替换后
next = ((w)<(foo(z))?(w):(foo(z)));
Memory Structure

- Code/text: 在 read-execute memory 中,放代码(包括代码里面的常数比如
x=y+1里面的1) - Static/data: 在 RAM 中,放全局变量和静态变量,可以被修改(但是一般没必要)
- Heap: 放动态分配的内存,记住需要手动释放,Grows bottom-up
- Stack: 放函数调用的参数和局部变量等,Grows top-down
Stack Management
存放函数调用的参数和局部变量,以及局部常数和局部函数信息
任何一个函数被调用的时候,都会自动在栈上分配一块区域,叫做 stack frame(栈帧)
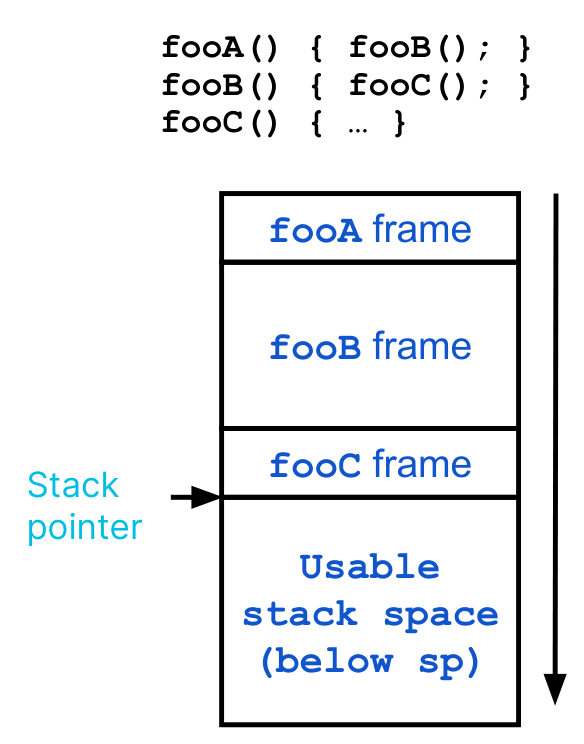
- 栈帧是连续的,并且栈指针指向当前栈帧的开始处
- 函数调用结束时栈帧会被释放,栈指针会回到上一个栈帧的开始处
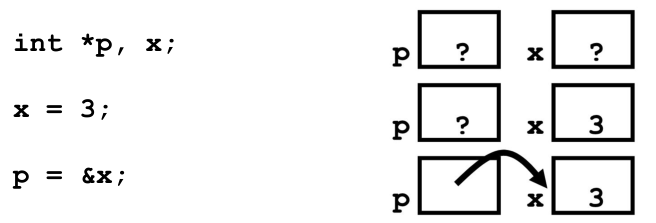
Pointers
A variable that contains the address of a variable.
&operator: get address of a variable*“dereference operator”: get value pointed to
Pros
- If we want to pass a large struct or array, it’s easier / faster / etc. to pass a pointer than the whole thing
- In general, pointers allow cleaner, more compact code
Cons
Declaring a pointer just allocates space to hold the pointer – it does not allocate something to be pointed to!
Local variables in C are not initialized, they may contain anything.
看下面这段代码
void f()
{
int *ptr;
*ptr = 5;
}
Effective Usage
最典型的就是 swap 函数
我们还可以用来指代函数(就像 CS61A 里面那样,好酷炫)
int (*fn) (void *, void *) = &foo
fn is a function that accepts two void * pointers and returns an int and is initially pointing to the function foo.
(*fn)(x, y) will then call the function
注意指针的算术运算
pointer + n : Adds n*sizeof(“whatever pointer is pointing to”) to the memory address
下面是一个很 tricky 的东西,事实上指针深度可以一直叠加
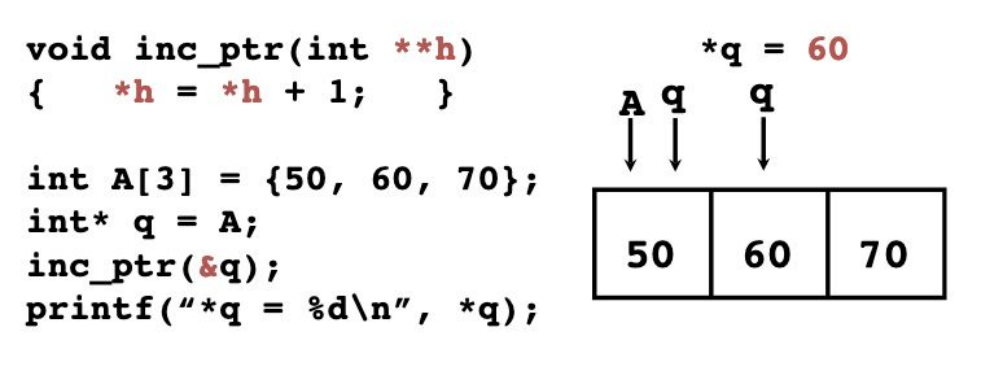
Memory Allocation
-
malloc: memory allocation -
calloc: cleared allocation(会先把内存清零)-
void *calloc(size_t nitems, size_t size)
-
-
realloc: re-allocation
动态分配的都在 Heap 中,并且之后必须被 free
另一个条件是被分配的内存必须连续(这意味这必须按照 LIFO 原则来释放内存),如下图,分配申请将会失败产生 Fragmentation
Defined as when most of memory has been allocated in large or smaller (but more
frequently, smaller) non-sequential chunks
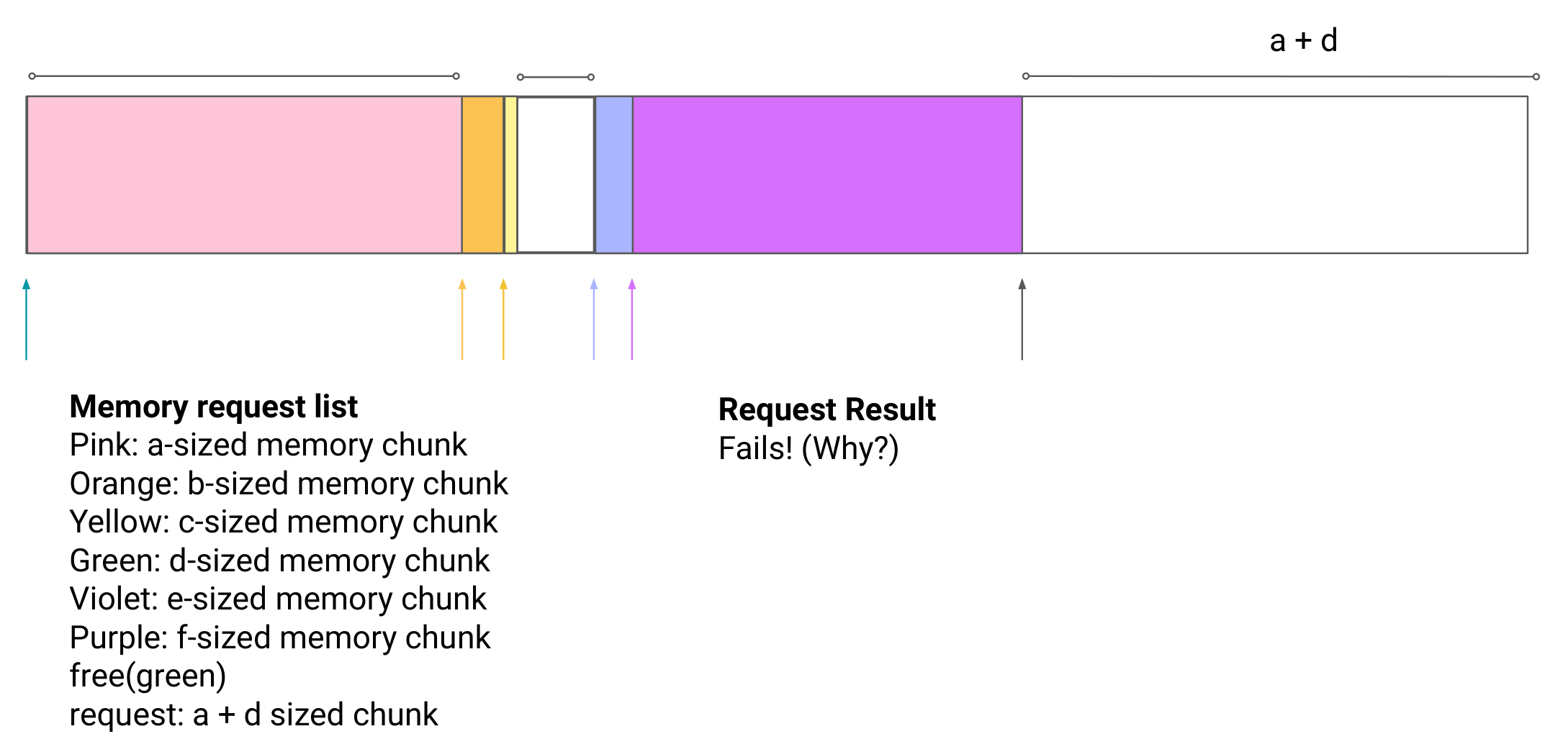
Dynamic Allocation in C
内存申请不会作任何检查,所以一定要注意!
ptr = (int *) malloc (sizeof(int));
ptr = (int *) malloc (n*sizeof(int));//相当于数组
//...
free(ptr);//一定要记得释放
realloc(p, size) 的作用是把 p 重新指向一块大小为 size 的地方。如果请求失败,则返回 NULL。注意并不是在原来的基础上扩展或者缩小,而是重新寻找新的地方。
以下是几个常见的错误
-
Use After Free
struct foo *f .... f = malloc(sizeof(struct foo)); .... free(f) .... bar(f->a);会读/写到不该被读/写的数据
-
Forgetting realloc Can Move Data
struct foo *f = malloc(sizeof(struct foo) * 10); .... struct foo *g = f; .... f = realloc(sizeof(struct foo) * 20);Result is
gmay now point to invalid memory -
Freeing the Wrong Stuff
struct foo *f = malloc(sizeof(struct foo) * 10) ... f++; ... free(f); -
Double free
struct foo *f = (struct foo *) malloc(sizeof(struct foo) * 10); ... free(f); ... free(f); -
Losing the initial pointer
int *plk = NULL; void genPLK() { plk = malloc(2 * sizeof(int)); ... ... ... plk++; }这可能导致内存泄漏!
我们可以用 Valgrind 来检查内存错误
Endianness
Big-Endian(大端) 就是从左往右按人正常理解那样,Little-Endian(小端) 相反
注意 Struct 在内存中的存储顺序取决于系统是大端还是小端(要把整个 Struct 当做一个大的变量理解)
String
注意两种不同的定义方式:
char* s = "string" 这会存在 Static 区,并且无法改动
char s[7] = "string" 存在 Stack 区,可以改
RISC-V
Register
- 一共 32 个:
x0-x31 x0永远是 0 ,所以一共有 31 个可用的
Instructions
语法如下图,比如 sub x5 x6 x7 意思就是 把x6 中存储的值减去 x7 中的,然后得到的值存到 x5 里面
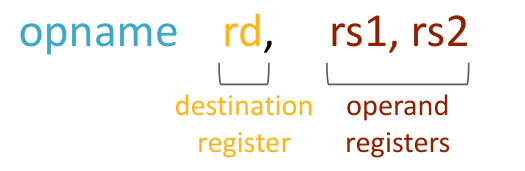
其他的指令很好理解,记住目标操作数在前即可
还有两个存储相关的指令要记住,一个例子如下
-
C:
A[10] = h + A[3]; -
RISC-V:
lw x10,12(x15) # Temp reg x10 gets A[3] add x10,x12,x10 # Temp reg x10 gets h + A[3] sw x10,40(x15) # A[10] = h + A[3]
其中 x2=h,x15 是数组的起始地址
记住几个比较重要的指令(尤其是跳转)
-
jal x1 Label(Jump and Link): Set x1 to PC+4 , then jump to Label- 注意! "set x1 to PC+4" 是 "把 x1 设置成 PC+4 的意思"
-
jalr x1 x5 0(Jump and Link Register): Set x1 to PC+4, then jump to the line of code at address x5+0 -
lui,auipc: “helpers” to let the pseudoinstructions “li” and “la” work. Rarely used independently.
Translate C to RISC-V
- It's common to negate the condition of the if clause.
- RISC-V branch philosophy: Skip this code if the condition is false.
- C if statement philosophy: Run this code if the condition is true.
Cache
Associativity
-
直接映射(Direct Mapped)
-
1-路相连
-
限制最大的 Cacha
-
每个地址只能映射到固定的一个 Cache line
-
好实现
-
-
-
全相连(Fully Associative)
- 与直接映射相反
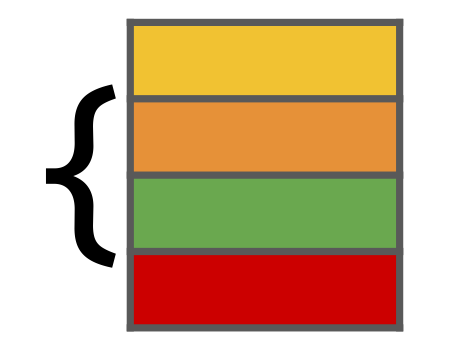
-
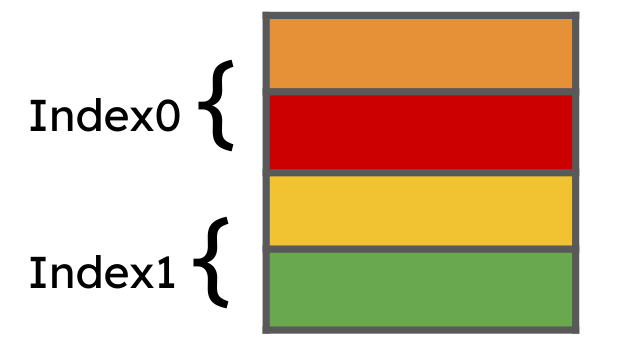
N-路组相连(N-way Set Associative)
- 下图即为2-路相连
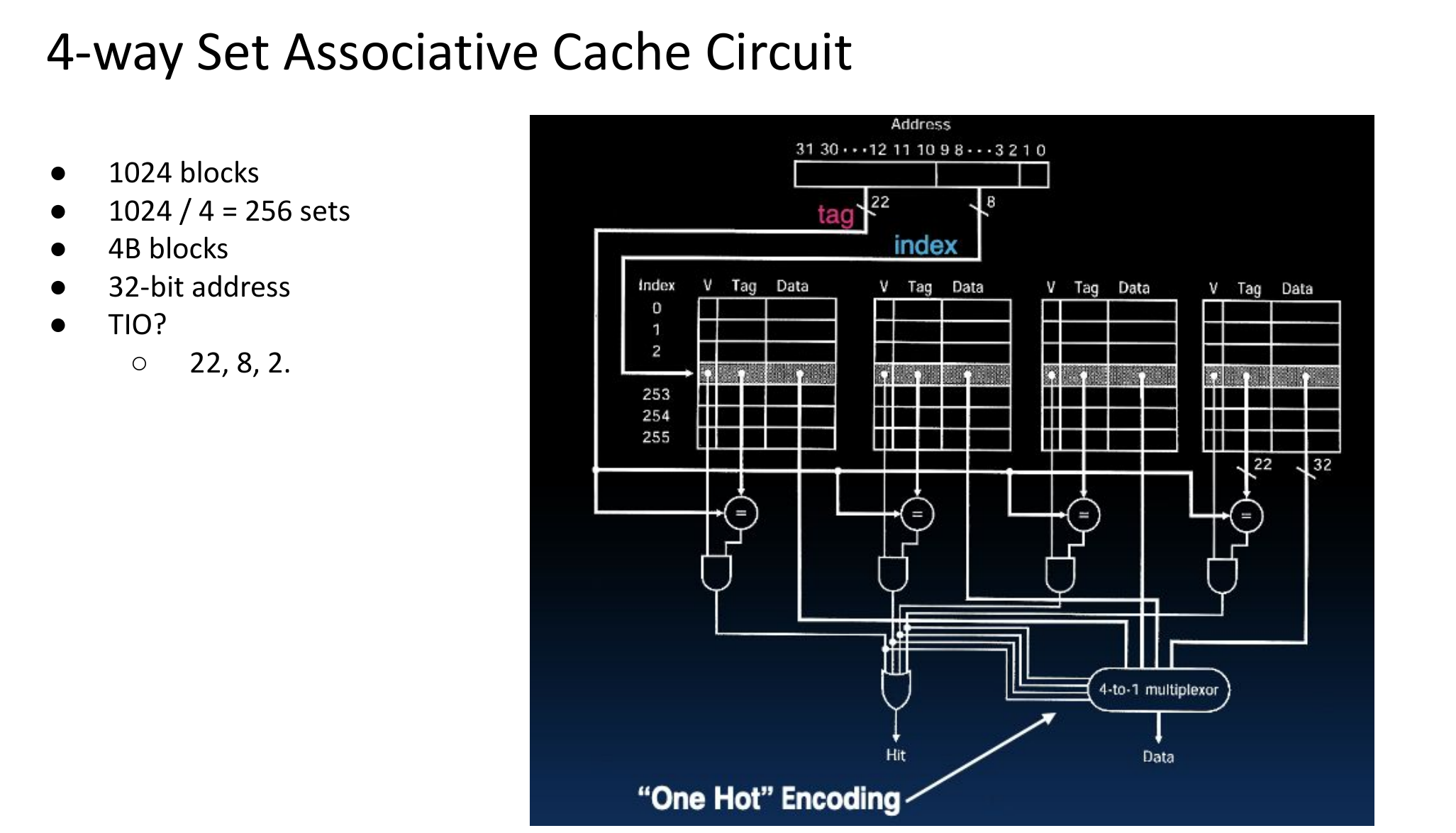
T/I/O
位置分布如下表所示
| tag | index | offset |
|---|
-
Tag
- 在一个 set 中,用于区分的 key
- # of bits = (# of address bits) - (# of index bits) - (# of offset bits)
-
Index
- 确定应该放入哪个set
- # of bits = log2(number of sets) = log2(cache size / (cache line size * associativity))
-
Offset
- 决定访问哪一个 byte
- # of bits = log2(bytes per cache line)
看完下图这个例子应该就懂了
单周期CPU中单条指令最小延迟就是关键路径延迟
Now, assume that the register file supports "write-then-read" functionality on the same clock cycle and that branch target addresses become available at the input of the PC register during the execution stage. Which of the following statements will be true?
- (c) Required number of unoptimized stalls for control hazard decreases by 1 cycle.
- (f) Required number of unoptimized stalls for structural/data hazard decreases by 1 cycle.
Required number of unoptimized stalls for structural/data hazard decreases by 1 cycle. This is true. If the register file supports "write-then-read" on the same cycle, then we can align the WB stage of the first instruction to the ID stage of the second (data dependent) instruction. Without the "write-then-read" functionality, we have to wait until after the WB stage of the first instruction to start the ID stage of the second (data dependent) instruction.
Required number of unoptimized stalls for control hazard decreases by 1 cycle. This is true. If the branch target address becomes available at the input of the PC register durign the execution stage, then the IF stage of the next instruction can start right after the EX stage of the branch instruction.
Compare this to the previous setup where the address becomes available during the MEM stage, which is one more cycle after EX.
Required number of optimized stalls for structural/data hazard decreases by 1 cycle. This is false. Data forwarding already makes the required number of stalls to 0, except for load instruction data dependency.
We cannot remove the 1 cycle stall for this hazard since the result only becomes available at the MEM stage, which is 1 cycle after the EX stage (where the result of most instructions become available).
Required number of optimized stalls for control hazard decreases by 1 cycle. This is false. With perfect branch prediction, we don't incur stalls anymore. Thus, we cannot further decrease that.
Some of the hazards from the previous question will disappear. This is false. The hazards will still be there since the data dependency is still present. Without data forwarding or branch prediction, we will still need to stall.
All the answers from the previous question remain the same. This is false. Statements 1 and 2 are true, so there will be a change in the answers from the previous question.
HW 4.3
HW 5.2
1.7-1.9
Q1.7:
//Negates all elements of A
int A[1048576];
initializedata(&A);
#pragma omp parallel
{
for (int i = 0; i < 1048576; i++)
if(i%omp_get_num_threads() == omp_get_thread_num())
A[i] = -A[i];
}
- (b) Correct result, slower than serial
Q1.7: This looks like it would be faster, but in practice, this will probably be slower, due to several inefficiencies.
For one, we are still going through all the iterations anyway, and just not doing anything on some iterations; it still takes a decent amount of time to run through the iteration, though; as such, it's better to modify the loop itself to skip iterations.
The second, more important issue, is that due to cache coherency issues, we lose almost all of the benefits of the L1 and L2 caches since the data keeps getting invalidated/dirtied.
Consecutive array addresses are being assigned on different threads which leads to false sharing (one thread on a processor core updates a cache block that is present on another processor core due to another thread, leading to invalidations).
lab8 task1的特判

 浙公网安备 33010602011771号
浙公网安备 33010602011771号