


Kmeans聚类算法
K-means聚类
目标:基于有限的指标将样本划分为K类
1,随机选定K个值作为初始聚类中心
2,求每个样本与K个聚中心的距离,取最近的中心,作为该样本的标记中心
3,求各个聚类簇的均值,得出k个新的中心点
如果与旧中心点一样,结束聚类过程
如果与旧中心点不一样,将新的中心点作为聚类中心重复第二步
确定K中心点个数的方法:1,经验法
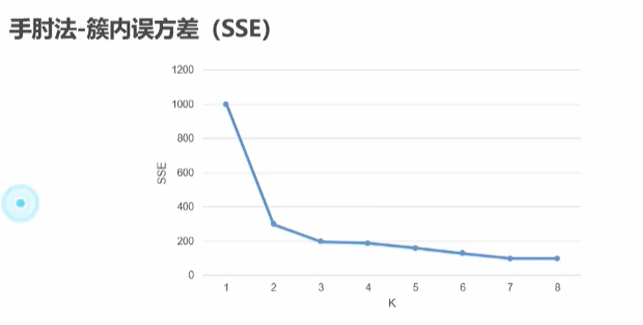
2,手肘法,通过观察中心点K数量和簇内误方差SSE相关曲线,找到最低的一个点就是最佳的K值
3,轮廓系数
sc=(bi-ai)/max(bi,ai)
ai:样本i到同簇其他样本的平均距离——簇内不相似度
bi:样本i到其他某簇的所有样本的平均距离取最小值——簇间不相似度
计算轮廓系数sc,越接近1越好
所有样本的sc的均值即为改聚类结果的均值

