对于hana数据库,两个节点、使用了pacemkaer软件进行了高可用的集群
首页、我们在开机后,使用 pcs cluster start --all ,将pacemaker服务启动起来,然后就是到了关机的维护模式
然后我们使用 pcs node unmaintenance --all 取消维护模式,资源才会被启动,可以观察到hana的pacemaker的状态变化,首先是如下所示:
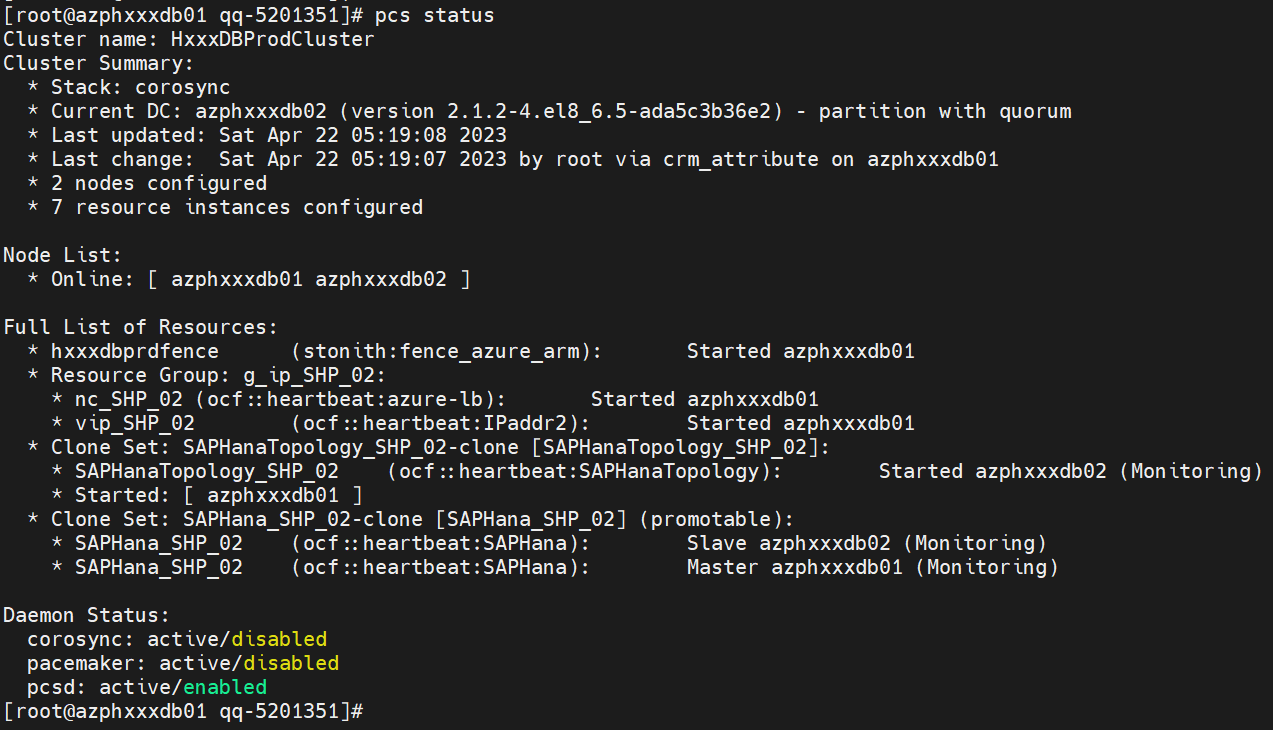
最后所以状态正常后,就会如下状态,那基本上hana数据库群集就正常状态了:
[root@azphxxxdb01 qq-5201351]# pcs status Cluster name: HxxxDBProdCluster Cluster Summary: * Stack: corosync * Current DC: azphxxxdb02 (version 2.1.2-4.el8_6.5-ada5c3b36e2) - partition with quorum * Last updated: Sat Apr 22 05:19:13 2023 * Last change: Sat Apr 22 05:19:07 2023 by root via crm_attribute on azphxxxdb01 * 2 nodes configured * 7 resource instances configured Node List: * Online: [ azphxxxdb01 azphxxxdb02 ] Full List of Resources: * hxxxdbprdfence (stonith:fence_azure_arm): Started azphxxxdb01 * Resource Group: g_ip_SHP_02: * nc_SHP_02 (ocf::heartbeat:azure-lb): Started azphxxxdb01 * vip_SHP_02 (ocf::heartbeat:IPaddr2): Started azphxxxdb01 * Clone Set: SAPHanaTopology_SHP_02-clone [SAPHanaTopology_SHP_02]: * Started: [ azphxxxdb01 azphxxxdb02 ] * Clone Set: SAPHana_SHP_02-clone [SAPHana_SHP_02] (promotable): * Masters: [ azphxxxdb01 ] * Slaves: [ azphxxxdb02 ] Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled [root@azphxxxdb01 qq-5201351]#
其实整个hanadb的群集资源组成如上,配置相对也简单,主要分4组/部分资源
stonith/fence资源相关,vip虚拟资源组,hanadb相关的配置、hanadb相关的状态部分
尊重别人的劳动成果 转载请务必注明出处:https://www.cnblogs.com/5201351/p/17346603.html
作者:一名卑微的IT民工
出处:https://www.cnblogs.com/5201351
本博客所有文章仅用于学习、研究和交流目的,欢迎非商业性质转载。
由于博主的水平不高,文章没有高度、深度和广度,只是凑字数,不足和错误之处在所难免,希望大家能够批评指出。
博主是利用读书、参考、引用、复制和粘贴等多种方式打造成自己的文章,请原谅博主成为一个卑微的IT民工!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号