基于Actor-Critic(A2C)强化学习的四旋翼无人机飞行控制系统matlab仿真
1.算法仿真效果
matlab2022a仿真结果如下(完整代码运行后无水印):
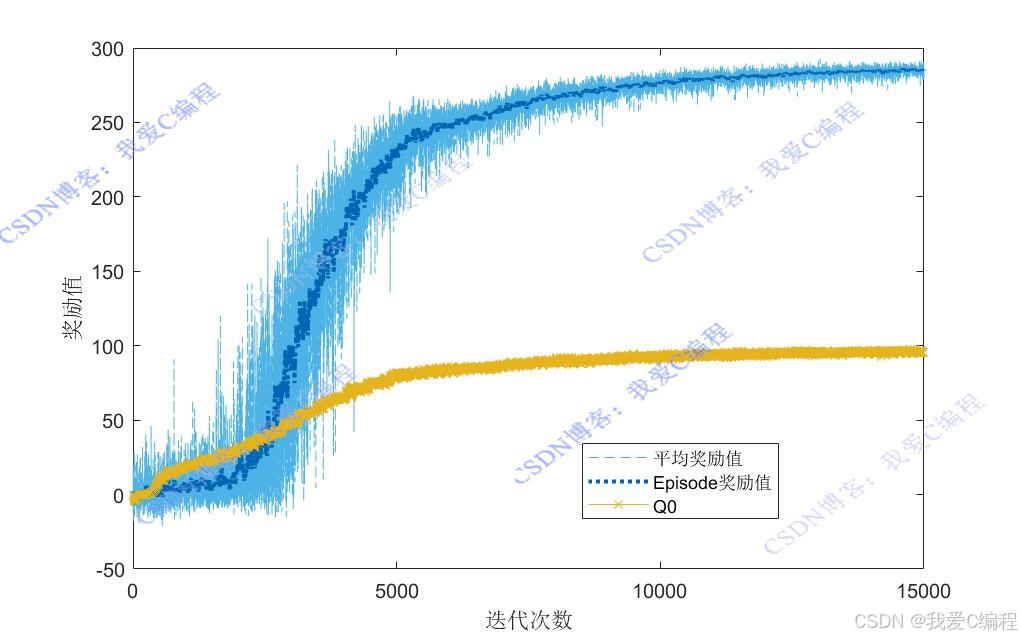
仿真操作步骤可参考程序配套的操作视频。
2.算法涉及理论知识概要
基于Actor-Critic强化学习的四旋翼无人机飞行控制系统是一种利用强化学习技术实现飞行器自主控制的方法。该方法通过构建Actor(策略网络)和Critic(价值网络)两个组件来学习最优控制策略。四旋翼无人机因其灵活性和广泛应用前景成为研究热点。传统的控制方法依赖于精确的数学建模和控制律设计,但在复杂和不确定环境下表现有限。
2.1 强化学习基础
强化学习的核心是马尔科夫决策过程(Markov Decision Process, MDP)。MDP由状态空间 S、动作空间A、转移概率P、即时奖励函数R 和折扣因子γ 构成。
策略 π:定义了智能体在给定状态下选择动作的概率分布。
价值函数:用于评估策略的好坏,主要包括状态价值函数Vπ(s) 和动作价值函数Qπ(s,a)。
2.2 Actor-Critic
Actor-Critic方法结合了策略梯度(Policy Gradient)和价值函数(Value Function)两种方法的优点,通过两个网络协同工作来优化策略。

2.3 四旋翼无人机飞行控制
四旋翼无人机的控制问题可以视为一个MDP,其中:
状态空间S 包括无人机的位置、速度、加速度、姿态等信息。
动作空间A 包括四个电机的推力输出。
即时奖励函数R 可以根据任务需求设计,如接近目标位置、保持姿态稳定等。
状态向量s 可以表示为:

动作向量a 可以表示为四个电机的推力输出:

基于Actor-Critic强化学习的四旋翼无人机飞行控制系统通过智能体与环境的交互学习最优控制策略,适用于多种复杂的飞行任务。随着算法的不断优化和完善,这种方法将在未来的无人系统开发中发挥更加重要的作用。
3.MATLAB核心程序
% 加载已训练好的代理
load trained\ac.mat
opts = rlSimulationOptions('MaxSteps',(Time2-Time1)/dt);% 设置最大步骤数
Rwd_all = zeros(Sim_times,1);% 初始化总奖励数组
Steps_all = zeros(Sim_times,1);% 初始化步数数组
for i = 1:Sim_times% 对于每次模拟
Exp_learn = sim(Environment,agent,opts);% 运行模拟并获取经验
Rwd_all(i) = sum(Exp_learn.Reward);% 计算并存储总奖励
end
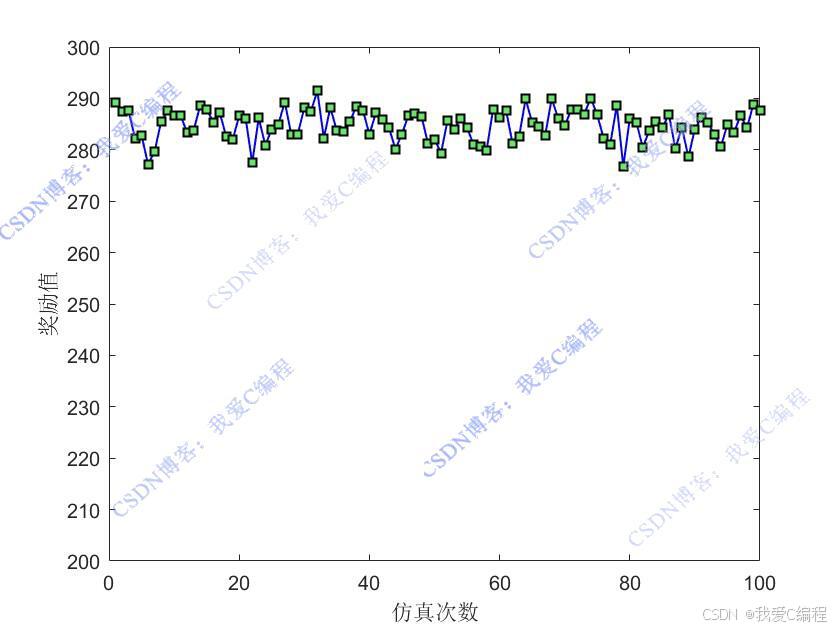
figure;
plot(Rwd_all,'-bs',...
'LineWidth',1,...
'MarkerSize',6,...
'MarkerEdgeColor','k',...
'MarkerFaceColor',[0.4,0.9,0.4]);
xlabel('仿真次数');
ylabel('奖励值');
ylim([200,300])
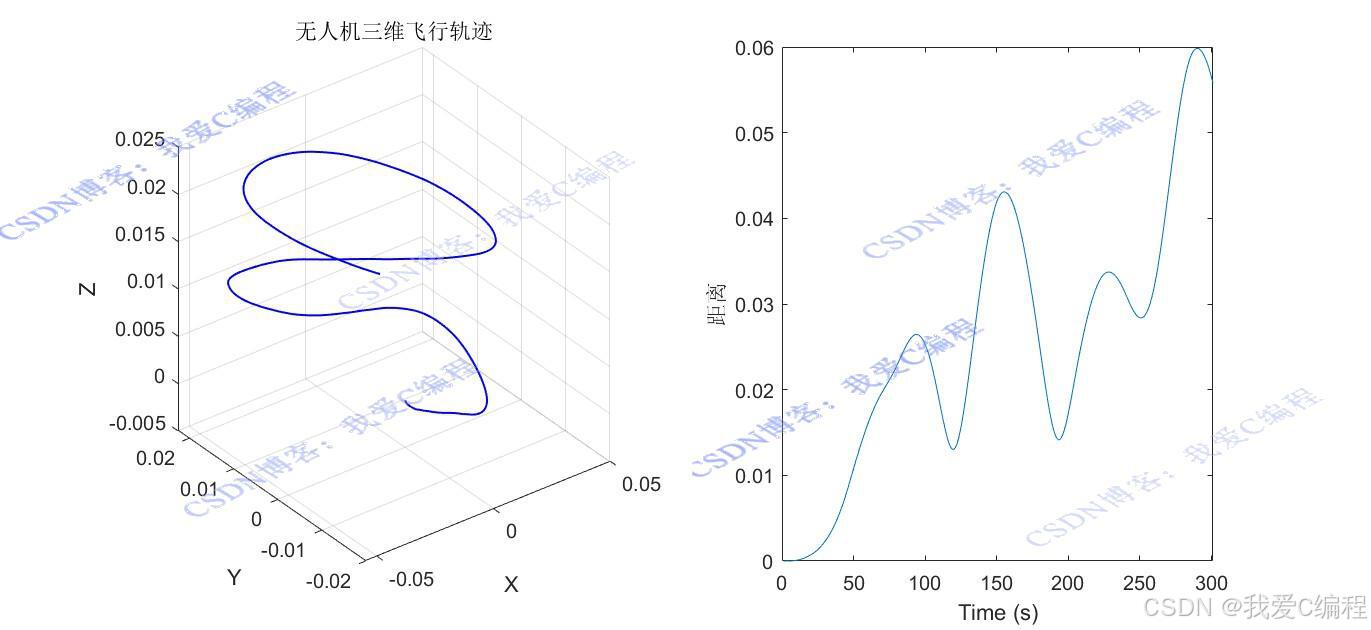
% 提取模拟中的位置数据
Xs = Exp_learn.Observation.Quad.Data(1,:);% 获取X方向位移
Ys = Exp_learn.Observation.Quad.Data(2,:);% 获取Y方向位移
Zs = Exp_learn.Observation.Quad.Data(3,:);% 获取Z方向位移
dist = sqrt((Xs).^2 + (Ys).^2 + (Zs).^2);
figure
subplot(1,2,1)
plot3(Xs,Ys,Zs,'-b',...
'LineWidth',1,...
'MarkerSize',6,...
'MarkerEdgeColor','k',...
'MarkerFaceColor',[0.9,0.0,0.0]);
grid on
xlabel('X')
ylabel('Y')
zlabel('Z')
title('无人机三维飞行轨迹');
subplot(1,2,2)
plot(dist)
xlabel('Time (s)')
ylabel('距离')
0Z_009m

 浙公网安备 33010602011771号
浙公网安备 33010602011771号