基于Qlearning强化学习的小车弧线轨迹行驶控制matlab仿真
1.算法仿真效果
matlab2022a仿真结果如下(完整代码运行后无水印):
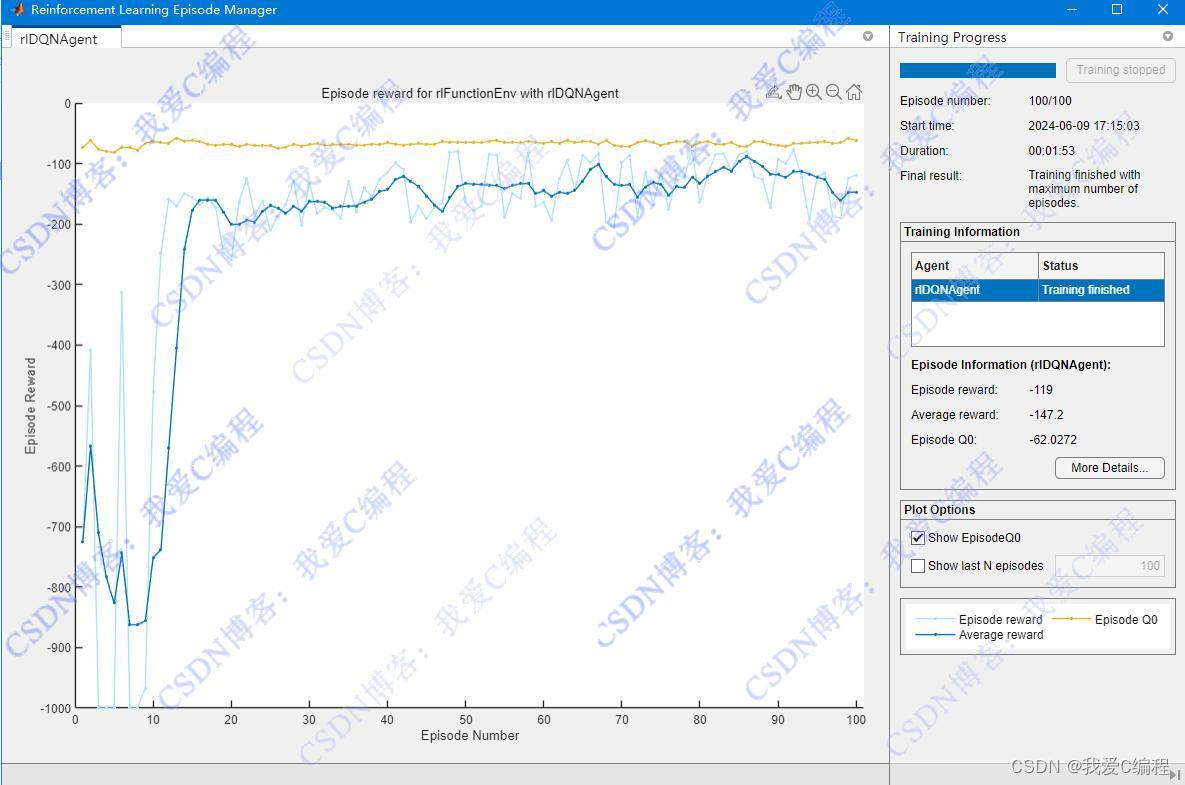
2.算法涉及理论知识概要
Q-learning是一种离散时间强化学习算法,无需模型即可直接从环境中学习最优策略。当应用于小车弧线轨迹行驶控制时,其核心任务是让小车自主学习如何控制转向和速度,以在指定的曲线上稳定行驶。
2.1强化学习基础
强化学习的基本框架由四部分组成:环境(Environment)、代理(Agent)、状态(State)、动作(Action)和奖励(Reward)。代理根据当前状态采取行动,环境反馈新的状态和奖励,代理的目标是最大化累积奖励。
2.2 环境建模与状态空间
对于小车弧线行驶任务,环境可以简化为二维平面,其中小车的位置和朝向是关键状态变量。状态空间S可以定义为小车的位置坐标x,y)、朝向角θ以及可能的其他因素(如速度、曲率等),即S={(x,y,θ,...)}。为简化起见,可以假设状态空间离散化,每个维度划分为若干区间。
2.3 动作空间
动作空间A定义了小车可以执行的所有控制操作,比如前进、后退、左转、右转以及不同速度的组合。同样,动作空间也应离散化处理,例如: A={加速,减速,左转,右转,直行}
2.4 奖励函数设计
奖励函数R(s,a)是引导学习过程的关键,它根据当前状态s和采取的动作a给出即时反馈。在弧线行驶任务中,奖励设计需鼓励小车保持在目标轨迹上,同时考虑行驶的稳定性、速度和效率。例如,当小车位于轨迹上且行驶方向正确时给予正奖励;偏离轨迹或行驶不稳定时给予负奖励;成功完成一圈行驶给予大量正奖励。
2.5 Q-learning算法
Q-learning通过更新Q表来学习在给定状态下采取每个动作的价值,即Q(s,a)表示在状态s下采取动作a后预期累积奖励的估计值。更新规则遵循贝尔曼方程,结合ε-greedy策略(在探索和利用之间平衡)进行决策:

基于Q-learning的小车弧线轨迹行驶控制,通过不断试错学习,逐步优化行驶策略,最终实现自主、稳定地沿预定轨迹行驶。此过程涉及状态空间的合理定义、动作的精心设计、奖励函数的巧妙构造以及Q-table的有效更新,每一环节都对学习效果有着重要影响。
3.MATLAB核心程序
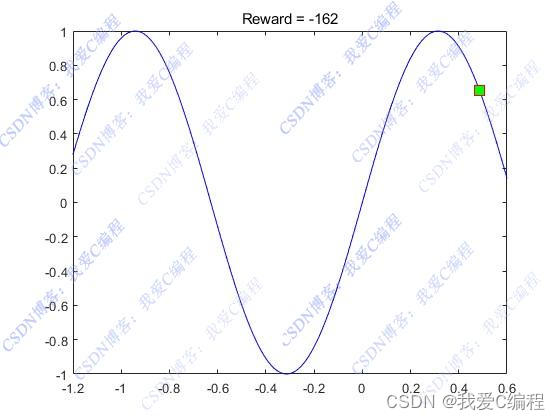
figure;
for i = 1:length(ysim.Reward.Time)
cla;
plot(Xpos,Ypos,'b');
hold on
x = States(1,1,i);
y = sin(5*x);
plot(x,y,'sq','MarkerSize',10,'MarkerEdgeColor','red','MarkerFaceColor',[0 1 0]);
title(['Reward = ' num2str(crwd(i))])
pause(0.025)
end
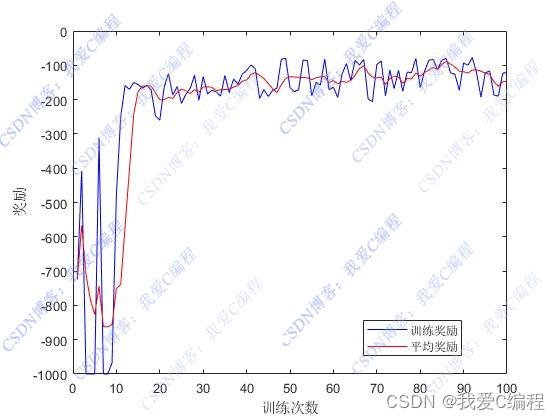
% 绘制结果
figure;
plot(Tnets.EpisodeIndex,Tnets.EpisodeReward,'b');
hold on;
plot(Tnets.EpisodeIndex,Tnets.AverageReward,'r');
xlabel('训练次数');
ylabel('奖励');
legend('训练奖励','平均奖励');
0Z_005m

 浙公网安备 33010602011771号
浙公网安备 33010602011771号