m基于Qlearning强化学习工具箱的网格地图路径规划和避障matlab仿真
1.算法仿真效果
matlab2022a仿真结果如下:
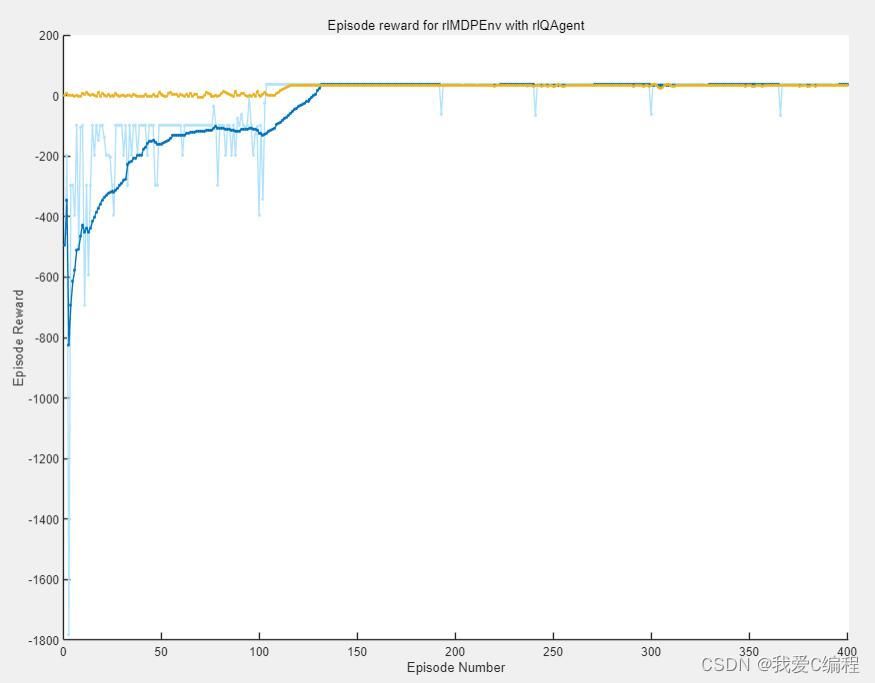
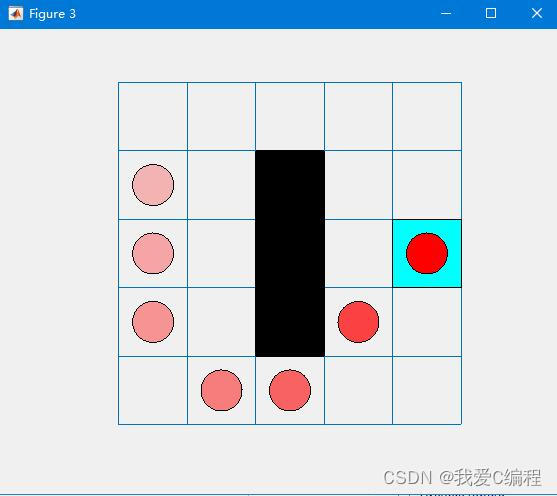
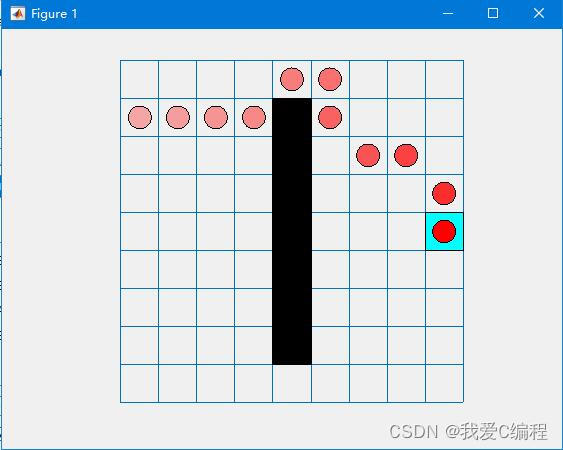
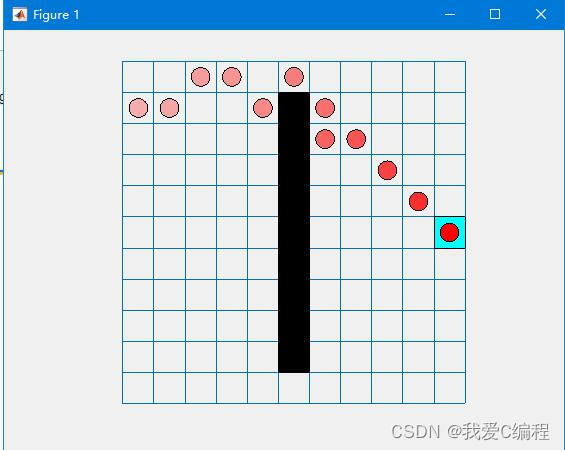
2.算法涉及理论知识概要
Q-Learning是强化学习中的一种重要算法,它属于无模型(model-free)学习方法,能够使智能体在未知环境中学习最优策略,无需环境的具体模型。将Q-Learning应用于路线规划和避障策略中,智能体(如机器人)能够在动态变化的环境中,自主地探索并找到从起点到终点的最安全路径,同时避开障碍物。
Q-Learning的核心在于学习一个动作价值函数Q(s,a),该函数表示在状态s下采取动作a后,预期获得的累积奖励。智能体的目标是最大化长期奖励,通过不断更新Q值,最终学会在任何状态下采取最佳行动的策略。

在路线规划和避障问题中,状态s可以定义为智能体的位置坐标或环境的特征描述,动作a则可以是移动的方向(上、下、左、右等)。环境中的障碍物会给予负奖励,促使智能体避开;而接近目标位置的动作则给予正奖励,鼓励智能体向目标前进。
状态空间: 假设环境为一个二维网格,每个格子可以视为一个状态。若网格大小为N×M,则状态空间的大小为N×M。若考虑更精细的状态描述(如距离障碍物的距离),状态空间会相应增大。
动作空间: 常见的动作集包括上下左右四个基本方向,动作空间大小为4。在更复杂的场景中,可以加入斜向移动,使动作空间扩大到8。
为了在Q-Learning中融入避障策略,可以通过调整奖励机制实现。具体而言:
正奖励: 当智能体朝向目标移动时给予正奖励,距离目标越近,奖励越大。
负奖励: 智能体撞上障碍物或进入无法通行区域时给予负奖励,惩罚力度应足够大以确保智能体学会避免这些状态。
探索奖励: 可以引入探索奖励鼓励智能体探索未知区域,但要平衡探索与利用(Exploitation vs. Exploration)。
基于Q-Learning的路线规划和避障策略,通过不断迭代学习,智能体能够在复杂多变的环境中自主发现安全高效的路径。该方法不仅适用于静态环境,也能通过调整策略适应动态变化的场景,展现了强化学习在自主导航领域的广泛应用前景。
3.MATLAB核心程序
%创建Q学习智能体 % 首先,根据环境的观察和动作规范创建Q表 Qtab = rlTable(getObservationInfo(Envir),getActionInfo(Envir)); % 创建表型表示并设置学习率为0.5 Reptab = rlRepresentation(Qtab); Reptab.Options.LearnRate = 0.5; % 接着,使用此表型表示创建Q学习智能体,并配置epsilon贪心策略 agentOpts = rlQAgentOptions; agentOpts.EpsilonGreedyExploration.Epsilon = 0.04; qAgent = rlQAgent(Reptab,agentOpts); %训练Q学习智能体 trainOpts = rlTrainingOptions; trainOpts.MaxStepsPerEpisode = 100;% 每个episode最大步数 trainOpts.MaxEpisodes = 400;% 总训练episode数 trainOpts.StopTrainingCriteria = "AverageReward";% 停止训练的条件 trainOpts.StopTrainingValue = 40;% 达到的平均奖励阈值 trainOpts.ScoreAveragingWindowLength = 30;% 平均奖励的窗口长度 % 开始训练智能体 trainingStats = train(qAgent,Envir,trainOpts);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号