m基于Yolov2深度学习网络的人体喝水行为视频检测系统matlab仿真,带GUI界面
1.算法仿真效果
matlab2022a仿真结果如下:
输入测试avi格式视频

结果如下:
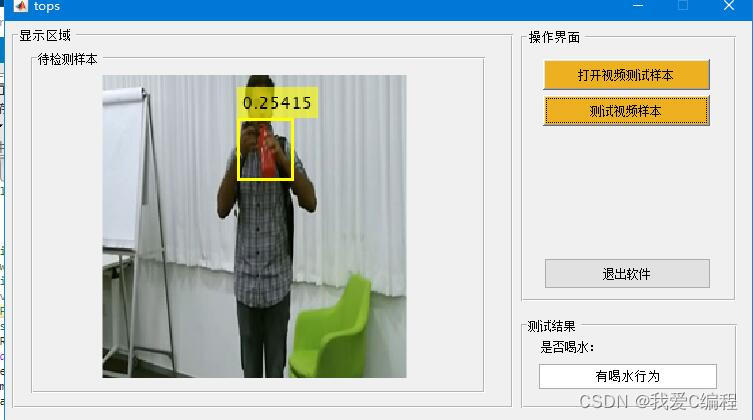
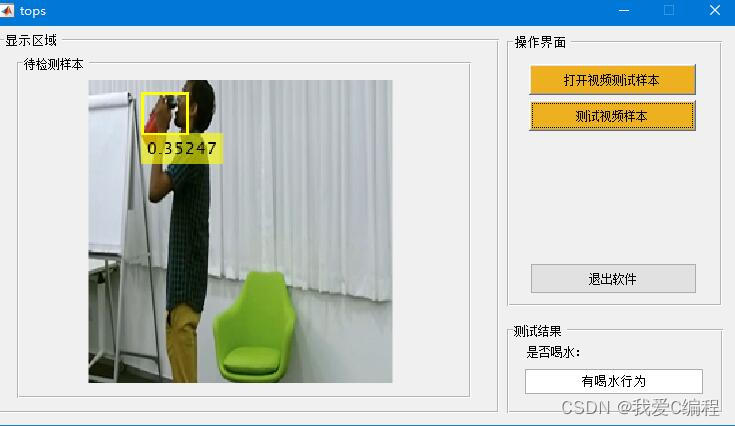
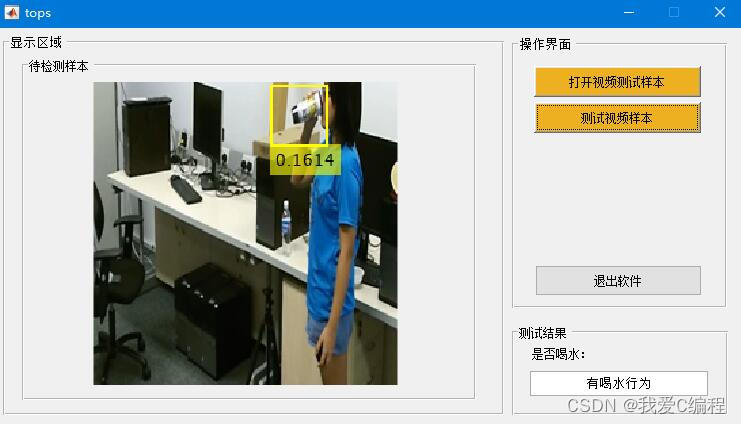
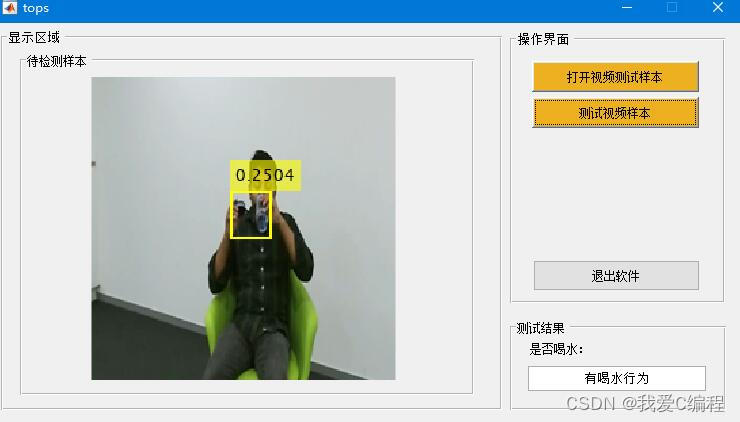
2.算法涉及理论知识概要
构建基于YOLOv2深度学习网络的人体喝水行为视频检测系统涉及多个关键技术环节,包括目标检测模型架构设计、特征提取、锚框机制、边界框预测及损失函数优化等。YOLOv2(You Only Look Once v2)是由Joseph Redmon和Ali Farhadi等人提出的实时目标检测框架,它具有高效、快速的特点,并且适用于人体喝水行为这类特定场景下的行为识别。
YOLOv2采用全卷积神经网络(Fully Convolutional Neural Network, FCN)结构,整个过程包含特征提取、空间维度还原和预测输出三个阶段。YOLOv2的损失函数结合了分类误差和定位误差:

针对人体喝水行为视频检测系统,首先会对YOLOv2模型进行定制化训练,使其能有效区分喝水行为与其他行为。这通常需要构建包含大量标注有人体喝水动作的视频帧数据集,模型通过学习这些样本,逐渐学会从复杂的背景和人体姿态中抽取出喝水这一特定行为的关键特征。
3.MATLAB核心程序
sidx = randperm(size(FACES,1));% 打乱数据集索引
idx = floor(0.75 * length(sidx));% 将75%的数据用作训练集
train_data = FACES(sidx(1:idx),:);% 选取训练集
test_data = FACES(sidx(idx+1:end),:);% 选取测试集
% 图像大小
image_size = [224 224 3];
num_classes = size(FACES,2)-1;% 目标类别数量
anchor_boxes = [% 预定义的锚框大小
43 59
18 22
23 29
84 109
];
% 加载预训练的 ResNet-50 模型
load mat\Resnet50.mat
% 用于目标检测的特征层
featureLayer = 'activation_40_relu';
% 构建 YOLOv2 网络
lgraph = yolov2Layers(image_size,num_classes,anchor_boxes,Initial_nn,featureLayer);
options = trainingOptions('sgdm', ...
'MiniBatchSize', 8, ....
'InitialLearnRate',1e-4, ...
'MaxEpochs',200,...
'CheckpointPath', Folder, ...
'Shuffle','every-epoch', ...
'ExecutionEnvironment', 'gpu');% 设置训练选项
% 训练 YOLOv2 目标检测器
[detector,info] = trainYOLOv2ObjectDetector(train_data,lgraph,options);
save model.mat detector

 浙公网安备 33010602011771号
浙公网安备 33010602011771号