基于FastICA算法的混合信号解混合信号恢复仿真
1.算法描述
独立成分分析(Independent Component Analysis,ICA)是近年来提出的非常有效的数据分析工具,它主要用来从混合数据中提取出原始的独立信号。它作为信号分离的一种有效方法而受到广泛的关注。近几年出现了一种快速ICA算法(Fast ICA),该算法是基于定点递推算法得到的,它对任何类型的数据都适用,同时它的存在对运用ICA分析高维的数据成为可能。又称固定点(Fixed-Point)算法,是由芬兰赫尔辛基大学Hyvärinen等人提出来的。是一种快速寻优迭代算法,与普通的神经网络算法不同的是这种算法采用了批处理的方式,即在每一步迭代中有大量的样本数据参与运算。但是从分布式并行处理的观点看该算法仍可称之为是一种神经网络算法。FastICA算法有基于四阶累积量、基于似然最大、基于负熵最大等形式。此外,该算法采用了定点迭代的优化算法,使得收敛更加快速、稳健。
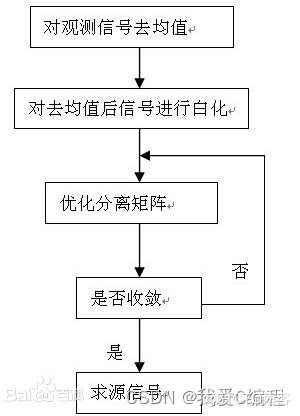
1)对观测信号去均值是ICA算法最基本和最必须的预处理步骤,其处理过程是从观测中减去信号的均值向量,使得观测信号成为零均值变量。该预处理只是为了简化 ICA算法,并不意味着均值不能估计出来。
2)一般情况下所获得的数据都具有相关性,通常都要求对数据进行初步的白化或球化处理,因为白化处理可去除各观测信号之间的相关性,从而简化后续独立分量的提取过程。通常情况下,数据进行白化处理与不对数据进行白化处理相比,算法的收敛性较好,有更好的稳定性。
3)对多个独立分量的估计,需要将最大非高斯性的方法加以扩展。对应于不同独立分量的向量在白化空间中应是正交的,算法第6步用压缩正交化保证分离出来的是不同的信号,但是该方法的缺点是第1个向量的估计误差会累计到随后向量的估计上。
简单地说快速ICA算法通过三步完成:首先,对观测信号去均值;然后,对去均值后的观测信号白化处理;前两步可以看成是对观测信号的预处理,通过去均值和白化可以简化ICA算法。最后,独立分量提取算法及实现流程见流程图。
FastICA算法,又称不动点(Fixed-Point)算法,是由芬兰赫尔辛基大学Hyvärinen等人提出来的。是一种快速寻优迭代算法,与普通的神经网络算法不同的是这种算法采用了批处理的方式,即在每一步迭代中有大量的样本数据参与运算。但是从分布式并行处理的观点看该算法仍可称之为是一种神经网络算法。
FastICA算法有基于峭度、基于似然最大、基于负熵最大等形式,这里,我们介绍基于负熵最大的FastICA算法(可以有效地把不动点迭代所带来的优良算法特性与负熵所带来的更好统计特性结合起来)。它以负熵最大作为一个搜寻方向,可以实现顺序地提取独立源,充分体现了投影追踪(Projection Pursuit)这种传统线性变换的思想。此外,该算法采用了定点迭代的优化算法,使得收敛更加快速、稳健。
因为FastICA算法以负熵最大作为一个搜寻方向,因此先讨论一下负熵判决准则。由信息论理论可知:在所有等方差的随机变量中,高斯变量的熵最大,因而我们可以利用熵来度量非高斯性,常用熵的修正形式,即负熵。根据中心极限定理,若一随机变量由许多相互独立的随机变量之和组成,只要具有有限的均值和方差,则不论其为何种分布,随机变量较更接近高斯分布。换言之,较的非高斯性更强。因此,在分离过程中,可通过对分离结果的非高斯性度量来表示分离结果间的相互独立性,当非高斯性度量达到最大时,则表明已完成对各独立分量的分离[1]。
FastICA算法的方法输出向量,在排列顺序的时候可能出现颠倒和输出信号幅度发生变化。这主要是由于ICA的算法存在2个内在的不确定性导致的:
1)输出向量排列顺序的不确定性,即无法确定所提取的信号对应原始信号源的哪一个分量;
2)输出信号幅度的不确定性,即无法恢复到信号源的真实幅度。
但由于主要信息都包含在输出信号中,这2种不确定性并不影响其应用。

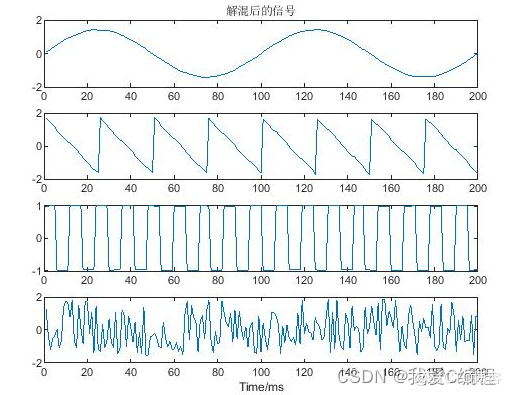
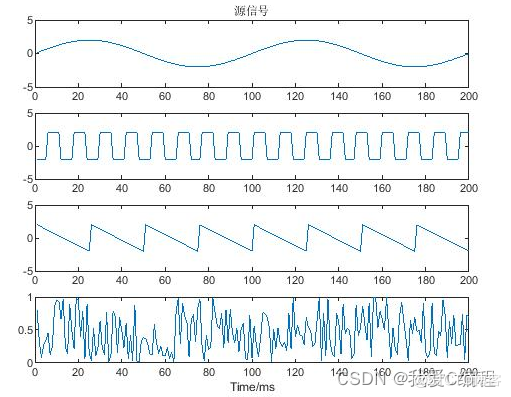
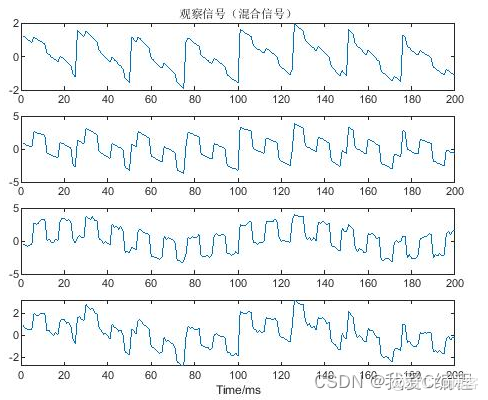
2.仿真效果预览
matlab2022a仿真结果如下:
3.MATLAB核心程序
average= mean(X')'; %均值
for i=1:M
X(i,:)=X(i,:)-average(i)*ones(1,T);
end
%---------白化/球化------
Cx = cov(X',1); %计算协方差矩阵Cx
[eigvector,eigvalue] = eig(Cx); %计算Cx的特征值和特征向量
W=eigvalue^(-1/2)*eigvector'; %白化矩阵
Z=W*X; %正交矩阵
%----------迭代-------
Maxcount=10000; %最大迭代次数
Critical=0.00001; %判断是否收敛
m=M; %需要估计的分量的个数
W=rand(m);
for n=1:m
WP=W(:,n); %初始权矢量(任意)
count=0;
LastWP=zeros(m,1);
W(:,n)=W(:,n)/norm(W(:,n));
while abs(WP-LastWP)&abs(WP+LastWP)>Critical
count=count+1; %迭代次数
LastWP=WP; %上次迭代的值
% WP=1/T*Z*((LastWP'*Z).^3)'-3*LastWP;
for i=1:m
WP(i)=mean(Z(i,:).*(tanh((LastWP)'*Z)))-(mean(1-(tanh((LastWP))'*Z).^2)).*LastWP(i);
end
WPP=zeros(m,1);
for j=1:n-1
WPP=WPP+(WP'*W(:,j))*W(:,j);
end
WP=WP-WPP;
WP=WP/(norm(WP));
if count==Maxcount
fprintf('未找到相应的信号');
return;
end
end
W(:,n)=WP;
end
Z=W'*Z;
end

 浙公网安备 33010602011771号
浙公网安备 33010602011771号