基于贝叶斯判决的手写数字识别系统,带GUI界面
1.算法描述
贝叶斯判别规则是把某特征矢量(x) 落入某类集群的条件概率当成分类判别函数(概率判别函数),x落入某集群的条件概率最大的类为X的类别,这种判决规则就是贝叶斯判别规则。贝叶斯判别规则是以错分概率或风险最小为准则的判别规则。
判别函数,各个类别的判别区域确定后,可以用一些函数来表示和鉴别某个特征矢量属于哪个类别,这些函数就称为判别函数。这些函数不是集群在特征空间形状的数学描述,而是描述某一位置矢量属于某个类别的情况,如属于某个类别的条件概率,一般不同的类别都有各自不同的判别函数。
贝叶斯分类,是机器学习中比较重要并被广泛使用的一个分类算法,它分类思想主要基于贝叶斯定理。用一句话来描述就是,如果一个事件A发生时,总是伴随事件B,那么事件B发生时,事件A发生的概率也会很大。
贝叶斯分类一个很常见的用途是用在识别垃圾邮件上。我们给定一个学习集,程序通过学习集发现,在垃圾邮件中经常出现“免费赚钱”这个词,同时“免费赚钱”这个词又在垃圾邮件中更容易出现。那么在实际判断中,我们发现邮件中出现“免费赚钱”,就可以判定邮件是垃圾邮件。
其实我们每个人,我们的大脑每天都会执行分类操作,而且思考的过程和贝叶斯分类很像。我们可以想象一下,我们自己是如何识别垃圾邮件的。我们识别垃圾邮件总会有一定的规则,比如邮件中含有XX关键词,邮件描述信息太离谱了,邮件的发送人不认识,邮件中包含钓鱼网站。而这些规则,我们都是通过以往的经验总结出来的。通过这些规则,我们就可以判定邮件是垃圾邮件的概率更大,还是非垃圾邮件的概率更大。
首先我们要知道,P(A),P(B)分别是事件A,B发生的概率,而P(A|B)是在事件A在事件B发生的前提下发生的概率,P(AB)是事件A,B同时发生的概率。那么我们的有公式:
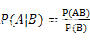
那么贝叶斯定理是:
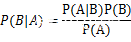
注:P(AB)=P(A)P(B)的充分必要条件是事件A和事件B相互独立。用通俗的语言讲就是,事件A是否发生不会影响到事件B发生的概率。
2.仿真效果预览
matlab2022a仿真结果如下:

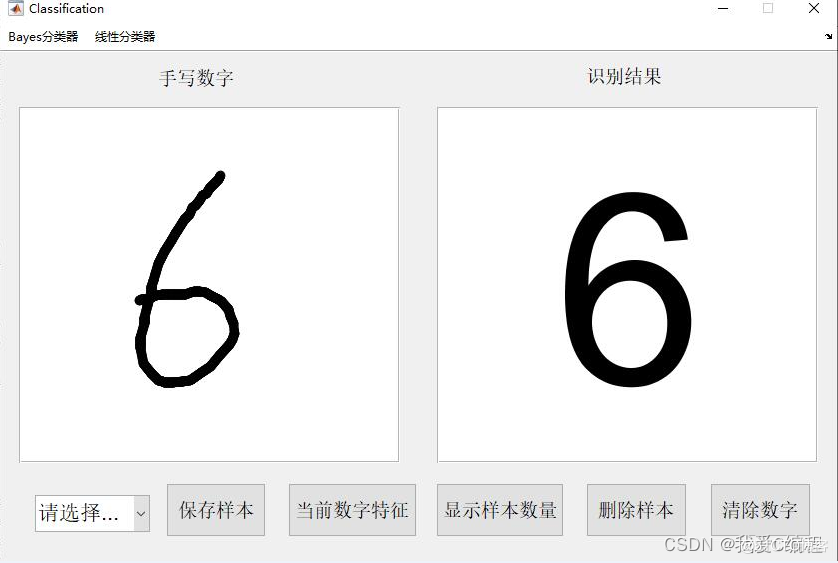
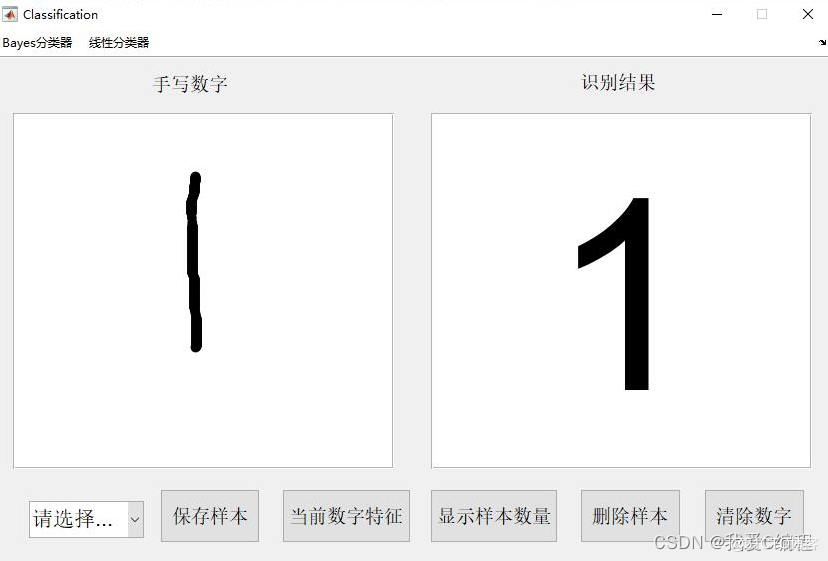
3.MATLAB核心程序
function y=BayesLeastRisk(data)
clc;
load template pattern;
%将数字特征转化为0、1两个数值表示
for i=1:10
for j=1:25
for k=1:pattern(1,i).num
if pattern(1,i).feature(j,k)>0.1
pattern(1,i).feature(j,k)=1;
else
pattern(1,i).feature(j,k)=0;
end
end
end
end
[pc_template,pc_data]=pcapro(data); %主成分分析
temp=0;
for i=1:10
pattern(1,i).feature=pc_template(:,temp+1:temp+pattern(1,i).num);
temp=temp+pattern(1,i).num;
end
%求协方差矩阵、协方差矩阵的逆矩阵、协方差矩阵的行列式
s_cov=[];
s_inv=[];
s_det=[];
for i=1:10
s_cov(i).data=cov(pattern(1,i).feature');
s_inv(i).data=inv(s_cov(i).data);
s_det(i)=det(s_cov(i).data);
end
%求先验概率
sum=0;
pw=[]; %P(wi)---先验概率
for i=1:10
sum=sum+pattern(1,i).num;
end
for i=1:10
pw(i)=pattern(1,i).num/sum;
end
%求判别函数
h=[]; %h()---差别函数
mean_data=[]; %mean_data---每类样品特征向量的均值
for i=1:10
mean_data(i).data=mean(pattern(1,i).feature')';
end
%判别函数
for i=1:10
h(i)=(pc_data-mean_data(i).data)'*s_inv(i).data*(pc_data-mean_data(i).data)...
*(-0.5)+log(pw(i))+log(abs(s_det(i)))*(-0.5);
end
%求每一类的损失
%---------loss为损失矩阵,大小为10x10---------------------------------------
loss=ones(10)-diag(diag(ones(10))); %diag(ones(10))---取对角线元素,diag(diag(ones(10)))---构建以上面取得的对角线元素为新矩阵的对角线元素,其余元素为0的新的对角线元素。
risk=0;
m=[];
for i=1:10
m=loss(i,:); %根据每一类损失的公式,第i类的损失等损失矩阵的第i行与判别函数的列向量相乘
risk(i)=m*h';
end
[minval minpos]=min(risk);
y=minpos-1;
end

 浙公网安备 33010602011771号
浙公网安备 33010602011771号