m基于果蝇优化的K-means数据聚类分析matlab仿真
1.算法描述
果蝇优化算法FOA(Fruit Fly Optimization Algorithm)是由台湾博士潘文超于2011年提出的,与蚁群算法和粒子群算法类似,是基于动物群体觅食行为演化出的一种寻求全局优化的新方法[1-3]。它不同于顺序执行的传统智能算法,而是以果蝇群体自组织性和并行性为基础,构造出的一种动物自治体模型。FOA有着算法简单、控制参数少、容易实现、且具有一定并行性等特点,因此在各领域得到广泛应用[4]。FOA可以优化神经网络参数,已成功应用于企业经营绩效评估、外贸出口预测、原油含水率预测等[3,5-6];FOA也可优化支持向量机模型,已成功应用于故障诊断、物流需求量预测等[7-8]。但由于FOA是较晚提出的一种随机搜索算法,其在理论分析和应用研究等方面还处于初级阶段,同时也存在易发散、收敛精度不高等缺点。
果蝇优化算法(FOA)通过模拟果蝇利用敏锐的嗅觉和视觉进行捕食的过程,FOA实现对解空间的群体迭代搜索。FOA原理易懂、操作简单、易于实现,具有较强的局部搜索能力。FOA在计算方法上类似于遗传算法,但不同的是FOA不使用杂交和变异等算子,而是通过模仿果蝇特殊的嗅觉和视觉特点来进行搜索。果蝇的嗅觉器官能很好地搜集飘浮在空气中的各种气味,甚至能嗅到几十公里以外的食物源。然后飞近食物位置,使用敏锐的视觉发现食物与同伴聚集的位置,并且往该方向飞去,蝇优化算法分为以下几个步骤。
(1) 初始化果蝇群体

(2) 给出果蝇个体利用嗅觉搜寻食物的方向与距离:
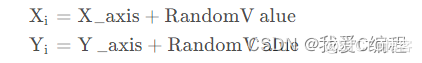
(3)计算果蝇个体与原点之间的距离和味道浓度判定值
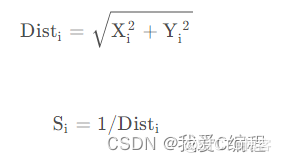
(4)求出该果蝇个体位置的味道浓度

(5) 找出此果蝇群体中味道浓度最高的果蝇
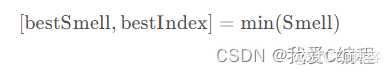
(6) 保留最佳味道浓度值与坐标,此时果蝇群体利用视觉往该位置飞去。
(7) 进入迭代优,重复执行步骤(2) ~ 步骤(5),并判断味道浓度是否优于前一迭代味道浓度,若是则执行步骤(6)。
K-means聚类算法全局搜索能力较低并且选择初始质心的具有盲目性,果蝇算法具有优越的全局搜素能力但寻优方向不稳定,因此对果蝇算法(FOA)进行改进并以此优化K-means.在模型基础上利用密度标准差选择初始果蝇个体,并且构建寻优目标精度高的适应度函数进性寻优
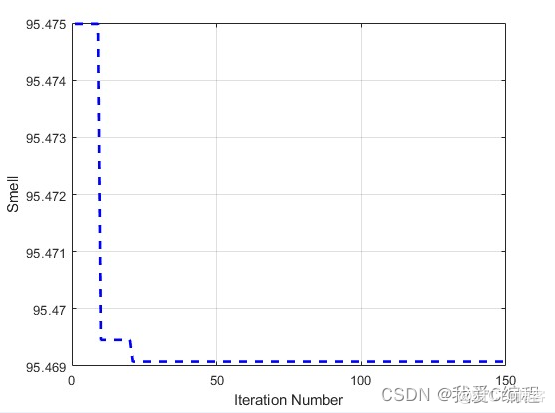
2.仿真效果预览
matlab2022a仿真结果如下:


3.MATLAB核心程序
for j1=1:Iter
%每类中心的距离
Dist=zeros(n,k);
for p1=1:n
for p2=1:k
for p3=1:m
Dist(p1,p2) = Dist(p1,p2) + abs(x(p3,p1)-Matrix(p3,p2));
end
end
end
%下面计算每个向量到每类中心距离的最小值
s = zeros(1,n);
for p1=1:n
pp = find(Dist(p1,:)==min(Dist(p1,:)));
s(1,p1) = pp(1,1);
end
%以下计算每一类的向量
Class=[];
for p1=1:k
Class=[];
%以下根据将各类分别标出
for p2=1:n
if s(p2)==p1
Class=[Class x(:,p2)];
end
end
%根据将各类分别标出结束
%以下重新计算每类的中心
if length(Class)==0
for g=1:m
Matrix(g,p1)=0;
end
else
for g=1:m
Matrix(g,p1) = mean(Class(g,:));
end
end
%重新计算每类的中心结束
if j1 == Iter
Cxy{p1} = Class;
end
end
%计算每一类的向量结束
Err2(j1) = mean2(Dist);
end
Err = Err2(end);
X1=100*rand(1,100)+20;
Y1=100*rand(1,100)+20;
X2=100*rand(1,100)+100;
Y2=100*rand(1,100)+100;
X_axis = [X1,X2];
Y_axis = [Y1,Y2];
Data = [X_axis;Y_axis];
Cluster= 2;
Iters = 1;
figure(1);
plot(X_axis,Y_axis,'r*');
%初始化kmeans聚类
[Cxy1,Err1] = kmean(Data,Cluster,Iters);
%%
%初始果蝇群体位置
X_ini = 100*rand(1,2);
Y_ini = 100*rand(1,2);
%迭代次数
MIter = 150;
%种群规模
Pops = 10;
%果蝇寻优开始
%利用嗅觉寻找食物
for i=1:Pops
%果蝇个体飞行距离
X(i,:) = X_ini + 200*rand()-100;
Y(i,:) = Y_ini + 200*rand()-100;
%与原点之距离
D(i,1) =(X(i,1)^2+Y(i,1)^2)^0.5;
D(i,2) =(X(i,2)^2+Y(i,2)^2)^0.5;
%味道浓度为距离之倒数,先求出味道浓度判定值
S(i,1) = 1/D(i,1);
S(i,2) = 1/D(i,2);
%利用味道浓度判定函数求出味道浓度
[Cxy,Err]= kmean_opt(Data,Cluster,Iters,[S(i,1);S(i,2)]);
Smell(i) = Err;
end
%寻找初始极值
[bestSmell,bestindex]=min(Smell);
%利用视觉寻找伙伴聚集味道浓度最高之处
X_ini = X(bestindex);
Y_ini = Y(bestindex);
Smellbest = bestSmell;
%果蝇迭代
for g=1:MIter
g
for i=1:Pops
%由上一代最佳位置处增加果蝇个体飞行距离
X(i,:) = X_ini + 200*rand() - 100;
Y(i,:) = Y_ini + 200*rand() - 100;
%与原点距离
%与原点之距离
D(i,1) =(X(i,1)^2+Y(i,1)^2)^0.5;
D(i,2) =(X(i,2)^2+Y(i,2)^2)^0.5;
%味道浓度为距离之倒数,先求出味道浓度判定值
S(i,1) = 1/D(i,1);
S(i,2) = 1/D(i,2);
[Cxy,Err]= kmean_opt(Data,Cluster,Iters,[S(i,1);S(i,2)]);
Smell(i) = Err;
end
end

 浙公网安备 33010602011771号
浙公网安备 33010602011771号