m基于隐马尔科夫模型(HMM)的手机用户行为预测(MMUB)算法matlab仿真
1.算法描述
隐马尔可夫模型(Hidden Markov Model,HMM)是一种统计模型,广泛应用在语音识别,词性自动标注,音字转换,概率文法等各个自然语言处理等应用领域。经过长期发展,尤其是在语音识别中的成功应用,使它成为一种通用的统计工具。
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,例如模式识别。是在被建模的系统被认为是一个马尔可夫过程与未观测到的(隐藏的)的状态的统计马尔可夫模型。隐马尔可夫模型是马尔可夫链的一种,它的状态不能直接观察到,但能通过观测向量序列观察到,每个观测向量都是通过某些概率密度分布表现为各种状态,每一个观测向量是由一个具有相应概率密度分布的状态序列产生。所以,隐马尔可夫模型是一个双重随机过程----具有一定状态数的隐马尔可夫链和显示随机函数集。自20世纪80年代以来,HMM被应用于语音识别,取得重大成功。到了90年代,HMM还被引入计算机文字识别和移动通信核心技术“多用户的检测”。HMM在生物信息科学、故障诊断等领域也开始得到应用。
一种HMM可以呈现为最简单的动态贝叶斯网络。隐马尔可夫模型背后的数学是由LEBaum和他的同事开发的。它与早期由RuslanL.Stratonovich提出的最优非线性滤波问题息息相关,他是第一个提出前后过程这个概念的。
在简单的马尔可夫模型(如马尔可夫链),所述状态是直接可见的观察者,因此状态转移概率是唯一的参数。在隐马尔可夫模型中,状态是不直接可见的,但输出依赖于该状态下,是可见的。每个状态通过可能的输出记号有了可能的概率分布。因此,通过一个HMM产生标记序列提供了有关状态的一些序列的信息。注意,“隐藏”指的是,该模型经其传递的状态序列,而不是模型的参数;即使这些参数是精确已知的,我们仍把该模型称为一个“隐藏”的马尔可夫模型。隐马尔可夫模型以它在时间上的模式识别所知,如语音,手写,手势识别,词类的标记,乐谱,局部放电和生物信息学应用。
隐马尔可夫模型可以被认为是一个概括的混合模型中的隐藏变量(或变量),它控制的混合成分被选择为每个观察,通过马尔可夫过程而不是相互独立相关。最近,隐马尔可夫模型已推广到两两马尔可夫模型和三重态马尔可夫模型,允许更复杂的数据结构的考虑和非平稳数据建模。
基于隐马尔科夫模型(HMM)的手机用户行为预测(MMUB)算法结构如下图所示:
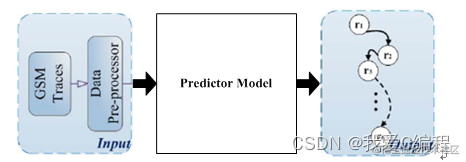
这里,我们采用的数据格式如下:
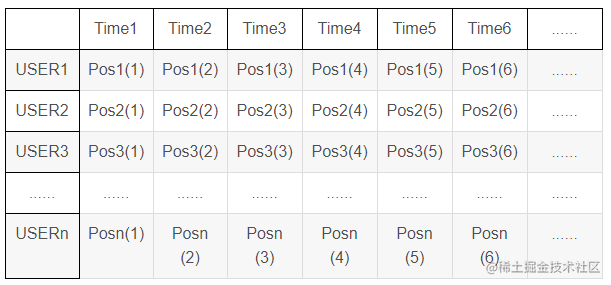
即通过采集多个用户在不同时刻的位置,通过算法,来预测后面的位置。即,我们所使用的模型的输入数据类型应该为如下的格式:
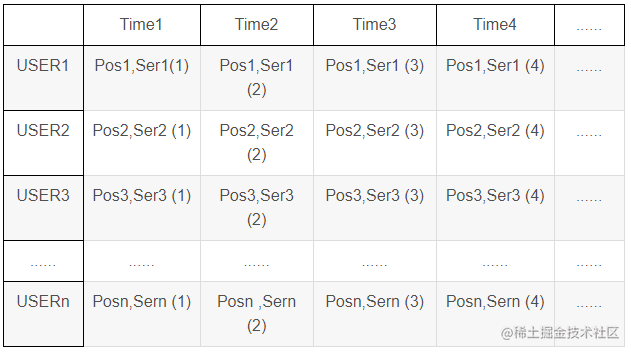
模型的输入,即类同如上格式的数据类型。
2.仿真效果预览
matlab2022a仿真结果如下:
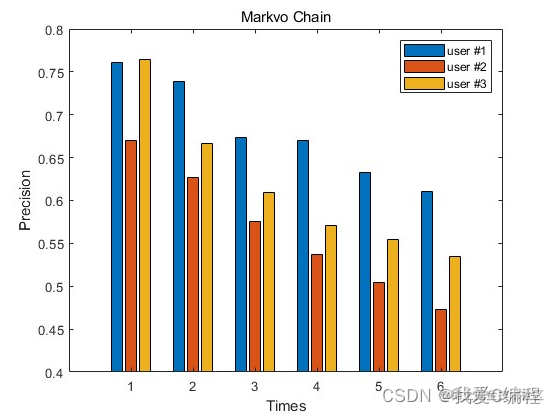
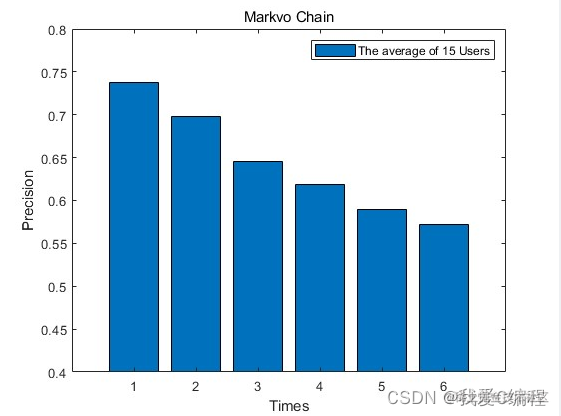
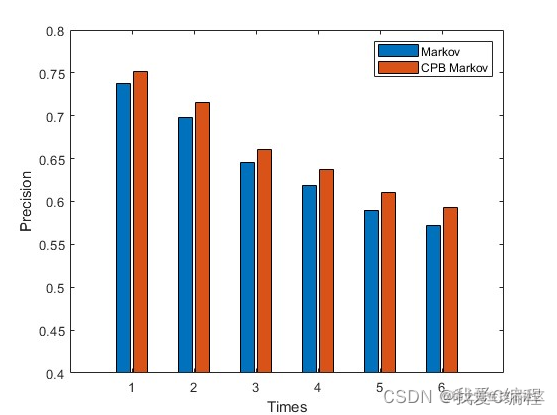
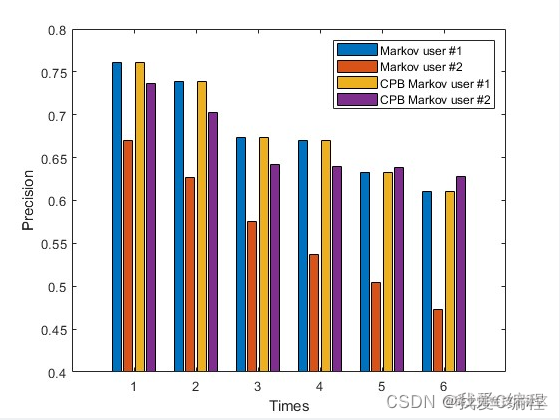
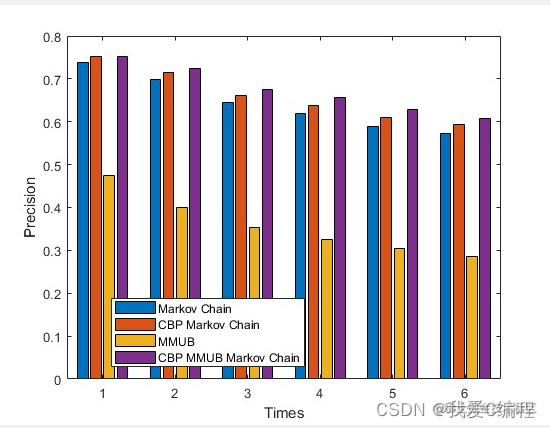
从仿真结果可知,单独的MMUB+HMM的预测方法,精度并不理想。但是MMUB具有其优势,就是用户行为模型的构建,从而有效的估计每个用户的可能发生的行为。
3.MATLAB核心程序
N1 = 100;%为了防止出现连续状态不变得情况,这里N1设置大点
N2 = 6;
N = N1 + N2; %前N1个用于训练,后N2个用于预测
Times = 1000;
%通过多次循环,计算正确率
for Nu = 1:length(Locaiton_id3)
UNo = Nu;%用户标号
for tim = 1:Times
UNo
tim
Dat = Locaiton_id3{1,UNo}(1+tim:N+tim);
State = unique(Dat);
%Counting the User Behavior Patterns
%Counting the User Behavior Patterns
Alpha = [];
maps = [];
MAP = [];
[Alpha,maps,MAP] = func_find_alpha_table(Dat,Locaiton_id3,State);
%Modeling the User Behaviors,the user’s behavior model can be built based on the resulting counting tables
%状态转移概率%释放概率
%对应算法步骤中计算STATE的步骤,计算moving or steady??
[seq,states] = func_cal_moving_steady(maps(1:N));%这里需要地址映射为自然数
[TRANS_EST,EMIS_EST] = hmmestimate(seq,states);
[r,c] = size(TRANS_EST);
for p1 = 1:r
for p2 = 1:c
if TRANS_EST(p1,p2) == 0
TRANS_EST(p1,p2) = eps;
end
if TRANS_EST(p1,p2) == 1
TRANS_EST(p1,p2) = 1-eps;
end
end
end

 浙公网安备 33010602011771号
浙公网安备 33010602011771号