B树/[oracle]connect BY语句
读大神的书,出现很多没有见过的函数和便捷操作,特此记录
connect by 之前没有接触过,为了学习这个语句,先了解一下B树数据类型是最好的方法。
【本人摘自以下博客】
https://www.cnblogs.com/George1994/p/7008732.html
https://www.cnblogs.com/mushroom/p/4100087.html
https://www.cnblogs.com/vincently/p/4526560.html
简介
这里的B树,也就是英文中的B-Tree,一个 m 阶的B树满足以下条件:
- 每个结点至多拥有m棵子树;
- 根结点至少拥有两颗子树(存在子树的情况下);
- 除了根结点以外,其余每个分支结点至少拥有 m/2 棵子树;
- 所有的叶结点都在同一层上;
- 有 k 棵子树的分支结点则存在 k-1 个关键码,关键码按照递增次序进行排列;
- 关键字数量需要满足ceil(m/2)-1 <= n <= m-1;
【另一种描述,换种写法,意思一样:
根据这张图介绍下b树的基础定义:
这是颗5阶B树的图,阶简写m。
1:树中每个结点最多含有m个子节点(m>=2)。
2:每个内节点至少 [ceil(m / 2)] 个子节点。 内节点即非根节点非页子节点,也可以叫中间节点。
3: 关键字key的数量 [ceil(m / 2)-1]<= n <= m-1,关键字按递增排序。
6: 每个叶节点具有相同的深度,即树的高度h,而且不包含关键字信息。
上图也可称为最小度数为3的b树,(degree) ,简写t。
t其实是上面第二条定义中 [ceil(m / 2)] 的值,即t=[ceil(m/2)], 3=ceil(5/2) 。
1:每个非根节点至少有t-1个关键字,非根内节点至少有t个子节点。 t称为度数(degree),t>=2 。
. 2:每个节点至多有2t-1关键字,每个内节点最多有2t个子节点。
3:每个叶节点具有相同的深度,即树的高度h,而且不包含关键字信息。
度和阶都是描述子节点的数量的。
算法导论译版中是用度来描述的。
数据结构与算法分析是用阶来描述,网上大多也是。
end】
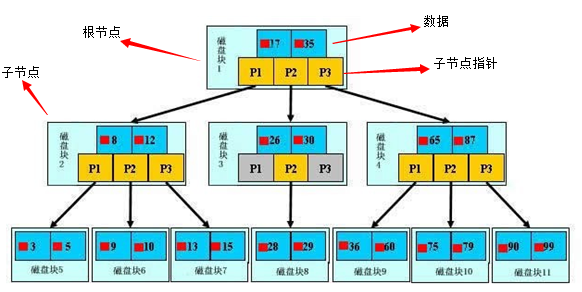
这是B树存储在硬盘的逻辑结构图。
其中根节点中17,35在称为关键字(key) ,实际中往往附带更多复杂类型数据。
可以看出一个节点包含 keys ChildNotePointer 2部分信息。
操作
既然是树,那么必不可少的操作就是插入和删除,这也是B树和其它数据结构不同的地方,当然了,还有必不可少的搜索,分享一个对B树的操作进行可视化的网址,它是由usfca提供的。
插入
新结点一般插在第h层,通过搜索找到对应的结点进行插入,那么根据即将插入的结点的数量又分为下面几种情况。
- 如果该结点的关键字个数没有到达m-1个,那么直接插入即可;
- 如果该结点的关键字个数已经到达了m-1个,那么根据B树的性质显然无法满足,需要将其进行分裂。分裂的规则是该结点分成两半,将中间的关键字进行提升,加入到父亲结点中,但是这又可能存在父亲结点也满员的情况,则不得不向上进行回溯,甚至是要对根结点进行分裂,那么整棵树都加了一层。





删除
同样的,我们需要先通过搜索找到相应的值,存在则进行删除,需要考虑删除以后的情况,
- 如果该结点拥有关键字数量仍然满足B树性质,则不做任何处理;
- 如果该结点在删除关键字以后不满足B树的性质(关键字没有到达ceil(m/2)-1的数量),则需要向兄弟结点借关键字,这有分为兄弟结点的关键字数量是否足够的情况。
- 其余情况参照BST中的删除。



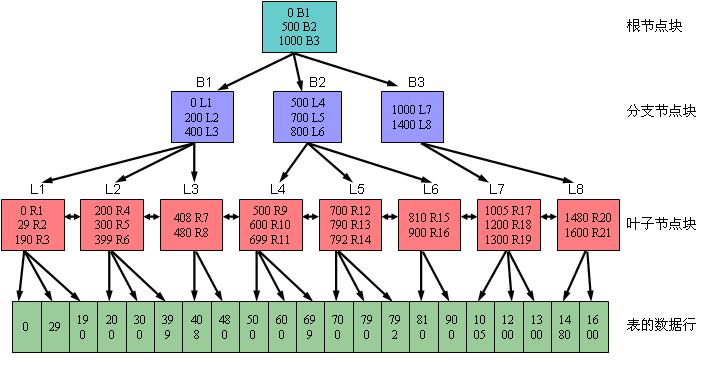
B+树
为什么要B+树
由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引,而B树则常用于文件索引。
简介
- 根结点只有一个,分支数量范围为[2,m];
- 分支结点,每个结点包含分支数范围为[ceil(m/2), m];
- 分支结点的关键字数量等于其子分支的数量减一,关键字的数量范围为[ceil(m/2)-1, m-1],关键字顺序递增;
- 所有叶子结点都在同一层;
操作
其操作和B树的操作是类似的,不过需要注意的是,在增加值的时候,如果存在满员的情况,将选择结点中的值作为新的索引,还有在删除值的时候,索引中的关键字并不会删除,也不会存在父亲结点的关键字下沉的情况,因为那只是索引。
B树和B+树的区别
这都是由于B+树和B具有这不同的存储结构所造成的区别,以一个m阶树为例。
- 关键字的数量不同;B+树中分支结点有m个关键字,其叶子结点也有m个,其关键字只是起到了一个索引的作用,但是B树虽然也有m个子结点,但是其只拥有m-1个关键字。
- 存储的位置不同;B+树中的数据都存储在叶子结点上,也就是其所有叶子结点的数据组合起来就是完整的数据,但是B树的数据存储在每一个结点中,并不仅仅存储在叶子结点上。
- 分支结点的构造不同;B+树的分支结点仅仅存储着关键字信息和儿子的指针(这里的指针指的是磁盘块的偏移量),也就是说内部结点仅仅包含着索引信息。
- 查询不同;B树在找到具体的数值以后,则结束,而B+树则需要通过索引找到叶子结点中的数据才结束,也就是说B+树的搜索过程中走了一条从根结点到叶子结点的路径。
CONNECT BY PRIOR
这个子句主要是用于B树结构类型的数据递归查询,给出B树结构类型中的任意一个结点,遍历其最终父结点或者子结点。
先看原始数据:

1 create table a_test 2 ( parentid varchar2(10), 3 subid varchar2(10)); 4 5 insert into a_test values ( '1', '2' ); 6 insert into a_test values ( '1', '3' ); 7 insert into a_test values ( '2', '4' ); 8 insert into a_test values ( '2', '5' ); 9 insert into a_test values ( '3', '6' ); 10 insert into a_test values ( '3', '7' ); 11 insert into a_test values ( '5', '8' ); 12 insert into a_test values ( '5', '9' ); 13 insert into a_test values ( '7', '10' ); 14 insert into a_test values ( '7', '11' ); 15 insert into a_test values ( '10', '12' ); 16 insert into a_test values ( '10', '13' ); 17 18 commit; 19 20 select * from a_test;
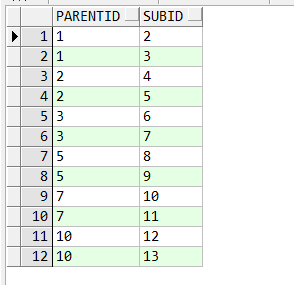
对应B树结构为:

接下来看一个示例:
要求给出其中一个结点值,求其最终父结点。以7为例,看一下代码
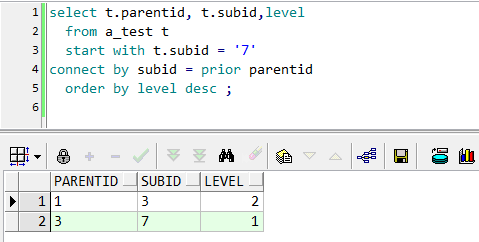
start with 子句:遍历起始条件,有个小技巧,如果要查父结点,这里可以用子结点的列,反之亦然。
connect by 子句:连接条件。关键词prior,prior跟父节点列parentid放在一起,就是往父结点方向遍历;prior跟子结点列subid放在一起,则往叶子结点方向遍历,
parentid、subid两列谁放在“=”前都无所谓,关键是prior跟谁在一起。
order by 子句:排序,不用多说。
--------------------------------------------------
下面看看往叶子结点遍历的例子:
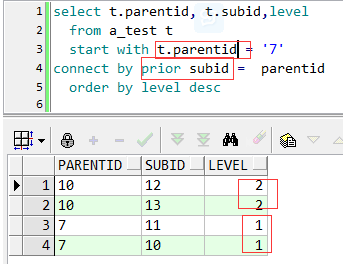
这里start with 子句用了parentid列,具体区别后面举例说明。
connect by 子句中,prior跟subid在同一边,就是往叶子结点方向遍历去了。因为7有两个子结点,所以第一级中有两个结果(10和11),10有两个子结点(12,13),11无,所以第二级也有两个结果(12,13)。即12,13就是叶子结点。
下面看下start with子句中选择不同的列的区别:
以查询叶子结点(往下遍历)为例
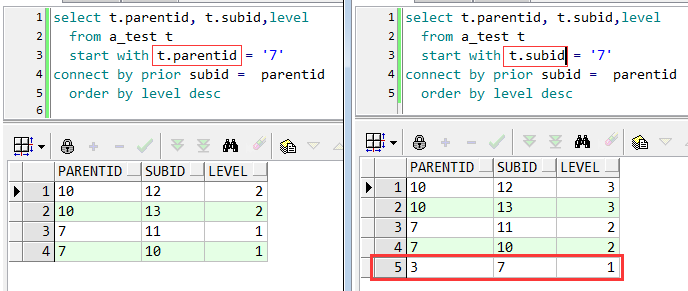
结果很明显,原意是要以7为父结点,遍历其子结点,左图取的是父结点列的值,结果符合原意;右图取的是子结点列的值,结果多余的显示了7 的父结点3.
---------------------------------------
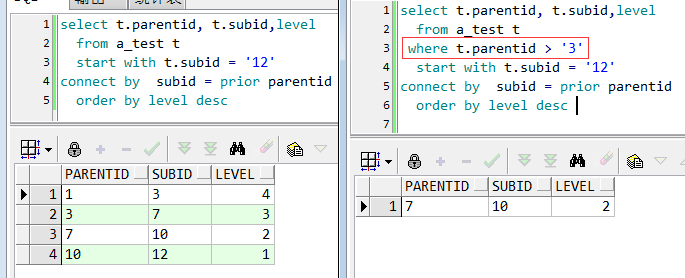
关于where条件的语句,以后验证后再记录。先留个疑问

 浙公网安备 33010602011771号
浙公网安备 33010602011771号