



前言:目标确定

(1)、创建项目
scrapy startproject qsbk
(2)、技术路线
scrapy框架的使用
(3)、创建爬虫
scrapy genspider spider qiushibaike.com (爬虫名不能与项目名重名)
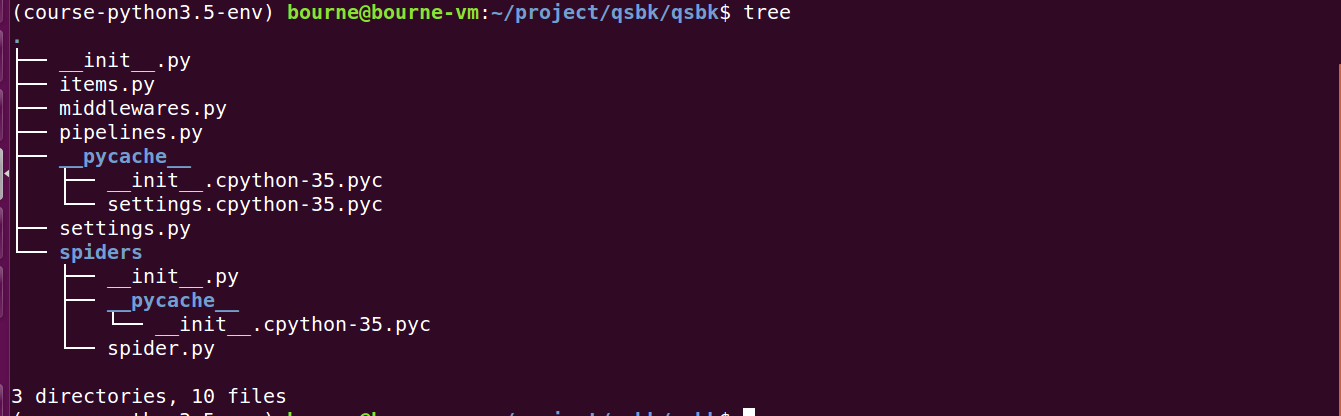
(3)、实战
改写settings.py
设置请求头模拟浏览器访问行为

不遵从robots.txt行为

限定下载速度

启用pipelines,如有多个pipelines,数字小表示优先级越高

改写items.py
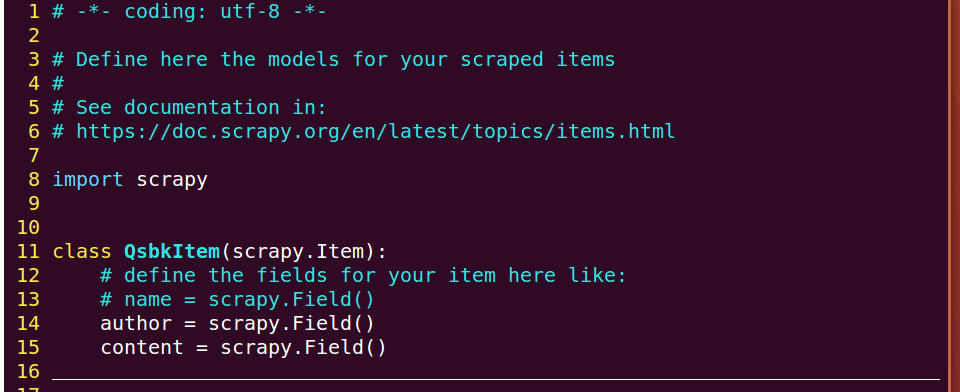
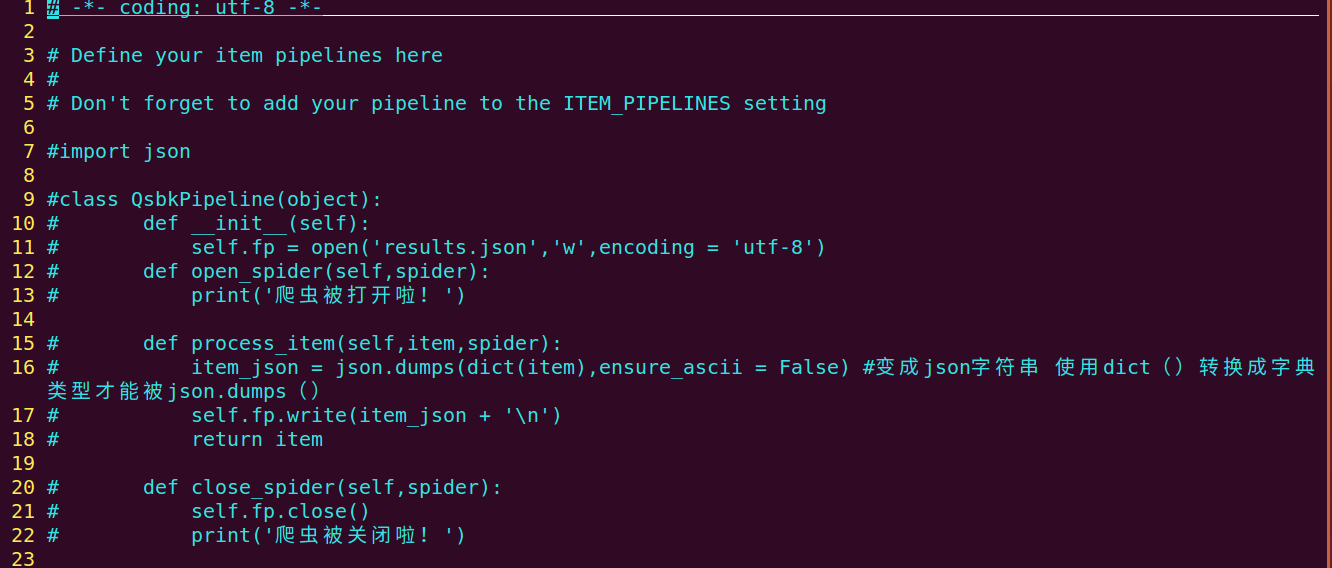
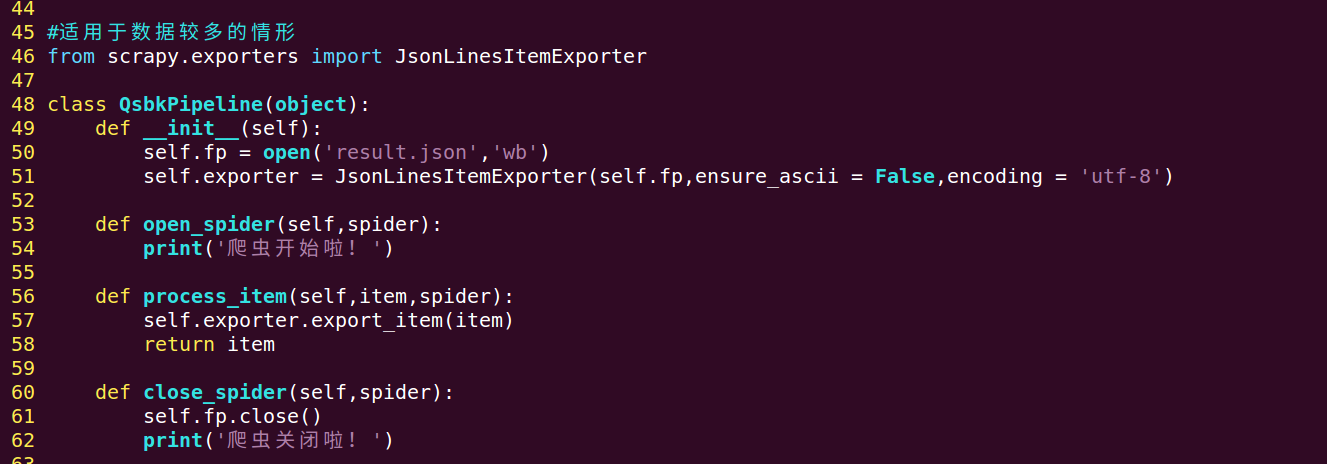
改写pipelines.py
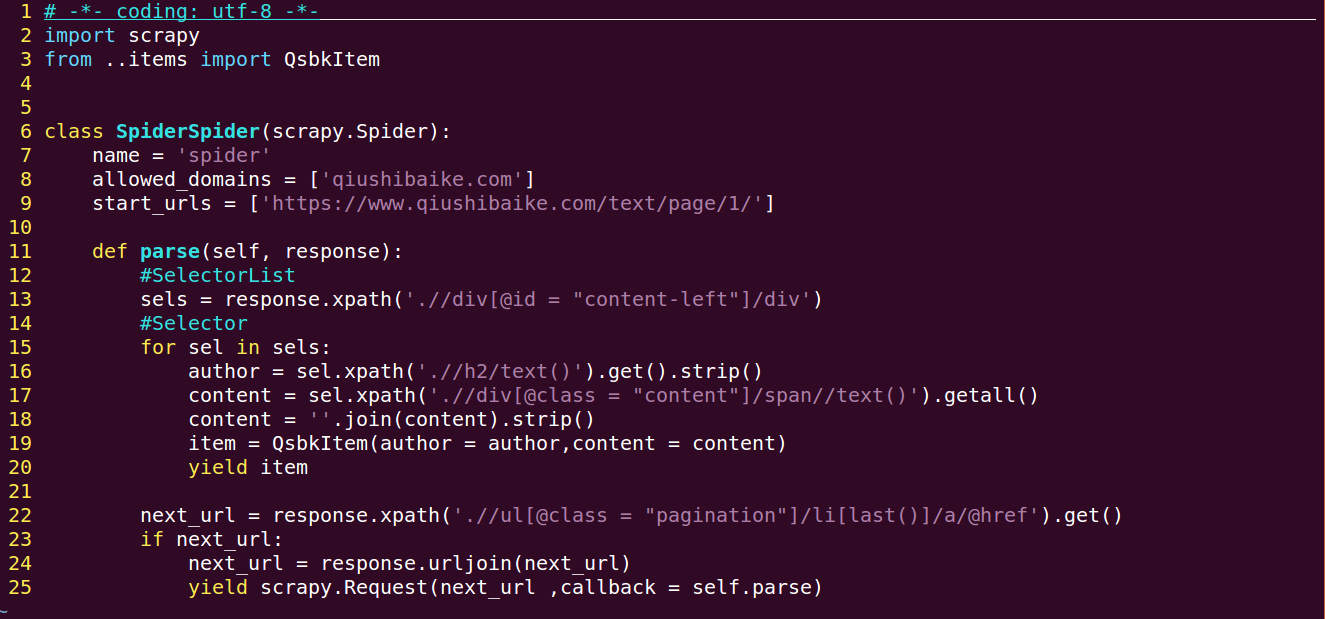
改写spider.py
(5)、效果展示

我们本次一共抓取到了325条数据

(6)、总结(全爬虫流程分析)
1、我们在spider中传入了初始url,并通过引擎传递给scheduler调度队列生成request请求并通过downloader middleware 进入downloader从互联网上下载数据,返回一个response对象,response是一个scrapy.http.response.html.HtmlResponse对象,可以通过css和xpath语法来提取数据
2、提取出的数据是一个Selector or SelectorList对象,并通过downloader middle 经引擎传递给spider中的parse函数进行解析,我们通过getall()获取了字符串文本,列表类型,get()方法返回第一个值,str类型,这里我们亦可使用extract()返回的是列表类型,extract_first()返回列表中的第一个值,str类型
3、解析后我们使用yield将函数转换为一个生成器,不断的从中抽数据,并传递给item pipeline进行处理
4、在item pipeline中我们使用了三个核心方法和初始化函数,首先打来数据(这里采用__init__,当然你可以在open_spider()中执行,接着使用核心方法process——item进行数据处理,最后使用了close_spider()方法关闭了打开的数据)
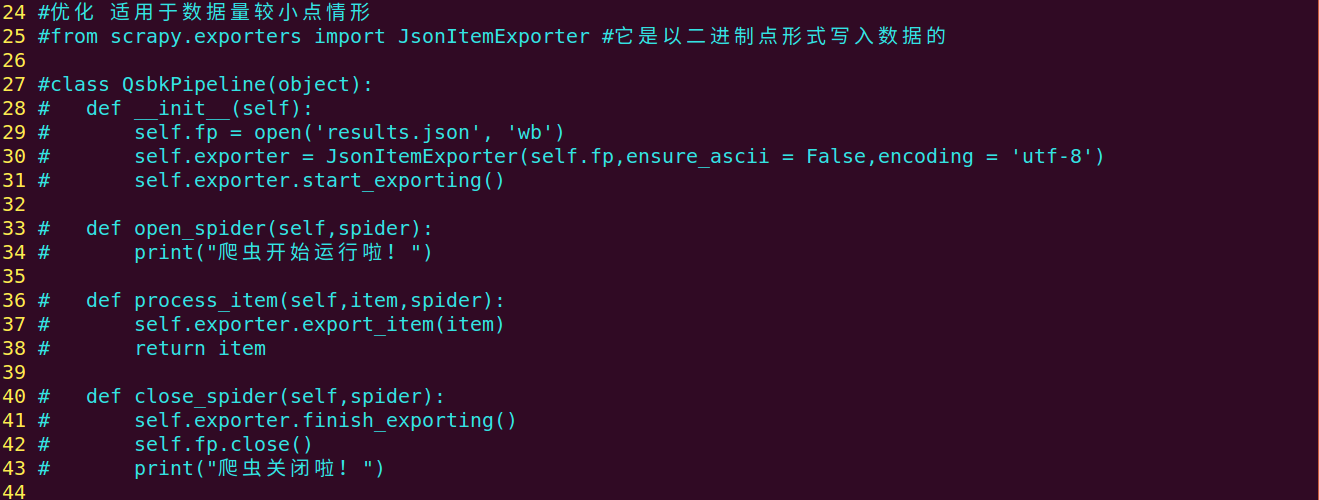
5、在保存json数据的时候可以使用JsonItemExporter和JsonLinesItemExporter这两个类来进行
JsonItemExporter:每次将数据添加进内存最后写入磁盘,好处:一个满足json格式的数据。坏处:数据量较大时:内存占用较多(pipelines.py图片2)
JsonLinesItemExporter:每次调用export_item的时候将数据存储到内存,好处:每次直接将数据写入硬盘,节省内存,适用于数据量较大的情况。坏处:不是一个满足json格式的数据(pipelines.py图片3)
6、最后运行爬虫项目,得到目标结果

