

(1)、数据去重简介
1、数据去重:指在一个数字文件集合中,找出重复的数据并将其删除,只保留唯一的数据单元的过程。
2、分类:
url去重:直接筛选掉重复的url
数据库去重:利用数据库的特性删除重复的数据
3、图解
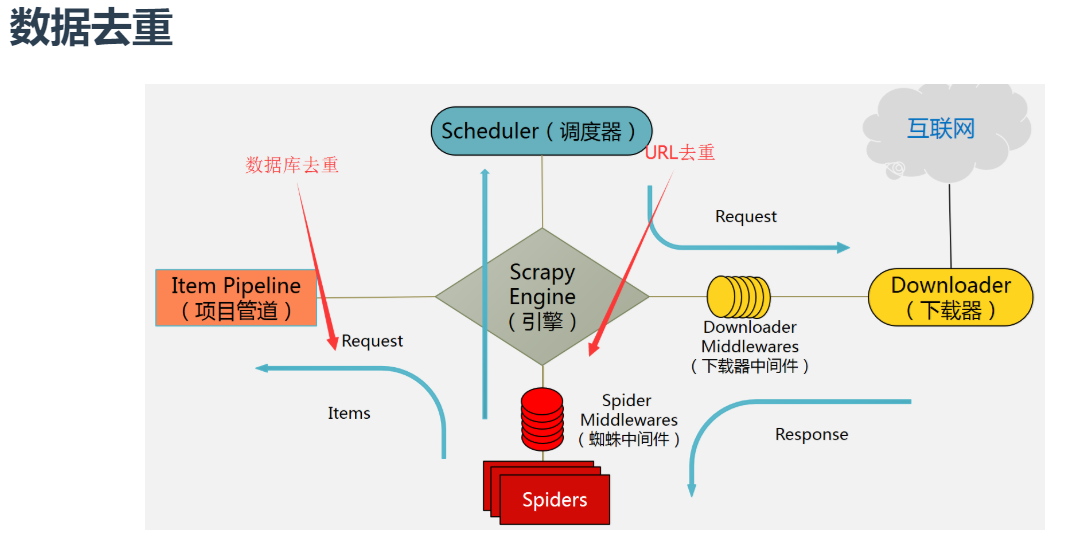
4、为何需要进行url去重?
运行爬虫时,我们不需要一个网站被下载多次,这会导致cpu浪费和增加引擎负担,所以我们需要在爬取的时候对url去重,另一方面:当我们大规模爬取数据时,当故障发生时,不需要进行url链接重跑(重跑会浪费资源、造成时间浪费)
5、如何确定去重强度?
这里使用去重周期确定强度:
周期一小时以内,不对抓取的链接进行持久化(存储url,方便设计成增量抓取方案使用)
周期一天以内(或总量30w以下),对抓取的链接做一个简单的持久化
周期一天以上,对抓取链接做持久化操作
(2)、url去重方法介绍
Scrapy内置的url去重方法:
1、scrapy-deltafetch
2、scrapy-crawl-once(与1不同的是存储的数据库不同)
3、scrapy-redis
4、scrapy-redis-bloomfilter(3的增强版,存储更多的url,查询更快)
自己写方法:init_add_request
1、scrapy-deltafetch详解
安装:
step1:安装Berkeley DB数据库(http://www.oracle.com/technetwork/database/database-technologies/berkeleydb/downloads/index-083404.html)
这个网站需要注册,大家按步骤操作即可,之后找到对应的版本安装即可(一路默认)
step2:安装依赖包:

step3:安装scrapy-deltafetch
启动终端一键安装即可:pip install scrapy-deltafetch

下面补充下ubuntu16.04下包的安装过程(参考博文:http://jinbitou.net/2018/01/27/2579.html)
这里直接贴下载成功界面:首先安装数据库Berkeley DB
接着安装scrapy-deltafetch即可,在此之前同样安装依赖包bsddb3
1 (course-python3.5-env) bourne@bourne-vm:~$ pip install bsddb3 2 Collecting bsddb3 3 Using cached https://files.pythonhosted.org/packages/ba/a7/131dfd4e3a5002ef30e20bee679d5e6bcb2fcc6af21bd5079dc1707a132c/bsddb3-6.2.5.tar.gz 4 Building wheels for collected packages: bsddb3 5 Running setup.py bdist_wheel for bsddb3 ... done 6 Stored in directory: /home/bourne/.cache/pip/wheels/58/8e/e5/bfbc89dd084aa896e471476925d48a713bb466842ed760d43c 7 Successfully built bsddb3 8 Installing collected packages: bsddb3 9 Successfully installed bsddb3-6.2.5 10 (course-python3.5-env) bourne@bourne-vm:~$ pip install scrapy-deltafetch 11 Collecting scrapy-deltafetch 12 Using cached https://files.pythonhosted.org/packages/90/81/08bd21bc3ee364845d76adef09d20d85d75851c582a2e0bb7f959d49b8e5/scrapy_deltafetch-1.2.1-py2.py3-none-any.whl 13 Requirement already satisfied: bsddb3 in ./course-python3.5-env/lib/python3.5/site-packages (from scrapy-deltafetch) (6.2.5) 14 Requirement already satisfied: Scrapy>=1.1.0 in ./course-python3.5-env/lib/python3.5/site-packages (from scrapy-deltafetch) (1.5.0) 15 Requirement already satisfied: PyDispatcher>=2.0.5 in ./course-python3.5-env/lib/python3.5/site-packages (from Scrapy>=1.1.0->scrapy-deltafetch) (2.0.5) 16 Requirement already satisfied: lxml in ./course-python3.5-env/lib/python3.5/site-packages (from Scrapy>=1.1.0->scrapy-deltafetch) (4.2.1) 17 Requirement already satisfied: cssselect>=0.9 in ./course-python3.5-env/lib/python3.5/site-packages (from Scrapy>=1.1.0->scrapy-deltafetch) (1.0.3) 18 Requirement already satisfied: queuelib in ./course-python3.5-env/lib/python3.5/site-packages (from Scrapy>=1.1.0->scrapy-deltafetch) (1.5.0) 19 Requirement already satisfied: w3lib>=1.17.0 in ./course-python3.5-env/lib/python3.5/site-packages (from Scrapy>=1.1.0->scrapy-deltafetch) (1.19.0) 20 Requirement already satisfied: service-identity in ./course-python3.5-env/lib/python3.5/site-packages (from Scrapy>=1.1.0->scrapy-deltafetch) (17.0.0) 21 Requirement already satisfied: Twisted>=13.1.0 in ./course-python3.5-env/lib/python3.5/site-packages (from Scrapy>=1.1.0->scrapy-deltafetch) (18.4.0) 22 Requirement already satisfied: parsel>=1.1 in ./course-python3.5-env/lib/python3.5/site-packages (from Scrapy>=1.1.0->scrapy-deltafetch) (1.4.0) 23 Requirement already satisfied: pyOpenSSL in ./course-python3.5-env/lib/python3.5/site-packages (from Scrapy>=1.1.0->scrapy-deltafetch) (17.5.0) 24 Requirement already satisfied: six>=1.5.2 in ./course-python3.5-env/lib/python3.5/site-packages (from Scrapy>=1.1.0->scrapy-deltafetch) (1.11.0) 25 Requirement already satisfied: attrs in ./course-python3.5-env/lib/python3.5/site-packages (from service-identity->Scrapy>=1.1.0->scrapy-deltafetch) (18.1.0) 26 Requirement already satisfied: pyasn1-modules in ./course-python3.5-env/lib/python3.5/site-packages (from service-identity->Scrapy>=1.1.0->scrapy-deltafetch) (0.2.1) 27 Requirement already satisfied: pyasn1 in ./course-python3.5-env/lib/python3.5/site-packages (from service-identity->Scrapy>=1.1.0->scrapy-deltafetch) (0.4.2) 28 Requirement already satisfied: incremental>=16.10.1 in ./course-python3.5-env/lib/python3.5/site-packages (from Twisted>=13.1.0->Scrapy>=1.1.0->scrapy-deltafetch) (17.5.0) 29 Requirement already satisfied: constantly>=15.1 in ./course-python3.5-env/lib/python3.5/site-packages (from Twisted>=13.1.0->Scrapy>=1.1.0->scrapy-deltafetch) (15.1.0) 30 Requirement already satisfied: Automat>=0.3.0 in ./course-python3.5-env/lib/python3.5/site-packages (from Twisted>=13.1.0->Scrapy>=1.1.0->scrapy-deltafetch) (0.6.0) 31 Requirement already satisfied: hyperlink>=17.1.1 in ./course-python3.5-env/lib/python3.5/site-packages (from Twisted>=13.1.0->Scrapy>=1.1.0->scrapy-deltafetch) (18.0.0) 32 Requirement already satisfied: zope.interface>=4.4.2 in ./course-python3.5-env/lib/python3.5/site-packages (from Twisted>=13.1.0->Scrapy>=1.1.0->scrapy-deltafetch) (4.5.0) 33 Requirement already satisfied: cryptography>=2.1.4 in ./course-python3.5-env/lib/python3.5/site-packages (from pyOpenSSL->Scrapy>=1.1.0->scrapy-deltafetch) (2.2.2) 34 Requirement already satisfied: idna>=2.5 in ./course-python3.5-env/lib/python3.5/site-packages (from hyperlink>=17.1.1->Twisted>=13.1.0->Scrapy>=1.1.0->scrapy-deltafetch) (2.6) 35 Requirement already satisfied: setuptools in ./course-python3.5-env/lib/python3.5/site-packages (from zope.interface>=4.4.2->Twisted>=13.1.0->Scrapy>=1.1.0->scrapy-deltafetch) (39.1.0) 36 Requirement already satisfied: cffi>=1.7; platform_python_implementation != "PyPy" in ./course-python3.5-env/lib/python3.5/site-packages (from cryptography>=2.1.4->pyOpenSSL->Scrapy>=1.1.0->scrapy-deltafetch) (1.11.5) 37 Requirement already satisfied: asn1crypto>=0.21.0 in ./course-python3.5-env/lib/python3.5/site-packages (from cryptography>=2.1.4->pyOpenSSL->Scrapy>=1.1.0->scrapy-deltafetch) (0.24.0) 38 Requirement already satisfied: pycparser in ./course-python3.5-env/lib/python3.5/site-packages (from cffi>=1.7; platform_python_implementation != "PyPy"->cryptography>=2.1.4->pyOpenSSL->Scrapy>=1.1.0->scrapy-deltafetch) (2.18) 39 Installing collected packages: scrapy-deltafetch 40 Successfully installed scrapy-deltafetch-1.2.1 41 (course-python3.5-env) bourne@bourne-vm:~$
使用详解:
scrapy-deltafetch的配置
SPIDER_MIDDLEWARES = {
'scrapy_deltafetch.DeltaFetch' : 100,
}
DELTAFETCH_ENABLED = True #是否启用该中间件 ,我们在settings.py文件中进行配置
DELTAFETCH_DIR = '路径地址' #存储URL的路径
DELTAFETCH_RESET = 1 #是否清空数据库 或者使用 scrapy crawl example -a deltafetch_reset = 1
deltafetch_key:
核心源码分析:
1 def process_spider_output(self, response, result, spider): 2 for r in result: 3 if isinstance(r, Request): #判断是否是url,如果是则进行下一步操作 4 key = self._get_key(r) #通过_get_key()函数生成key 5 if key in self.db: #判断key是否在数据库中 6 logger.info("Ignoring already visited: %s" % r) #日志记录用来判断如果key在数据库中,就忽略它 7 if self.stats: 8 self.stats.inc_value('deltafetch/skipped', spider=spider) 9 continue 10 elif isinstance(r, (BaseItem, dict)): #判断从spider组件中出来item 11 key = self._get_key(response.request) #结果页的url,(不针对过程,即只对拿到数据页的url)进行去重 12 self.db[key] = str(time.time()) #将key塞入数据库并带了时间戳 13 if self.stats: 14 self.stats.inc_value('deltafetch/stored', spider=spider) 15 yield r
1 def _get_key(self, request): 2 key = request.meta.get('deltafetch_key') or request_fingerprint(request) #第一种是遵循你自己设计的唯一标识,第二种就是scrapy内置的去重方案生成的指纹,这里我们点开源码会发现使用了哈希算法 3 # request_fingerprint() returns `hashlib.sha1().hexdigest()`, is a string 4 return to_bytes(key)
1 """ 2 This module provides some useful functions for working with 3 scrapy.http.Request objects 4 """ 5 6 from __future__ import print_function 7 import hashlib 8 import weakref 9 from six.moves.urllib.parse import urlunparse 10 11 from w3lib.http import basic_auth_header 12 from scrapy.utils.python import to_bytes, to_native_str 13 14 from w3lib.url import canonicalize_url 15 from scrapy.utils.httpobj import urlparse_cached 16 17 18 _fingerprint_cache = weakref.WeakKeyDictionary() 19 def request_fingerprint(request, include_headers=None): 20 """ 21 Return the request fingerprint. 22 23 The request fingerprint is a hash that uniquely identifies the resource the 24 request points to. For example, take the following two urls: 25 26 http://www.example.com/query?id=111&cat=222 27 http://www.example.com/query?cat=222&id=111 28 29 Even though those are two different URLs both point to the same resource 30 and are equivalent (ie. they should return the same response). 31 32 Another example are cookies used to store session ids. Suppose the 33 following page is only accesible to authenticated users: 34 35 http://www.example.com/members/offers.html 36 37 Lot of sites use a cookie to store the session id, which adds a random 38 component to the HTTP Request and thus should be ignored when calculating 39 the fingerprint. 40 41 For this reason, request headers are ignored by default when calculating 42 the fingeprint. If you want to include specific headers use the 43 include_headers argument, which is a list of Request headers to include. 44 45 """ 46 if include_headers: 47 include_headers = tuple(to_bytes(h.lower()) 48 for h in sorted(include_headers)) 49 cache = _fingerprint_cache.setdefault(request, {}) 50 if include_headers not in cache: 51 fp = hashlib.sha1() #哈希算法,生成一段暗纹,用来进行唯一标识 52 fp.update(to_bytes(request.method)) 53 fp.update(to_bytes(canonicalize_url(request.url))) 54 fp.update(request.body or b'') 55 if include_headers: 56 for hdr in include_headers: 57 if hdr in request.headers: 58 fp.update(hdr) 59 for v in request.headers.getlist(hdr): 60 fp.update(v) 61 cache[include_headers] = fp.hexdigest() 62 return cache[include_headers] 63 64 65 def request_authenticate(request, username, password): 66 """Autenticate the given request (in place) using the HTTP basic access 67 authentication mechanism (RFC 2617) and the given username and password 68 """ 69 request.headers['Authorization'] = basic_auth_header(username, password) 70 71 72 def request_httprepr(request): 73 """Return the raw HTTP representation (as bytes) of the given request. 74 This is provided only for reference since it's not the actual stream of 75 bytes that will be send when performing the request (that's controlled 76 by Twisted). 77 """ 78 parsed = urlparse_cached(request) 79 path = urlunparse(('', '', parsed.path or '/', parsed.params, parsed.query, '')) 80 s = to_bytes(request.method) + b" " + to_bytes(path) + b" HTTP/1.1\r\n" 81 s += b"Host: " + to_bytes(parsed.hostname or b'') + b"\r\n" 82 if request.headers: 83 s += request.headers.to_string() + b"\r\n" 84 s += b"\r\n" 85 s += request.body 86 return s 87 88 89 def referer_str(request): 90 """ Return Referer HTTP header suitable for logging. """ 91 referrer = request.headers.get('Referer') 92 if referrer is None: 93 return referrer 94 return to_native_str(referrer, errors='replace')
init_add_request方法详解
1 from scrapy.http import Request 2 3 4 5 def init_add_request(spider, url): 6 """ 7 此方法用于在,scrapy启动的时候添加一些已经跑过的url,让爬虫不需要重复跑 8 9 """ 10 rf = spider.crawler.engine.slot.scheduler.df #找到实例化对象 11 12 request = Request(url) 13 rf.request_seen(request) #调用request_seen方法
我们来看看scrapy默认去重机制源码分析上述代码:
1 def __init__(self, path=None, debug=False): 2 self.file = None 3 self.fingerprints = set() #set集合存储的数据不能重复 4 self.logdupes = True 5 self.debug = debug 6 self.logger = logging.getLogger(__name__) 7 if path: 8 self.file = open(os.path.join(path, 'requests.seen'), 'a+') 9 self.file.seek(0) 10 self.fingerprints.update(x.rstrip() for x in self.file)
1 def request_seen(self, request): 2 fp = self.request_fingerprint(request) #利用request生成指纹作为唯一标识 3 if fp in self.fingerprints: #判断唯一标识是否在指纹库中 4 return True 5 self.fingerprints.add(fp) #添加了唯一标识 6 if self.file: 7 self.file.write(fp + os.linesep) #将唯一标识写入文件
(3)、实例体验
创建名为spider_city_58的项目--生成spider.py爬虫
(1)、修改spider.py
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from scrapy.http import Request 4 5 class SpiderSpider(scrapy.Spider): 6 name = 'spider' 7 allowed_domains = ['58.com'] 8 start_urls = ['http://cd.58.com/'] 9 10 def parse(self, response): 11 pass 12 yield Request('http://bj.58.com',callback=self.parse) 13 yield Request('http://wh.58.com',callback=self.parse)
(2)、新建init_utils.py并修改
1 #author: "xian" 2 #date: 2018/6/1 3 from scrapy.http import Request 4 5 def init_add_request(spider, url): 6 """ 7 此方法用于在,scrapy启动的时候添加一些已经跑过的url,让爬虫不需要重复跑 8 9 """ 10 rf = spider.crawler.engine.slot.scheduler.df #找到实例化对象 11 12 request = Request(url) 13 rf.request_seen(request) #调用request_seen方法
(3)、修改pipeline.py
1 # -*- coding: utf-8 -*- 2 3 # Define your item pipelines here 4 # 5 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 6 # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html 7 8 from .init_utils import init_add_request 9 10 class City58Pipeline(object): 11 def process_item(self, item, spider): 12 return item 13 14 def open_spider(self,spider): 15 init_add_request(spider,'http://wh.58.com')
(4)、修改settings.py


(5)、创建测试文件main.py
1 #author: "xian" 2 #date: 2018/6/1 3 from scrapy.cmdline import execute 4 execute('scrapy crawl spider'.split())
运行结果:

结语:针对scrapy-redis的去重,我们后续分析!

