

下面我们来学习Selector的具体使用:(参考文档:http://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/selectors.html)
Selector简介:Scrapy框架提供了自己的一套数据提取方法即Selector(选择器),它是基于lxml构建的,支持xpath、css、正则表达式
下面我们主要介绍Selector与scrapy shell(scrapy中的交互模式)并结合xpath 、css 、 正则表达式的使用
(1)、启动终端并激活虚拟环境
(2)、使用scrapy shell 下载网站例子这里我已百度阅读畅销榜为例进行分析(scrapy shell https://yuedu.baidu.com/rank/hotsale?pn=0---爬取该网站,再使用fetch(‘https://yuedu.baidu.com/ebook/09075cc5a1116c175f0e7cd184254b35effd1a77?fr=bookrank’)下载具体一本书的页面)
(course-python3.5-env) bourne@bourne-vm:~/example/example$ scrapy shell https://yuedu.baidu.com/rank/hotsale?pn=0 2018-05-14 10:56:08 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: example) 2018-05-14 10:56:08 [scrapy.utils.log] INFO: Versions: lxml 4.2.1.0, libxml2 2.9.8, cssselect 1.0.3, parsel 1.4.0, w3lib 1.19.0, Twisted 18.4.0, Python 3.5.2 (default, Nov 23 2017, 16:37:01) - [GCC 5.4.0 20160609], pyOpenSSL 17.5.0 (OpenSSL 1.1.0h 27 Mar 2018), cryptography 2.2.2, Platform Linux-4.13.0-36-generic-x86_64-with-Ubuntu-16.04-xenial 2018-05-14 10:56:08 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'example', 'LOGSTATS_INTERVAL': 0, 'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'USER_AGENT': 'BaiduSpider', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['example.spiders'], 'NEWSPIDER_MODULE': 'example.spiders'} 2018-05-14 10:56:08 [scrapy.middleware] INFO: Enabled extensions: ['scrapy.extensions.memusage.MemoryUsage', 'scrapy.extensions.corestats.CoreStats', 'scrapy.extensions.telnet.TelnetConsole'] 2018-05-14 10:56:08 [scrapy.middleware] INFO: Enabled downloader middlewares: ['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware', 'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware', 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware', 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware', 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware', 'scrapy.downloadermiddlewares.retry.RetryMiddleware', 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware', 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware', 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware', 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware', 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware', 'scrapy.downloadermiddlewares.stats.DownloaderStats'] 2018-05-14 10:56:08 [scrapy.middleware] INFO: Enabled spider middlewares: ['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware', 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware', 'scrapy.spidermiddlewares.referer.RefererMiddleware', 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware', 'scrapy.spidermiddlewares.depth.DepthMiddleware'] 2018-05-14 10:56:08 [scrapy.middleware] INFO: Enabled item pipelines: [] 2018-05-14 10:56:08 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023 2018-05-14 10:56:08 [scrapy.core.engine] INFO: Spider opened 2018-05-14 10:56:08 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://yuedu.baidu.com/robots.txt> (referer: None) 2018-05-14 10:56:09 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://yuedu.baidu.com/rank/hotsale?pn=0> (referer: None) [s] Available Scrapy objects: [s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc) [s] crawler <scrapy.crawler.Crawler object at 0x7f603750edd8> [s] item {} [s] request <GET https://yuedu.baidu.com/rank/hotsale?pn=0> [s] response <200 https://yuedu.baidu.com/rank/hotsale?pn=0> [s] settings <scrapy.settings.Settings object at 0x7f603750eb38> [s] spider <DefaultSpider 'default' at 0x7f60370a54a8> [s] Useful shortcuts: [s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed) [s] fetch(req) Fetch a scrapy.Request and update local objects [s] shelp() Shell help (print this help) [s] view(response) View response in a browser In [1]: fetch('https://yuedu.baidu.com/ebook/09075cc5a1116c175f0e7cd184254b35effd1a77?fr=b ...: ookrank') 2018-05-14 10:56:34 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://yuedu.baidu.com/ebook/09075cc5a1116c175f0e7cd184254b35effd1a77?fr=bookrank> (referer: None)
下面开始我们的实验:
Selector与Css、Xpath 、正则表达式结合使用:

比如我要提取书名,怎么办呢?(这里向小伙伴们说明一点爬取网页后会返回一个response 对象,下面我们使用css)
答:
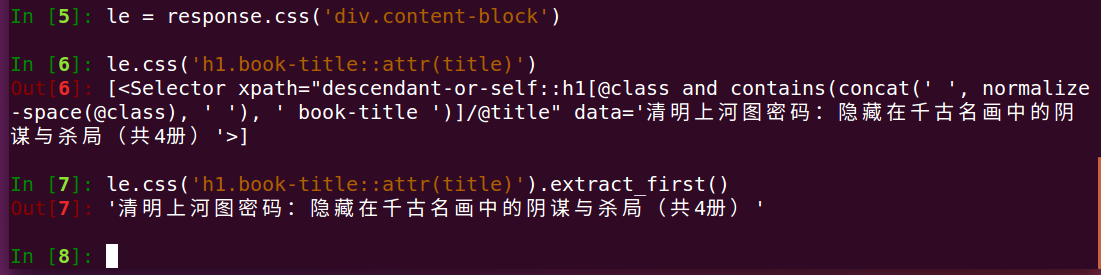
分析:这里我们先选中了class="content-block"并构造了一个le对象--接着我们选取了le对象下的h1标签下的class="book-title"的title属性--最后我们使用了restrict_first()(脱壳)提取了第一个结过并返回给我们一个字符串图书名
CSS语法如下(具体请参见http://www.w3school.com.cn/cssref/css_selectors.asp)
我们再使用xpath语法实现同样的效果:

xpath语法如下:
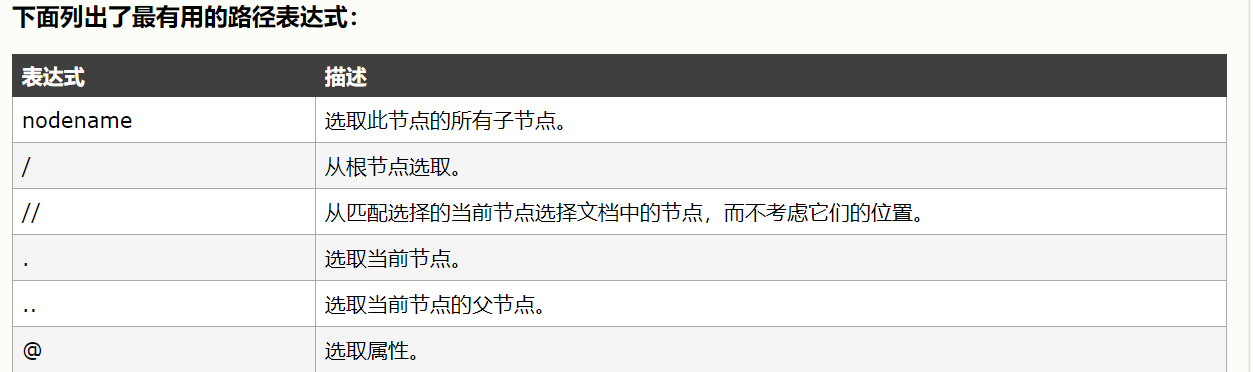
小伙伴们如需进一步了解请参考:http://www.w3school.com.cn/xpath/xpath_syntax.asp
我们再看一例:
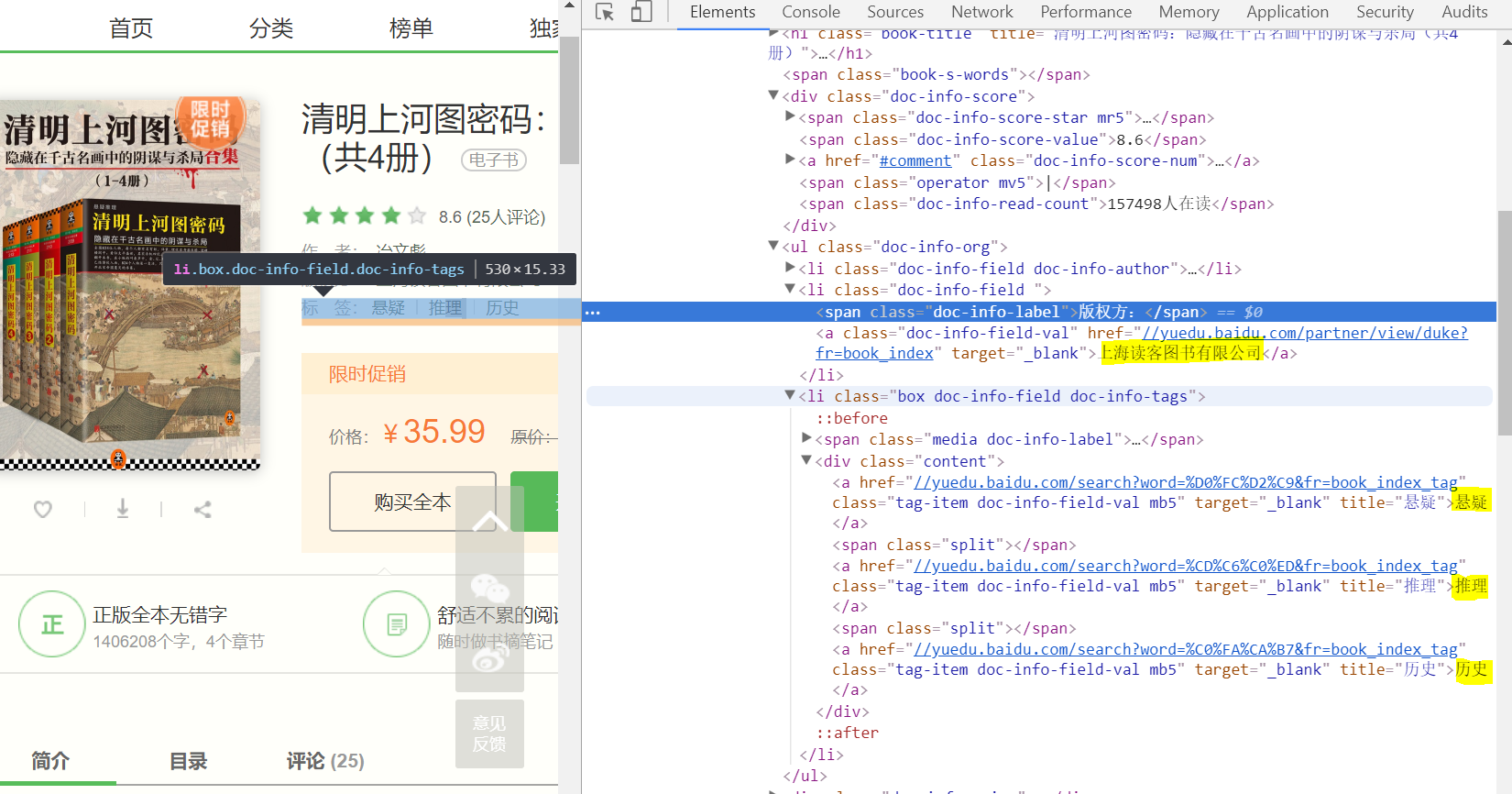
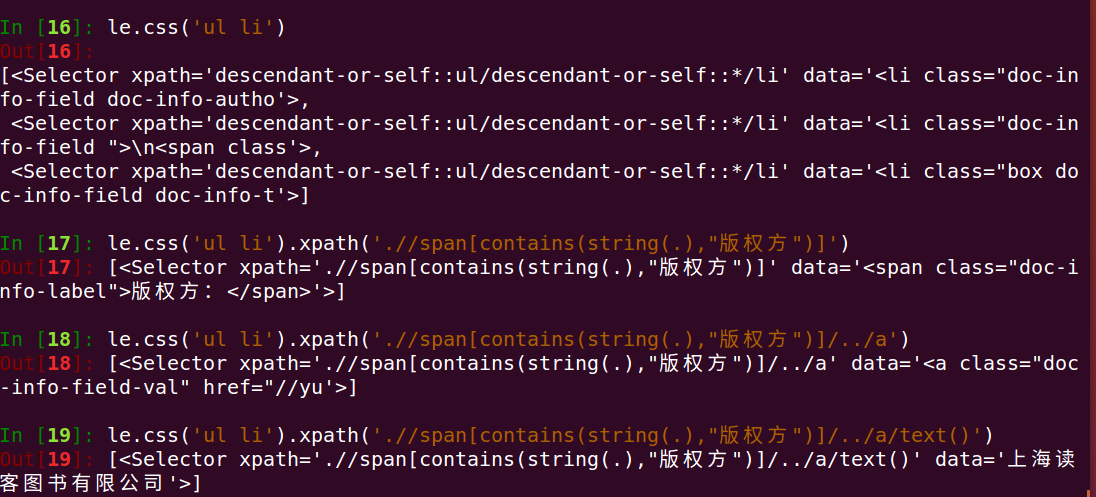
分析:我们先选中了ul 下的li 标签,接着我们使用嵌套选择使用xpath语法选择包好版权方字样的span,再选中它的父标签下的a标签下的文本

分析:这里我们同样使用了嵌套选择,首先选中了li的class为doc-info-tags标签下的 div的class为content的标签,再使用xpaht选择器选取了其下的文本,由于格式问题我们最后选用了re模块进行选择其中的文本并返回一个列表(正则表达式的用法请小伙伴们参考文档)
下面我们介绍下4个方法(我喜欢叫它们为脱壳方法)
(1)extract_first()----返回第一个文本并以字符串形式返回
(2)extract()---返回一个文本字符串列表
(3)re()---返回一个列表的值
(4)re_first()--返回第一个值
其中:(3)(4)针对一些提取需要特殊处理的数据如上例
总结:以上我们分析了Selector与xpath\css\正则的结合使用,建议小伙伴们先学习后三者的基本语法,再多加练习即可,掌握方法即可。


