Maven 依赖树的解析规则
对于 Java 开发工程师来说,Maven 是依赖管理和代码构建的标准。遵循「约定大于配置」理念。Maven 是 Java 开发工程师日常使用的工具,本篇文章简要介绍一下 Maven 的依赖树解析。
依赖树结构
在 pom.xml 的 dependencies 中声明依赖包后,Maven 将直接引入依赖,并通过解析直接依赖的 pom.xml 将传递性依赖导入到当前项目,最终形成一个树状的依赖结构。
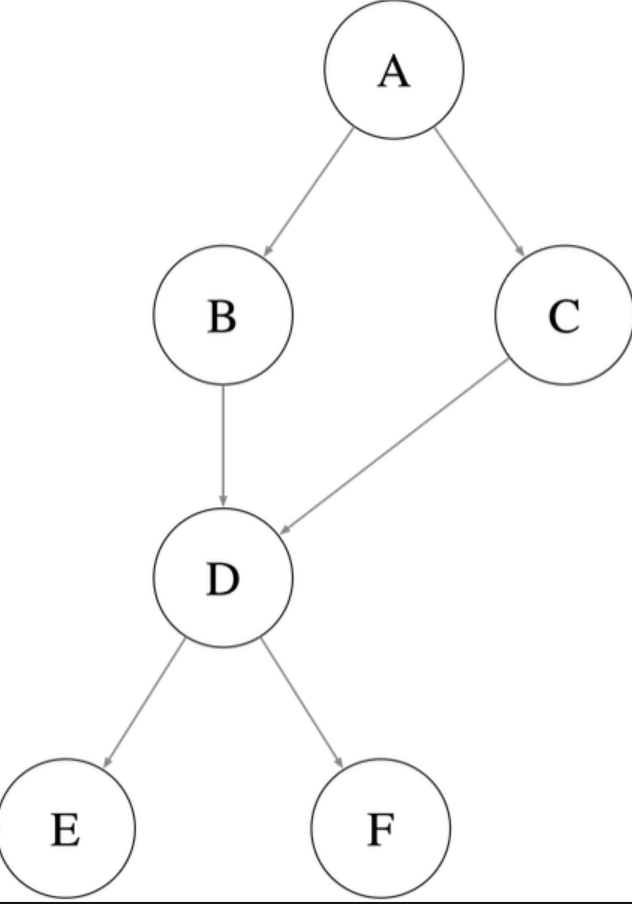
原则:深度优先遍历依赖,并缓存节点剪枝。比如下图:
- A→B→D→E/F
- A→C→D
在第二步A→C→D时,由于节点D已经被缓存,所以会立即返回,不必再次遍历E/F,避免重复搜索。
依赖冲突
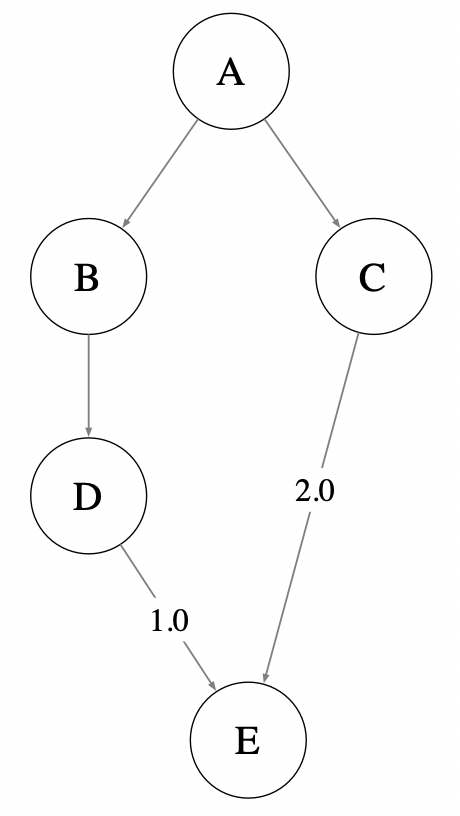
但是假如 2 个包同时依赖了同一个 jar 包,但是这个 jar 包版本不同,规则是什么样的呢?比如下图 A 通过 B 和 D 引入了 1.0 版本的 E,同时 A 通过 C 引入了 2.0 版本的 E。针对这种多个版本构建依赖时,Maven 采用「短路径优先」原则,即 A 会依赖 2.0 版本的 E。如果想引入 1.0 版本的 E,需要直接在 A 的 pom 中声明 E 的版本。
如果 Java 项目过于庞大,或者依赖传递过于复杂时,可以使用 dependencyManagement 定义默认的版本号,一次定义全局生效,避免开发者自行管理依赖的版本。
依赖循环
比如:A 依赖了 B,同时 B 又依赖了 A。这种循环依赖可能不会直接显现,但是可能会在一个很长的调用关系显现出来,也可能是模块架构的设计不合理。
我们可以使用 mvn dependency:tree -Dverbose | grep cycle 来判断项目中是否存在「循环依赖」。
依赖排除
我们可以使用 exclusion 来解决依赖冲突,但是 exclusion 会降低 Maven 依赖解析的效率,因为对应的 pom 文件不能缓存,每次都要重新遍历子树。
对于依赖排除:
exclusion会造成依赖重复扫描和缓存。- 在距离根节点越远的
exclusion,影响的范围越小。 - 依赖树高度越高,引入
exclusion的代价越大。
依赖分析
IDEA 插件
使用 IDEA 的话,可以在对应项目中右击,选择 Diagrams -> Show Dependencies。

Maven 命令行
mvn dependency:tree -Dverbose
公众号
coding 笔记、点滴记录,以后的文章也会同步到公众号(Coding Insight)中,希望大家关注_
代码和思维导图在 GitHub 项目中,欢迎大家 star!


