pandas之transform
在使用Pandas时,有一个功能强大的函数pd.transform,经查阅资料对该函数做一个总结和学习。
以下内容来源于pandas100个骚操作:transform 数据转换的 4 个常用技巧!
pd.transform主要包括4个主要的功能:
-
- 数值转换
- 分组合并结果
- 过滤数据
- 处理缺失值
一、数值转换
数值转换主要用法:
pd.transform(func, axis=0)func:用户转换的函数,该函数可以是自定义普通函数、字符串函数名、函数列表、函数字典;
axis: 只要是指应用于转换哪个轴。
1.普通自定义函数
首先定义一个每个数加10的自定义函数以及一个df:
df = pd.DataFrame({'A': [1,2,3], 'B': [10,20,30]})
def plus_10(x):
return x+10在df上应用plus_10这个函数:
df.transform(plus_10)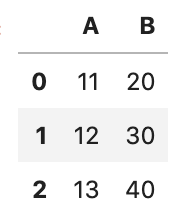
也可以使用更简洁的lambda函数来代替普通函数:
df.transform(lambda x: x+10)2.字符串函数名
func可以是字符串的函数名,比如:sqrt、sum,
df.transform('sqrt')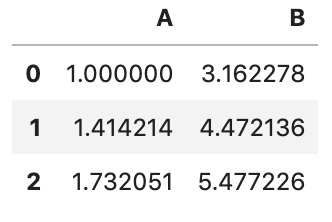
3.函数列表
func可以是一个包含函数的列表,函数可以是第三方库的函数也可以是自定义函数,比如
df.transform([np.sqrt, np.sum])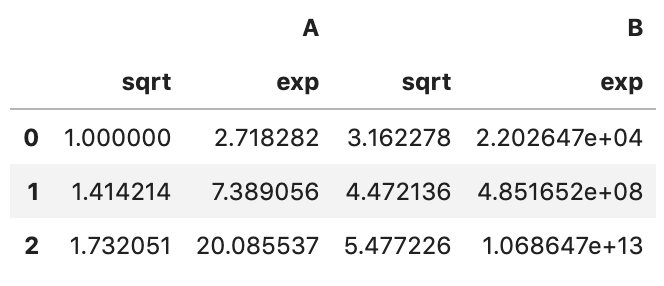
df.transform([np.sqrt, lambda x: x+10])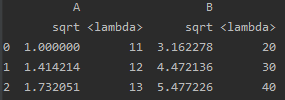
4.指定列函数的字典形式
func可以是字典,字典中指定某一列按照哪个函数进行转换,如:
df.transform({"A": np.sqrt, "B": np.exp})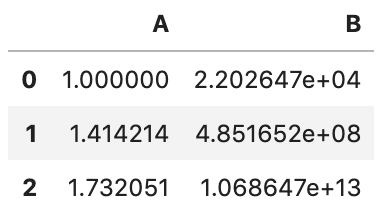
当只指定一列时,则只会返回那一列数据。
二、合并分组结果
该功能可以对分组(groupby)结果进行合并和转换,首先创建一个df:
df = pd.DataFrame({
'restaurant_id': [101,102,103,104,105,106,107],
'address': ['A','B','C','D', 'E', 'F', 'G'],
'city': ['London','London','London','Oxford','Oxford', 'Durham', 'Durham'],
'sales': [10,500,48,12,21,22,14]})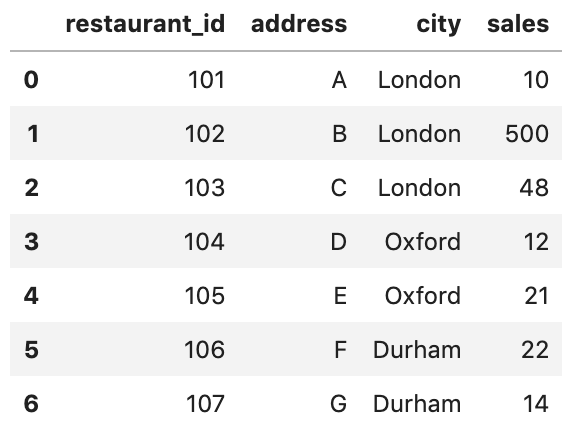
当时用groupby函数时,则可以对数据进行分组,比如用“city”进行分组后,再对每个city的sales进行合并,正常操作是先用groupby分组,然后apply求和,最后merge原表,可以得到:
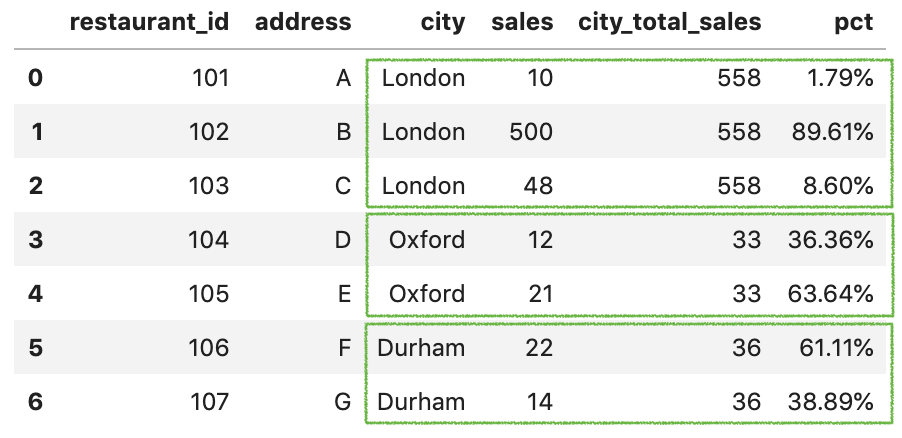
现在transform可以替代后面两个步骤,可以直接新增一列:
df['city_total_sales'] = df.groupby('city')['sales'].transform('sum')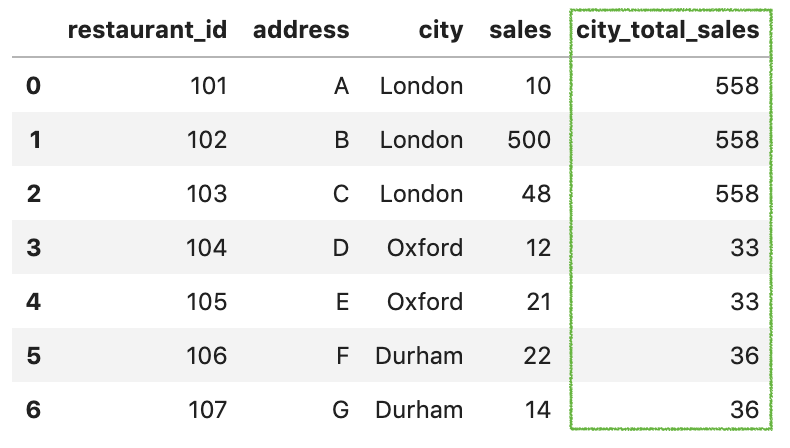
三、过滤数据
这个其实是上面那个的一种应用,可以用来过滤数据,比如向上筛选出上表城市总销量大于40的数据,则:
df[df.groupby('city')['sales'].transform('sum') > 40]
最终就只有London这个城市的所有数据了。
四、分组处理缺失值
按照groupby之后,对每一组内的缺失值分别进行处理,首先创建一个df:
df = pd.DataFrame({
'name': ['A', 'A', 'B', 'B', 'B', 'C', 'C', 'C'],
'value': [1, np.nan, np.nan, 2, 8, 2, np.nan, 3]
})“A”组、“B”组、“C”组内均有缺失数据,假设填补缺失值按照每一组的平均值进行填补,那么每一组的平均值为:
df.groupby('name')['value'].mean()
name
A 1.0
B 5.0
C 2.5
Name: value, dtype: float64此时,把这些平均值分别填补到每一组的缺失值当中,则可以用到transform函数完成替换:
df['value'] = df.groupby('name')['value'].transform(lambda x: x.fillna(x.mean())) 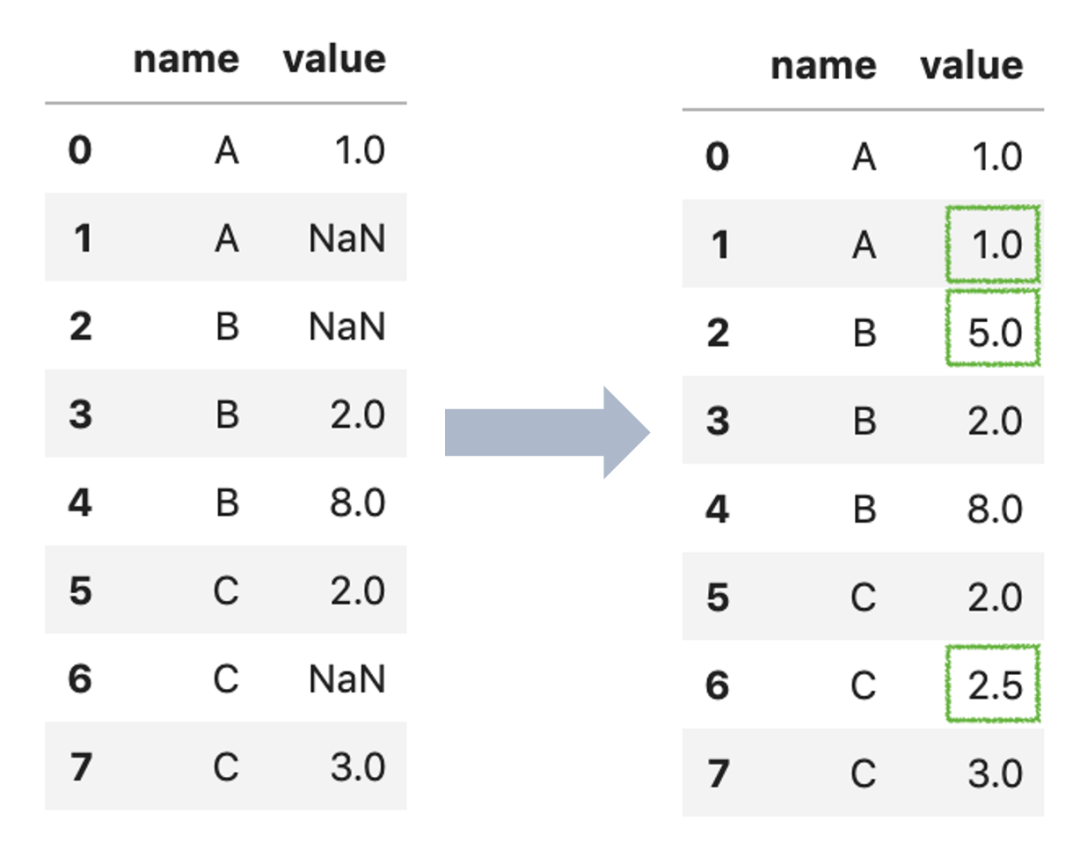
以上就是有关transform函数的几个用法,在数据处理中还是比较有用的。

