【机器学习基础】无监督学习(4)——Word Emdedding
前面介绍了一些降维的方法(PCA、TSNE、LLE、AutoEncoder),本节主要来了解一下在自然语言处理中的数据的降维,即如何把语言进行降维表示。
0.Word Embedding简介
Word Embedding对于自然语言处理是一个关键的技术。在前面讲到的机器学习算法都是基于数据本身的,而如果数据是一系列语言,要处理这样的文本数据,就需要一些特定的方法了。
前面说到有时我们处理文本数据时,用One-hot编码来对文本数据进行处理。比如世界上只有五个单词[apple、banana、cat、dog、elephant],
那么apple可以表示为[1,0,0,0,0],banana表示为[0,1,0,0,0]......
但这样表示就会有一个问题,对于每一个单词(字)都是独立的,无法理解其真正的含义。也就是“语义”。
我们想要让机器理解语言真正的语义,比如对一堆单词进行分类:
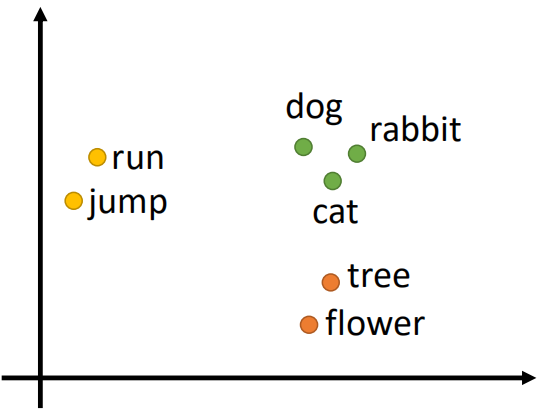
对于run和jump可以看做一类,表示动作,dog、rabbit、cat可以看做一类,表示动物,tree和flower可以看做一类,表示植物。
因此,我们想要机器学习能够达到这样的效果,即把这一堆单词映射到空间中,对于相近的单词距离比较近,而对于语义不相似的离的比较远。这其实就是Word Embedding(词嵌入模型)。
用比较官方的解释就是:一种用于描述词分布关系来实现语义理解的方法。
也就是说,机器能够通过无监督学习的方式“阅读”大量的文本,然后根据其上下文,理解某一个单词的语义,比如:
“乔丹是一名美国职业篮球运动员”
“科比是一名美国职业蓝球运动员”
句中“是一名美国职业篮球运动员”是两句话所共有的,则可以推断“科比”和“乔丹”应该是表达的同一个语义。在将这两个单词映射到空间中,二者应该是相近的。
这时就需要利用Word Embedding来对上下文进行分析,从而达到语义的表达。该技术在NLP方向中应用较广。下面介绍几种Word Embedding的方法。
1.Word Embedding方法
1.1 Count Based
这种方法就和名字一样,基于计数统计的方法来实现理解上下文的目的。比如前文中“科比”和“乔丹”经常一同出现同一篇报道中,那么可以推断二者是同一种语义(表示篮球运动员)。
用V(wi)表示单词wi的向量,用V(wj)表示单词wj的向量,如果wi和wj是具有相似语义的单词,那么二者距离应该很小。
在训练的时候,则统计wi和wj一同出现的次数,用Nij表示,那么在训练时则希望V(wi)·V(wj)与Nij的距离越小越好:
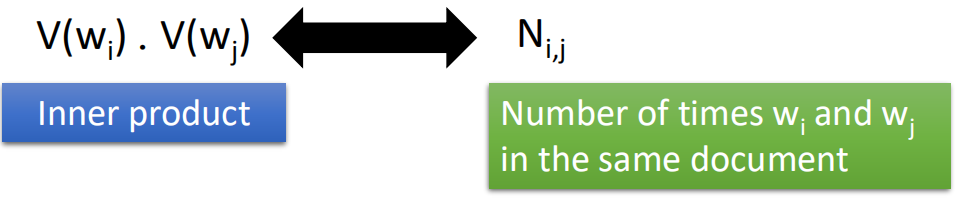
一个关于Count Based的例子https://nlp.stanford.edu/projects/glove/
1.2 Prediction Based
基于预测的方法就是利用神经网络的方法,来对样本进行训练,从而得到语义的方法。先举个例子,首先收集一系列的文本数据:

然后训练一系列的网络,这些网络是根据前面的输入得到下一个词:

这个网络输入“潮水”和“退了”,输出为“就”.....(其实这是一个循环神经网络,这里暂时没有说到RNN,就认为就是一种神经网络)。
这里注意输入和输出都是事先用one-hot编码后的数据,然后将输出与真实值求crossentropy就可以训练了。那么如何得到每个词在其它空间中的映射(word embedding)呢,这个到后面再说。
这个网络模型还有另外一个用途:Language Modeling。也就是估测一句话的概率,可以用于语音识别和语句生成。
比如语音识别中“wreck a nice beach”和“recognize speech”发音相同,在识别中需要知道两句话哪个概率更大;
而语句生成经常用于聊天机器人来给出概率最大的那个回答。
下面先说这样的网络是如何训练和估测一句话的概率的,然后再回到我们的word embedding的问题上。
以“wreck a nice beach”这句话为例,估测这句话出现的概率,即:
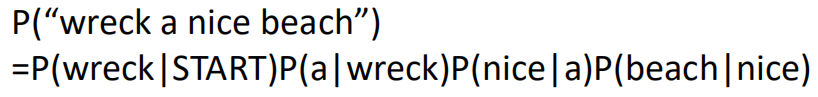
于是我们需要知道上面每一部分的概率的大小再相乘就可以了,因此我们需要训练一个网络:
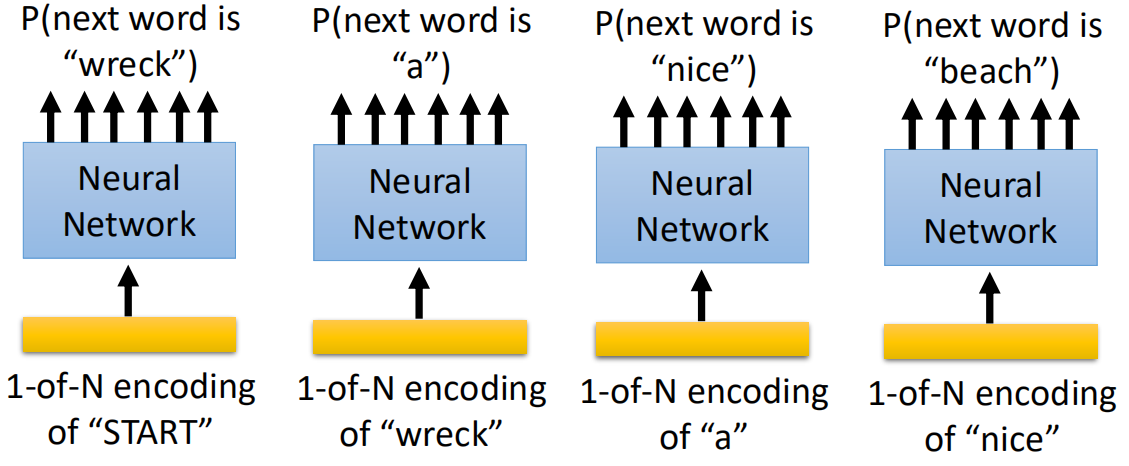
输入某一个单词,输出为该单词后面一个单词的概率大小。这样就可以预测一个句子出现的概率大小了。
这个就是一个简单的Language Model,到后面还有其它的方法来预测一句话的概率大小,如HMM、RNN,这个到后面会单独章节来说。
然后回到Word Embedding的问题,我们想要理解每一个单词的语义,或者说要将这些单词映射到另一个空间,使得具有相同语义的单词靠的比较近,不相同的相距较远。
假设训练好的网络模型的结构原本是这样的:
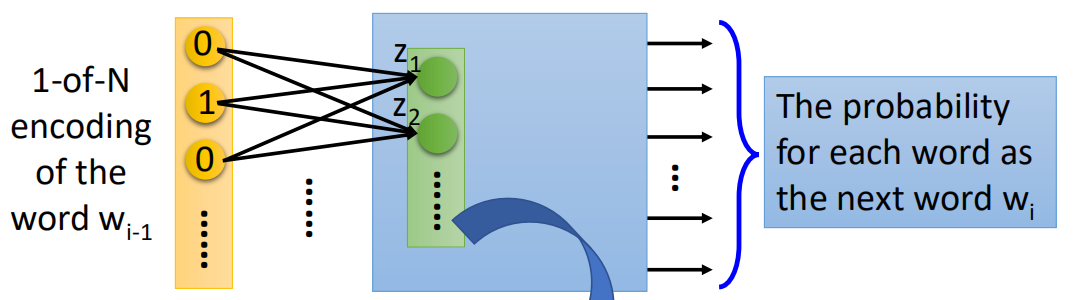
现在想要获取wi-1在另一个空间的投影向量,其实很简单,只需要把第一层网络的输入值拿出来表示wi-1即可。也就是wi-1乘以权重之后(到激活函数之前)那一步拿出来。
为什么可以这样呢?其实神经网络本身就是一个特征提取的过程(这里我理解的是并不一定是拿第一层,其它层的输入其实应该也行),就好像把原本的数据进行了降维,提取出了特征。
这个过程就好像之前说到的AutoEncoder中的Encoder部分的降维的道理。
把每一个单词都这样转换之后,然后再画到同一个图上就是如下这样的:
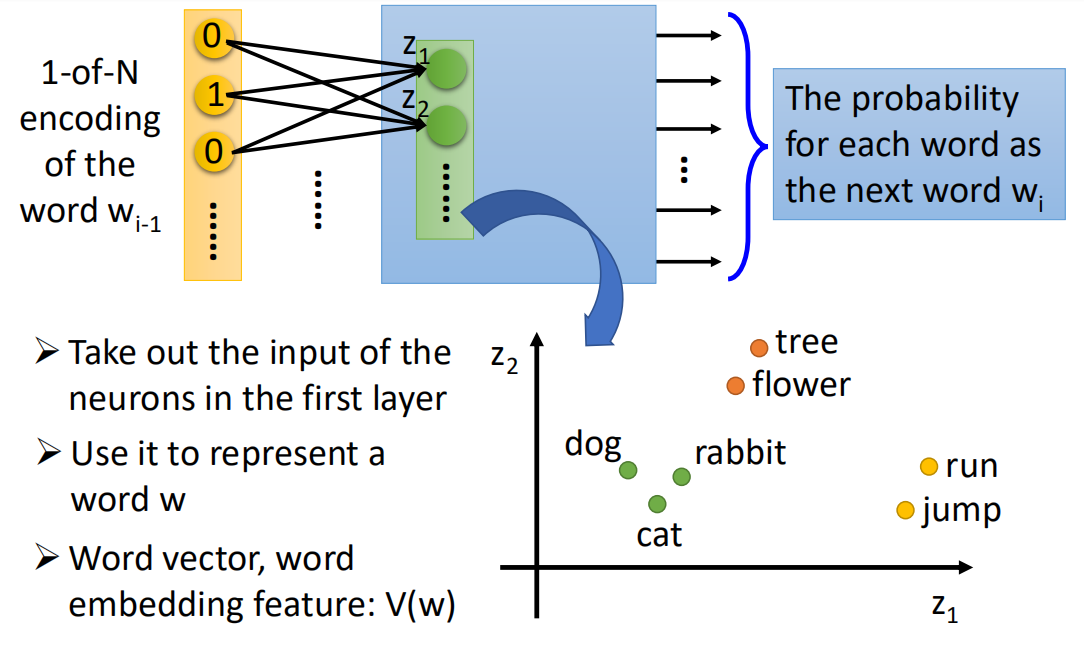
还是前面那个例子,当把“科比”和“乔丹”分别输入到网络中,由于网络的输出结果是一致的,都是“是一名美国职业篮球运动员”,那么在学习时,二者的输入在经过转换后必然是越接近越好。
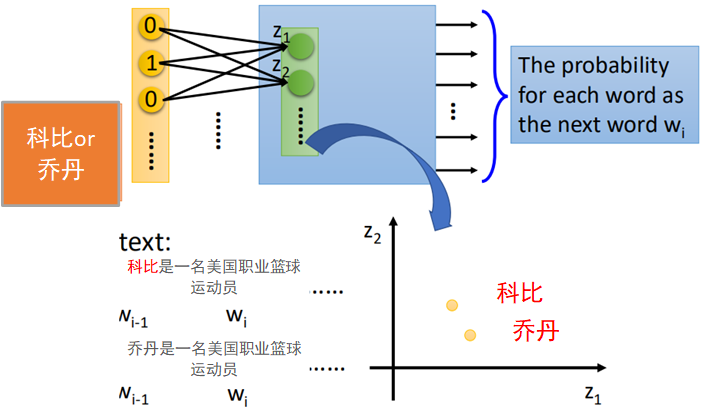
当“科比”和“乔丹”经过第一个linear_transform之后,他们所对应的向量在坐标轴上就是比较接近的。
当然,有时通过1个单词来预测下一个单词有时不够,那么网络也可以把前两个单词都作为模型的输入:
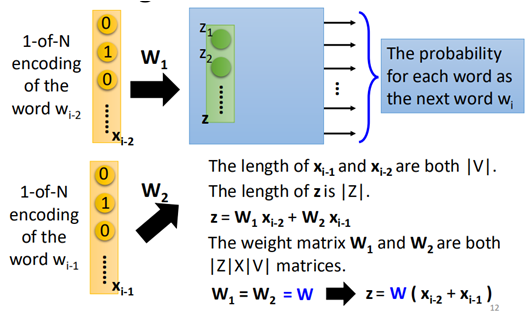
该模型中,将wi-2和wi-1作为模型的输入进行训练。
而在实际中one-of-encoding具有很高的维度,那么w1和w2也分别具有很高的维度,通常为了降低参数的数量,通常令w1=w2。这样类似于在cnn中的filter的效果。也就是说:
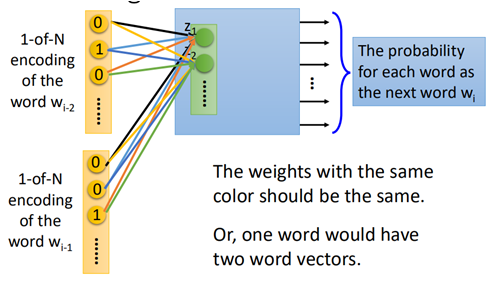
如果w1与w2不相同的话,那么在训练后,会导致同一个单词因为所在的位置不同,而最终所得到的word vector则可能会不相同。
同样,输入输出的不同可以变成不同的模型,比如常见的还有CBOW和Skip-gram。
所谓的CBOW就是根据某个单词的“前后文”来预测这个单词,其形式如图:

即将其前后的单词作为输入,中间单词作为输出进行网络的训练。
而Skip-gram是给定某个单词,来预测上下文,其形式如图:

即将wi作为输入,wi+1和wi-1作为输出进行网络的训练。
2.Word Embedding的例子
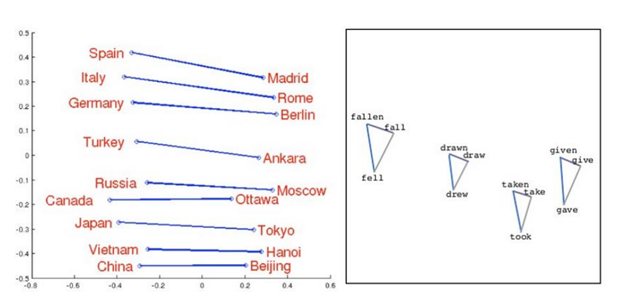
1. 通过模型训练能够国家与首都进行关联,以及单词的过去式、过去分词之间的关联,如下图:
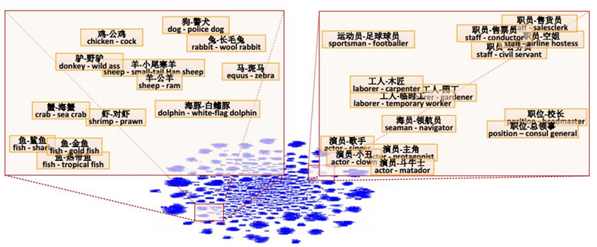
2.词汇之间包含和被包含关系:
3.词汇时间比拟,如:

总结
以上就是有关Word Embedding的相关概念,Word Embedding是一种无监督的学习方式,本上是其还是一种数据降维,不过更多地运用在文本分析和序列分析的问题上,这里主要对其基本概念进行了简要的介绍,后面到深度学习中还会涉及这一部分内容,到时再进一步讨论。

