【机器学习基础】常见损失函数总结
在机器学习三步走中,其中最重要的就是第二步找到用于衡量模型好坏的方法,也就是损失函数,通过求解最小化损失,从而求得模型的参数。前面分别对线性回归、LR以及实战部分的SVM、决策树以及集成学习算法进行了概述,其中都用到了不同的损失函数,今天在这里对机器学习中常见的损失函数进行一个总结。
常见损失函数总结
上面说到,损失函数的选择对于模型训练起到了至关重要的作用,在不同的算法中往往有着不同的损失函数。
甚至有时可能需要根据具体应用场景自定义损失函数,比如预测某个商品的销量,预测结果将直接影响利润,如多预测一个少赚1元,而少预测一个少赚10元,那么此时用均方误差损失函数就不太恰当。
这里暂时不说自定义的损失函数,主要是对机器学习中一些常见的损失函数进行一个总结。
1.均方误差损失函数(Mean Squared Error,MSE)
均方误差损失函数是回归问题中(包括神经网络中也可以使用,但)最常见的损失函数,用于衡量样本真实值与预测值之间的差距,损失函数公式在线性回归中已经给出,这里再看下:
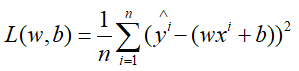
通过最小化损失函数,求得w,b即为模型的参数。前面说到求解方法有解析解即最小二乘法,以及梯度下降的方法,这里就不再赘述。
2.均方根误差损失函数(Root Mean Squard Error,RMSE)
均方根误差损失就是均方误差损失函数的平方根,公式如下:
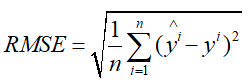
均方根误差损失与均方误差损失函数在效果上是一样的,只不过如果对于均方误差数量级过大时,可以通过开方更好地描述数据,比较好理解。
3.绝对值损失(Mean Absolute Error)
公式如下,跟均方误差损失差不多,也不再解释了
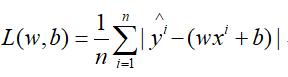
4.对数损失(Log损失)
对数损失也称为对数似然损失,前面关于LR的推导过程中,当给定x,其属于y的概率表示为:
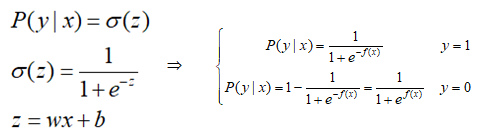
期望对所有的样本都能够正确分类,则有:
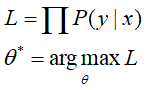 、
、
然后对L两边取对数,注意这里是最大化。那么带入上式,然后两边再取负号,就变成最小化了,最终得到对数损失函数的形式为:
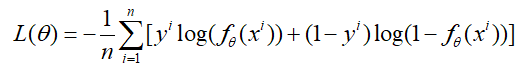
这里还要说一下,其实对数损失函数还有另外一种形式,在GBDT中利用GBDT处理分类问题时提到过,注意上面的类别取值为{0,1},我们只需将取值设为{-1,1},就可得到如下形式的对数损失函数:
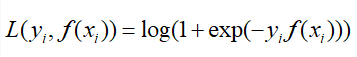
5.交叉熵损失函数(cross_entropy loss)
交叉熵损失和对数损失其实是一样的(很多资料中有提到),二者的表达式在本质上是一致的。在逻辑回归中说到,LR的损失函数就是交叉熵损失函数,不过是一种二值(二分类)的交叉熵损失。
稍后会给出交叉熵损失的公式,这里既然提到了交叉熵,就顺便说一下交叉熵的概念。参考:https://blog.csdn.net/b1055077005/article/details/100152102
交叉熵
交叉熵来源于信息论,是信息论中一个重要概念,交叉熵是用来衡量两个概率分布之间的差异程度。值越小,差异越小,两个分布就越相似。
先来看一下几个交叉熵的几个前置理论概念。
(1)信息量
信息量是用来消除信息不确定的概念,用于衡量信息所含信息量大小的一个东西,比如“太阳从东边升起”这句话,由于太阳本身就是从东边升起的,这句话的不确定为0,相当于一句废话。
因此,信息量是与事件的概率成反比的,公式为:
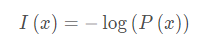
(2)信息熵
在决策树的开篇说到信息熵的概念,信息熵是信息量的期望值,而信息量与概率成反比,那么信息熵的公式如下:
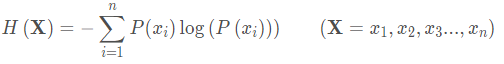
(3)KL散度(相对熵)
相对熵(KL散度)是衡量两个概率分布之间的差异性的指标,假设同一随机变量的两个独立的分布P(x)和Q(x),那么相对熵(KL散度)的公式为:

在机器学习中常常用P(x)表示样本真实的分布,Q(x)表示预测的分布,通过比较二者的分布,使其越接近越好。比如对于一个三分类,真实值y=[1,0,0],模型所预测的结为[0.7,0.2,0.1],那么KL散度计算为:
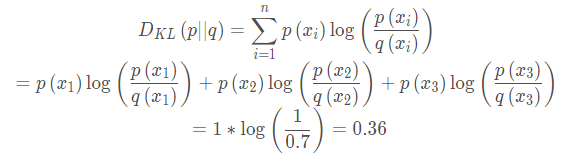
KL散度越小,说明两个分布越接近。
接下来我们将上述的KL散度公式进行展开:
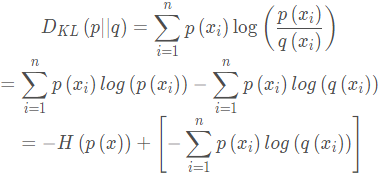
可以看出,前半部分即为信息熵,这个后半部分称为交叉熵,于是交叉熵的公式为:
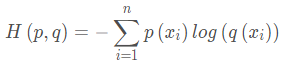
那么KL散度=交叉熵-信息熵。
在机器学习中,由于P(x)是原本样本的真实标签,其分布是已知的,那么在KL散度中信息熵是确定的,因此只需后一项,即交叉熵来确定两个分布的差异程度就可以了。
KL散度越小,两个分布就越接近,又因为KL散度等于交叉熵减去一个常量,因此,在机器学习中,只需要交叉熵来作为损失函数就可以了,只需要最小化交叉熵损失函数即可。
综上,交叉熵损失函数的公式即为:
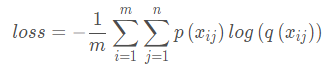
根据上面举的那个例子,我们知道,交叉熵损失常用在多分类当中。
因此对于对数损失是一种特殊的二分交叉熵损失的形式,交叉熵常用于多分类中,对数损失用于多分类也叫交叉熵损失(cross_entropy),其实二者本质上是一样的,只不过所用的习惯不同。
6.指数损失
指数损失在后来添加AdaBoost推导部分的时候有提到,AdaBoost就是使用的指数损失,具体为什么AdaBoost要用指数损失,在李航《统计学习方法》8.3节中有详细证明,比较复杂,就不说了。
指数损失公式如下:
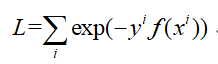
式中可以看出,当真实值y与预测值f(x)同号时,损失是比较小的,而当y与预测值f(x)异号时,则惩罚急剧增大,对误分类的惩罚增大,从而提升误分类样本的权重。
因此指数损失对于噪声点的样本比较敏感,一旦分错,由于Boost方法属于串行的方式,因此会干扰后面的学习效果,这也是AdaBoost的一个缺点。
7.Hinge Loss
这个损失之前在SVM中也提到过,说当采用梯度下降的算法进行求解时需要定义出一个当样本被正确分类,且确定性较强时,损失为0,否则,损失就不为0。那么此时就需要用到Hinge Loss了,其图像为:
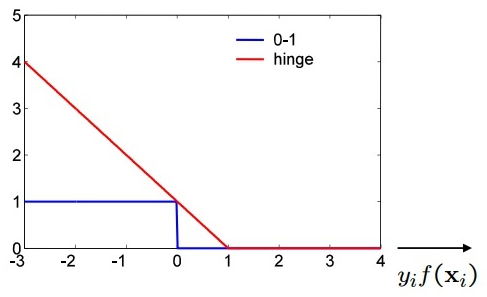
可以看到,即样本标签y为{-1,1},预测值y'当其大于1或者小于-1时,损失函数为0,对于y'∈[-1,1]时,损失不为0。
其公式为:
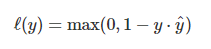
y是真实值,y'是预测值
在SVM中,当样本被确定正确分类,即预测结果大于1或者小于-1(注意这里并不是说只要大于1或者小于-1就行,而是要根据实际标签来说的)时,损失为0,就不再关心这些点了,而对于在[-1,1]之间的,或者分错的点会驱使“直线”进行移动,如图所示:
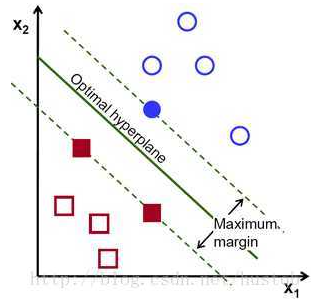
上图所示,如果分割超平面误分类,则Hinge loss大于0。Hinge loss驱动分割超平面作出调整。 如果分割超平面距离支持向量的距离小于1,则Hinge loss大于0,且就算分离超平面满足最大间隔,Hinge loss仍大于0。
因此Hinge Loss的精髓在于,对于确定性强的点(被正确分类,且距离分隔超平面距离大于1)进行过滤,而只关心那些误分类的和“支持向量”。
多分类中Hinge Loss
在SVM的多分类中,同样也使用Hinge Loss作为损失函数,不过稍微有些改变:
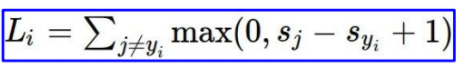
举个例子,加入有三张图片:猫、车和青蛙,通过SVM的输出值如下:

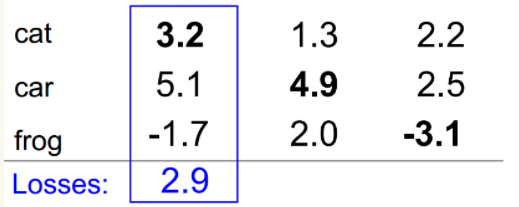
那么根据上面多分类的Hinge Loss的计算方法:首先计算第一个样本的损失:
然后依次求出第二个第三个样本的损失,进行求和并平均:
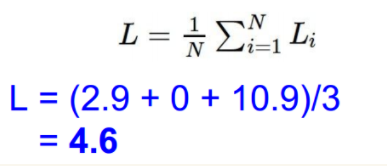
参考资料CS231n 2016 通关 第三章-SVM与Softmax
后面关于SVM这一部分在看完李宏毅老师从另一个角度的讲解后,以及structure SVM有关内容,后面会单独再开一片进行总结,这里就暂时不进行讨论了。
下面图片来源于网络,不是很清晰,也算一个总结,后续如果遇到新的会再进行添加。

后记:
上面即为在机器学习中的常见的一些损失函数,其实并不是很全,只是目前为止学习到的,就先总结到这里,算是对之前的算法进行一个回顾。
在实际应用中要根据所使用的的算法的框架,找到所要使用的损失函数的参数,一般不同的框架下,其参数的字段值也不同,这只能在实际用到时再取说明了;
其实有时经常需要具体根据应用场景去自定义或者对原始的损失函数进行修改。
这一部分内容暂时不是很多,可能有些东西没有想到,后面有什么想起来的或者遇到后再回来添加,排版有点随意~下一更就回到深度学习中的一些技巧。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构