【Python机器学习实战】决策树与集成学习(三)——集成学习(1)Bagging方法和提升树
前面介绍了决策树的相关原理和实现,其实集成学习并非是由决策树演变而来,之所以从决策树引申至集成学习是因为常见的一些集成学习算法与决策树有关比如随机森林、GBDT以及GBDT的升华版Xgboost都是以决策树为基础的集成学习方法,故将二者放在一起进行讨论。本节主要介绍关于集成学习的基本原理,后面会介绍一些典型的集成学习算法及应用。
集成学习从字面上就是集成很多分类器进行学习的过程,通过将一系列弱分类器的模型做一些简单的线性组合,最终形成了一个较强的分类器。因此集成学习的一般思路有以下三种:
-
- 通过组合不同类型的分类器进行提升的方法
- 将相同类型不同参数的弱分类器进行组合
- 将相同类型但不同训练集的弱分类器进行组合提升
一般第一种不是很常见,第二种和第三种较为常见,二者的主要区别是生成弱分类器的方式不同,第二种是期望生成的相互独立的分类器,分类器之间相互依赖性不强,相当于并行生成的方法,比较有代表性的Bagging算法就属于这一类,而Bagging中比较有名的是RF随机森林算法;第三种是一种顺序生成的模型,其在原来弱分类器的基础上,不断调整样本,从而得到提升,分类器之间具有较强的依赖性,相当于串行的方法,其著名的代表为Boosting,而Boosting中最具有代表性的为AdaBoost。下面分别对这两类进行介绍。
Bagging和随机森林
Bagging的全称为Bootstrap aggregating,其思想就是源于Bootstrap,Bootstrap主要用于发现样本的概率分布,通过“自举”的方法,不断自采样模拟随机变量真实分布生成样本集,其主要做法为:
-
- 从样本集X中随机抽取一个样本,然后将样本放回;
- 重复抽取N次,生成一个样本数为N的样本集;
- 重复上述步骤,完成M次,生成M个样本大小为N个样本集。
因此参考Bootstrap的方法,Bagging的做法就是不断抽取数据集,并用抽取的数据集训练弱分类器的过程,具体来说:
-
- 利用Bootstrap的方法抽取M个样本大小为N的数据集;
- 通过抽取的数据集训练M个弱分类器;
- 将M个弱分类器进行集成,一般为为简单的线性组合。
所谓的简单线性组合通常做法是:
-
- 对弱分类器的分类结果进行简单投票
- 对于回归则是简单的线性加权
为什么利用集成学习能够将弱分类器组合一起就能成为一个较强的分类器呢?
我们假设有M个弱分类器G1、G2、...、GM,所计算得到的映射结果分别为g1、g2、...、gM,则这些分类器通过线性组合得到的结果为:

假设弱分类器的错误率为ε,则有:
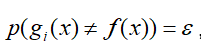
根据霍夫丁不等式https://www.cnblogs.com/nolonely/p/6155145.html:
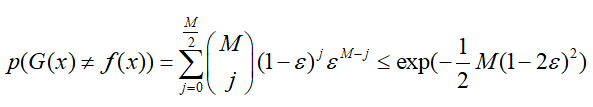
从此式中可以看出错误率随着M的增大呈指数减小,理论上M→∞,ε→0。
因此多个弱分类器组合在一起,就成为了一个强分类器。然而,在Bagging中我们前面提到,每个弱分类器的错误率是相互独立的,但显然这并不现实,因为数据来源于同一个数据集生成,存在一定的相关性,因此,Bagging比较适用于“不稳定”的分类器,即对数据比较敏感的分类器,若训练样本稍微改变,所得的结果就会有较大的变化,效果就越好,Bagging能够显著提升。
随机森林
Bagging中有一个著名的算法为随机森林(RF,Random Forest),随机森林就是利用Bagging的思想,利用决策树模型,生成很多个决策树的弱分类器,不同于普通的Bagging算法,随机森林在建模过程中,不但随机抽取M个样本量为N的样本集,在每个弱分类器即决策树建立的过程中,在生成节点时还从可选的特征中随机挑选出一部分特征进行节点的分裂。那么总结下来随机森林的生成流程如下:
-
- 如果训练集大小为N,对于每棵树而言,随机且有放回地从训练集中的抽取N个训练样本(这种采样方式称为bootstrap sample方法),作为该树的训练集;
- 如果每个样本的特征维度为M,指定一个常数m<<M,随机地从M个特征中选取m个特征子集,每次树进行分裂时,从这m个特征中选择最优的,通常情况下特征的选取数量为m=log2d;
- 每棵树都尽最大程度的生长,并且没有剪枝过程。
随机森林的分类效果与下面因素有关:
-
- 前面有提到每个分类器要尽可能地独立,因此森林中任意两棵树的相关性越大,错误率就越大;
- 另一个就是随机森林中每棵树的分类能力,每棵树的分类能力越强,则最终的分类错误率就越低。
- 同时,随机森林中树的数量也是影响其性能和效率的参数,当树的数量较少时,随机森林分类的误差较大,性能差,但当数量大到一定规模时,树的复杂度将大大提升。
上面提到通常特征的选择数量为m=log2d,当减小选择特征数量m时,树的相关性和分类能力都会同时降低,增大m时,树的相关性和分类能力也会提升,因此需要平衡二者选取合适的m。
那么为什么要选择分类器能力强作为基分类器呢?从随机森林的期望和方差来看:

样本的权重并没有改变,因此整体的期望与基分类器相同,当选弱分类器作为基分类器时,则模型可能具有较大的偏差,则导致整体的偏差较大,因此必须选取较强的分类器作为基分类器。同时从方差公式来看,整体模型的方差小于等于基模型的方差,随着模型数量m的增多,整体方差也在逐渐减小,从而防止过拟合的能力变强,但是,当模型数量达到一定数量时,方差第二项对于方差的改变作用很小,因此防止过拟合能力达到极致,这也解释了为什么树的数量为什么不能无限大。
换句话说,也就是随机森林(Bagging)方法更加专注选择较强分类能力的基分类器,注重降低偏差。
那么,如何来衡量随机森林的好坏呢?通常采用精度估计的方法来评价模型的好坏,而其中袋外(OOB,Out of Bag)精度评估方法可以在不加入测试样本的情况下评估随机森林分类器的好坏。随机森林在构建过程中,每棵树都有约1/3的样本集((1-1/m)^m,当→∞时约等于37%≈1/3)没有参与训练,这部分数据称之为OOB数据。分别对每个袋外数据利用随机森林对这部分样本进行分类,将误分类的占总样本的比率作为袋外错误率,实质上相当于进行了k折交叉实验。
下面举一个简单的随机森林的例子,还是用前面决策树中气球的例子来说明,由于颜色对于结果不起作用,故先删去该特征,在构建随机森林时,每次选取1个特征,即m=1,那么构建三棵树如下:

那么给定一个样本:小孩、用脚踩、小气球是否会发生爆炸,那么根据上面建立的森林,进行投票表决(上图中红线路径),爆炸票数1,不爆炸票数2,因此最终结果为不爆炸(也可以用概率的线性加权,最终结果也是不爆炸)。
这里就不说随进森林的建立实现了,后续会利用数据集和python带的sklearn包对随进森林进行实现。
Boosting与AdaBoost
集成学习的另一种思想方法就是Boosting的方法,Boosting是基于概率近似正确(PAC)理论中的可学习性而来,所谓PAC的可学习性是指算法能够在合理的时间内,以足够大的概率输出错误率较小的模型,分为“强可学习性”和“弱可学习性”。
-
- 强学习性是指存在一个多项式算法可以学习出准确率很高的模型;
- 弱学习性是指存在一个多项式可学习但仅可学习到准确率略高于随机猜测的模型;
- 这两者在PAC的学习框架下是等价的,这也就意味着只要找到了弱学习模型就可以把其变为强学习模型(这一部分涉及到PAC相关理论,有兴趣后续再进一步学习)。
Boosting算法就是利用了这种思想,将弱学习算法提升为强学习算法,其具体做法是:
- 根据当前训练数据训练出一个弱模型;
- 根据弱模型的表现在下一轮训练中改变样本的权重,具体而言就是:让弱模型在做错的样本中在后续学习中受到更多的关注,同时让弱模型表现好的样本在后续训练中获得更少的关注;
- 最后根据弱模型的表现决定弱模型的话语权,即投票表决时的可信度。
那么上述过程就产生了两个问题:
- 在每一轮训练中如何改变样本的权重;
- 如何将弱分类器组合成为一个强分类器。
AdaBoost针对第一个问题提高错误分类样本的权重降低正确样本权重的做法,对于第二个问题AdaBoost采用加权多数表决的方式,具体来说就是加大误差率小的弱分类器的权值,在表决中起到更大的作用,同时减小误差率大的分类器的权重,使其话语权变小。具体算法过程为:
“”“”
输入:样本数量N的数据集、弱分类器算法、迭代次数M
输出:强分类器G
- 初始化数据集的样本权重W0=(w01,w02,...,w0N);
- 对于迭代次数1~M:
- 根据弱分类器算法和权重训练出一个弱分类器gk,并计算加权错误率ek:
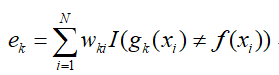
-
- 根据加权错误率,计算权重的更新的大小为:

-
- 根据权重更新的大小对样本进行权重进行更新:
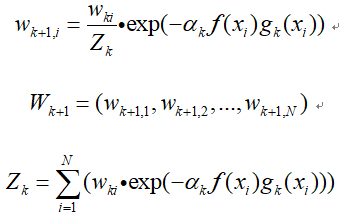
- 对弱分类器进行加权集成,形成强分类器:
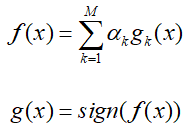
“”“”
在用Boosting进行提升学习过程中,不宜选择学习能力较强的模型,这样可能会导致提升没有意义或者不兼容,因为Boosting是让弱模型专注某一个方面,最后再进行集中表决,若使用较强的模型的模型,可能包含了多个方面,最后表决出现模棱两可的情况导致Boosting失去作用,可能模型在第一次产生模型就已经达到了最优,使得模型没有提升空间。
具体解释如下:Boosting的期望、方差可用下式表示:
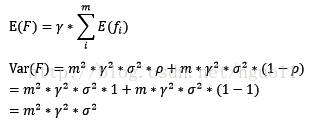
可以发现,当选取强模型时,其具有较大的方差δ,从而导致整体的方差变大,防止过拟合的能力变差,因此必须选择弱模型作为基分类器。从期望公式来看,随着基分类器的增多,整体期望也就越接近真实值,整体模型准确度提高。但准确率并不会无限逼近1,正因为随着训练的进行,整体的方差变大,防止过拟合能力变差,导致准确度下降。
所谓的比较弱的弱模型比如说是限制层数的决策树,最极端的情况下就是只有1个决策树桩的决策时(这一点有待商榷,在《Python机器学习实战》这本书中提到,使用决策树桩进行提升,就成为了提升树,但在其他资料中貌似没有看到生成提升树时需要特别注意树的深度的),选用该弱分类器就成为了提升树(Boosting Tree),提升树既可以用于分类也可用于回归。
新增:AdaBoost的推导过程
在这里补充上有关AdaBoost算法原理过程推导,以便于理解上述AdaBoost的迭代步骤。
首先,假设第m轮学习到的强学习器为fm(x),所学习到的弱分类器为Gm(x),那么由于模型是线性相加的,那么有:
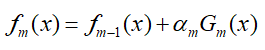
在m轮中的损失函数为L,由于AdaBoost使用的是指数损失函数,那么L可以表示为:
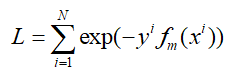
那么进一步,将fm(x)带入到损失函数中,开始对上式进行整理:
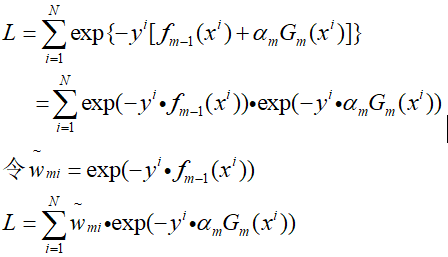
Gm(x)是弱分类器,那么其能够将样本分为-1和+1两类(假设为二分类的情况),则有:
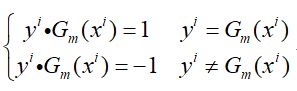
那么损失函数L可以改写为:

上面主要用到了全集和子集的关系变换。
然后求L对α的偏导数:
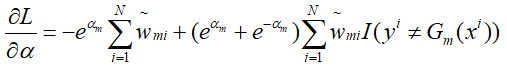
令其等于0,解得α:
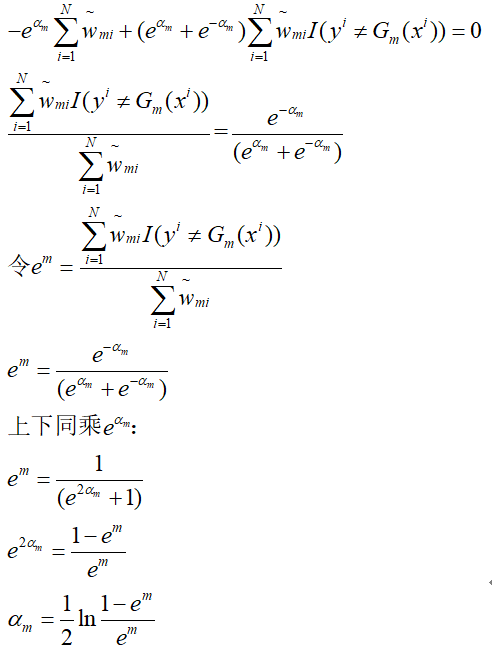
其中:
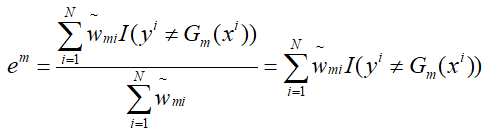
再由:

至此权重更新完毕,进入下一轮迭代,这里即为AdaBoost的推导过程。
提升树
提升树是Boosting的弱分类器采用决策树的一种算法,这里主要说明回归树,为后面GBDT做一个铺垫,提升树是通过拟合上一颗树的残差,生成一颗新的树,因此每次都仅有一个树桩。下面是提升树的生成原理。
假设上一轮所学习到最终的强分类器为fm-1(x)(叠加之后的),那么此时的损失函数为:
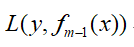
假设在本轮迭代中学习到的弱分类器hm(x),那么损失函数可以表示为(采用平方损失函数),通过最小化损失函数求hm(x):
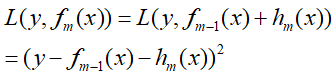
这里的y-fm-1(x)=r即为残差,这就表明每一次进行回归树生成时采用的训练数据都是上次预测结果与训练数据值之间的残差。这个残差会逐渐的减小。也就是说,让上式损失函数最小,只需遍历输出结果为残差的数据集可能产生的回归树桩,选出一颗使得和方差最小的树桩即可。
其具体算法如下:
- 初始化决策函数f0(x)=0;
- 对于迭代次数1~M:
- 计算残差:

-
- 拟合残差rmi,选择平方损失函数最小的切分点学习到一颗回归树,得到hm(x)
- 更新fm(x)=fm-1+hm(x)
- 最终得到提升树模型:
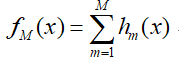
这里添加一个提升树建立过程的例子,例子来源于李航老师《统计学习方法》中, 有下面一组数据:
| x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| y | 5.56 | 5.70 | 5.91 | 6.40 | 6.80 | 7.05 | 8.90 | 8.70 | 9.0 | 9.05 |
现根据这组数据,构建一个提升树模型,首先,根据回归树的建立过程,划分x的值有1.5、2.5、3.5、4.5、5.5、6.5、7.5、8.5、9.5,那么每一个取值都能将数据分为两部分,那么取哪个数据呢?对于每个数据:
当x=1.5时:
将数据分为两部分{1}、{2,3,4,5,6,7,8,9,10},此时两个分支输出c1=5.56,c2=(5.7+5.91+6.4+6.8+7.05+8.9+8.7+9.0+9.05)/9=7.5;
当x=2.5时:
将数据分为{1,2}、{3,4,5,6,7,8,9,10},此时c1=(5.56+5.7)/2=5.63,c2=(5.91+6.4+6.8+7.05+8.9+8.7+9.0+9.05)/8=7.726;
依次类推,得到如下这张表:
| x' | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 | 9.5 |
| c1 | 5.56 | 5.63 | ... | ... | ... | ... | ... | ... | ... |
| c2 | 7.5 | 7.726 | ... | ... | ... | ... | ... | ... | ... |
然后根据每个划分情况,计算每个节点划分后的残差的总和,即:
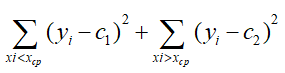
那么有ms(1.5)=(5.56-5.56)2+[(5.7-7.5)2+(5.91-7.5)2+(6.4-7.5)2+(6.8-7.5)2+(7.05-7.5)2+(8.90-7.5)2+(8.7-7.5)2+(9.0-7.5)2+(9.05-7.5)2]=15.72;依次类推求得如下一张表:
| x' | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 | 9.5 |
| ms | 15.72 | 12.08 | 8.36 | 5.78 | 3.91 | 1.93 | 8.01 |
11.73 |
15.74 |
然后发现当取值为6.5时ms最小,因此就以6.5作为划分值,将数据划分为两部分{1,2,3,4,5,6}、{7,8,9,10},并根据x=6.5时的输出值c1和c2,计算每个样本的残差,如表所示:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| -0.68 | -0.54 | -0.33 | 0.16 | 0.56 | 0.81 | -0.01 | -0.21 | 0.09 | 0.14 |
同时,这样就建立好了一棵树:
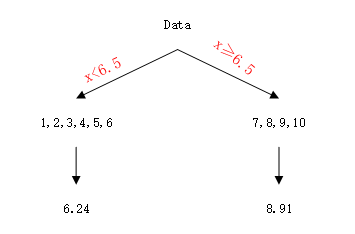
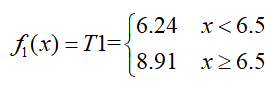
然后将上边的残差表那个数据作为新的训练数据,以此数据再建立一棵树,建立过程与上述完全一致,得到第二棵树:
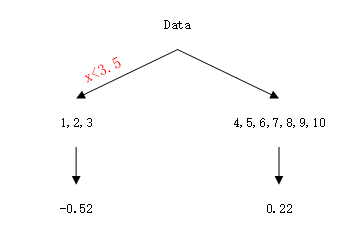
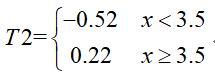
那么将f1(x)与T2相加,得到第二轮训练的强分类器:
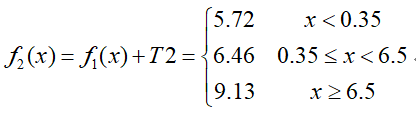
按照上述步骤再进行多轮训练,即可得到最终的强分类器f6 (x):

从上面过程可以看出,下一次训练是基于上一次训练的残差数据进行的。
暂时就先到这里吧,决策树和集成学习放在一起内容有点多,后边还有比较重要的GBDT和XGBoost,还有很多地方理解不是很透彻,继续学习。前一部分大概内容就是这样,不是很全面,后续会对这一块内容加深理解,会回头进行内容上的补充,也尽可能添加一些示例。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构