
OpenMLDB 发布线上到线下数据自动同步工具
OpenMLDB 正式发布线上到线下数据自动同步工具
OpenMLDB 作为一个线上线下一致的实时特征计算平台,通过合理的线上线下数据存储,确保线上到线下数据的一致性。由于线上和线下数据有不同性能和数据量的需求,通常情况下,OpenMLDB 的线上和线下的数据在物理上是分开存储。
在以前版本中,需要用户自行维护线上线下数据的同步和一致性,带来了一定的维护复杂度。近期,OpenMLDB v0.8.0 正式推出自动化线上到线下数据同步工具,实现了从实时数据库到离线数仓的自动同步,改进了手动维护的运维复杂度。下表总结了两种不同使用方式的优劣势。
| 线上线下数据同步方式 | 使用方式 | 优势 | 不足 |
|---|---|---|---|
| 手动维护和同步 | 默认使用方式 | 用户对于数据存储具备完全控制权,可以按照自己需求进行存储行为设计 | 一定的开发和维护复杂度,用户需要自己维护数据的写入、保证一致性等问题 |
| 线上到线下数据自动同步 | 单独配置同步工具 | 典型使用场景下更为易用,用户无需自己写代码实现线上到线下数据同步 | 目前版本的实时数据库仅支持磁盘表 |
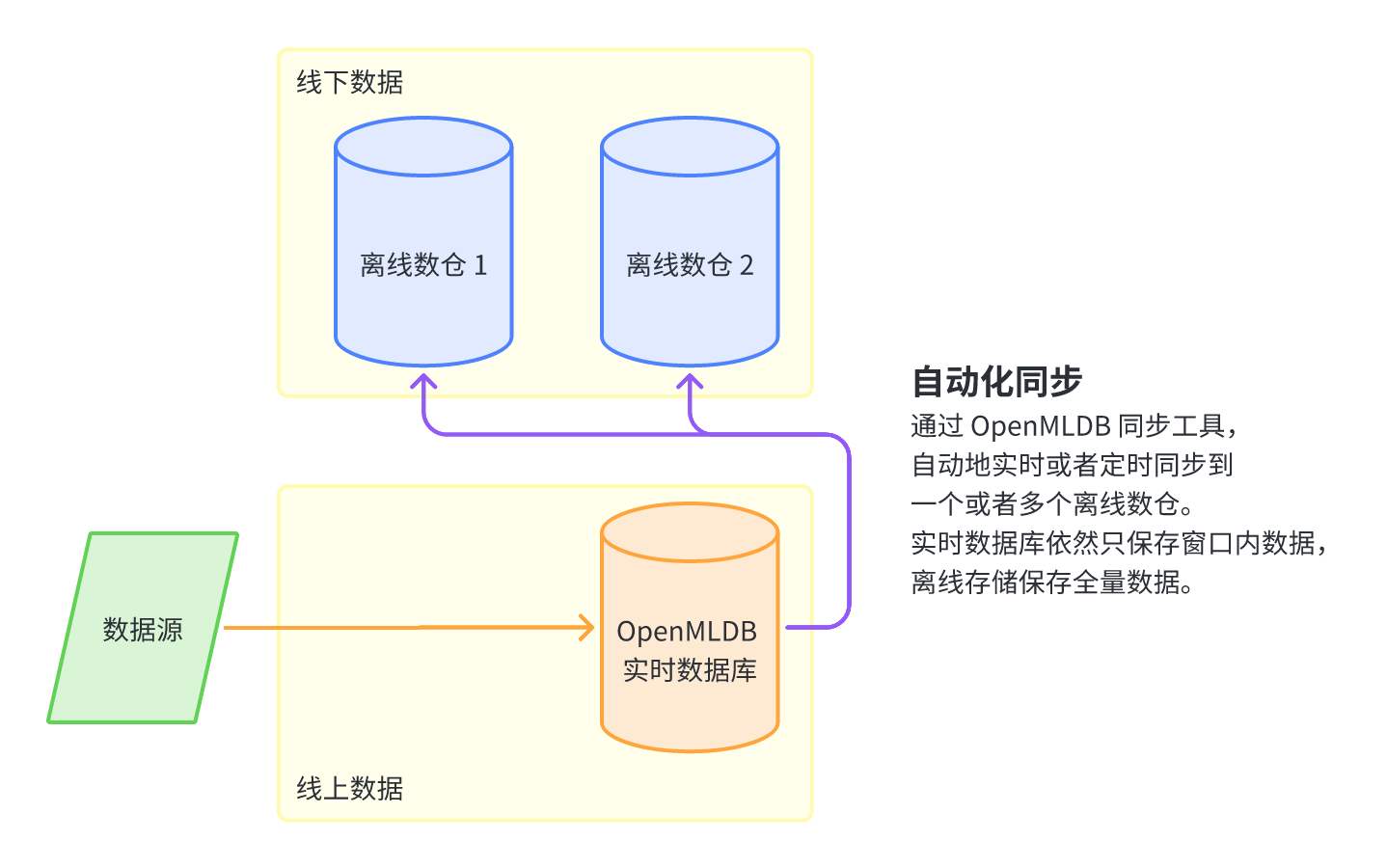
线上到线下数据存储自动化同步工具的架构如下图所示,用户只需要将新的数据写入 OpenMLDB 线上实时数据库,并设置好线上到线下的同步机制,OpenMLDB 即可自动化地将数据实时或者定时地同步至一个或者多个离线数仓。OpenMLDB 的实时数据库根据数据过期机制仅保存用于线上特征计算的数据,而离线数仓将保留所有全量数据。
线上到线下自动同步实战演示
使用线上到线下自动同步功能,需要在每台 TabletServer 所在机器上部署至少一台 DataCollector,用于收集在线数据。接收并写入离线存储的工具 SyncTool 可放于任何机器,目前仅支持单体运行。详细部署方式见最新产品相关文档(https://openmldb.ai/docs/zh/main/tutorial/online_offline_sync.html )。注意,目前在线存储仅支持磁盘表,离线支持写入到 HDFS。
接下来将以Docker镜像为例,展示在离线同步方式。主要分为以下四步:
- HDFS 环境配置,作为离线存储地址
- OpenMLDB 部署,包含同步组件
- 创建 OpenMLDB 线上到线下的同步任务
- 在线数据导入,并检查离线存储地址
步骤一:HDFS 环境配置
HADOOP安装参考 Pseudo-Distributed Operation,需配置JAVA_HOME和PDSH_RCMD_TYPE环境变量。为了简单起见,额外配置所有USER为当前用户root。因此安装步骤为:
curl -SLO https://archive.apache.org/dist/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
tar zxf hadoop-3.2.2.tar.gz
apt update && apt install ssh pdsh
service ssh start
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
echo -e "export HDFS_NAMENODE_USER=root\nexport HDFS_DATANODE_USER=root\nexport HDFS_SECONDARYNAMENODE_USER=root\nexport YARN_RESOURCEMANAGER_USER=root\nexport YARN_NODEMANAGER_USER=root\nexport JAVA_HOME=/usr/local/openjdk-11\nexport PDSH_RCMD_TYPE=ssh\n" >> hadoop-3.2.2/etc/hadoop/hadoop-env.sh
bash hadoop-3.2.2/sbin/start-dfs.sh
可以通过ps axu检查,应该存在3个HADOOP相关的进程。
步骤二:OpenMLDB 部署
OpenMLDB的部署使用/work/init.sh,配置离线可以读取HDFS集群,离线表默认存储地址可不更改,后面可以软链接的方式加载离线地址。虽然有两个TabletServer,但实际只有一台机器,所以DataCollector只需要一个。注意init.sh启动的TabletServer IP为 localhost,我们需要将 DataCollector的IP也改为 localhost,端口使用默认端口。启动DataCollector后再启动SyncTool,SyncTool需要注意HADOOP配置的读取,这里直接设置读取HADOOP安装目录中的配置文件。
export HADOOP_CONF_DIR=/work/hadoop-3.2.2/etc/hadoop/
/work/init.sh
cd /work/openmldb
sed -i'' 's/endpoint=127.0.0.1/endpoint=localhost/g' conf/data_collector.flags
bash bin/start.sh start data_collector
sed -i'' 's#hadoop.conf.dir=.*#hadoop.conf.dir=/work/hadoop-3.2.2/etc/hadoop/#g' conf/synctool.properties
bash bin/start.sh start synctool
步骤三:创建同步任务
在OpenMLDB中创建磁盘表,才能进行同步任务的创建。参考OpenMLDB快速上手,创建一个磁盘表。
CREATE DATABASE demo_db;
USE demo_db;
CREATE TABLE demo_table1(c1 string, c2 int, c3 bigint, c4 float, c5 double, c6 timestamp, c7 date, INDEX(KEY=c1, TS=c6)) OPTIONS (storage_mode='HDD');
使用tools/synctool_helper.py来管理同步任务,由于SyncTool使用默认IP,所以以下命令均可以不填写-s。
创建同步任务,可以对某一张表创建同步任务,并且有三种同步模式可以选择,同时还需要填写SyncTool地址和离线数据地址。其中,离线数据地址指SyncTool可读取的HDFS地址,所以,需要SyncTool处有HDFS配置,地址不需要hdfs://路径开头。如果存入hdfs://<cluster>/tmp/hdfs-dest则填写/tmp/hdfs-dest。
# mode 0: 全量同步,在某一时刻无新数据读取时,将停止同步
python3 tools/synctool_helper.py create -t db.table -m 0 -s <sync tool endpoint> -d /tmp/hdfs-dest
# mode 1: 持续同步,同步任务将一直存在,并且对所有数据进行ts的筛选,例如-t时间为2023/7/18 00:00:00.000,则所有早于此的数据将不会被同步到离线
python3 tools/synctool_helper.py create -t db.table -m 1 -ts 233 -s <sync tool endpoint> -d /tmp/hdfs-dest
# mode 2: 持续同步,同步任务将一直存在,所有在线数据将同步到离线
python3 tools/synctool_helper.py create -t db.table -m 2 -s <sync tool endpoint> -d /tmp/hdfs-dest
在容器中,创建这样一个同步任务:
python3 tools/synctool_helper.py create -t demo_db.demo_table1 -m 2 -d /tmp/hdfs-dest
步骤四:同步任务测试和验证
同步任务创建后,可以使用以下命令查询任务状态。
python3 tools/synctool_helper.py status
可以看到该表的所有分区同步任务,也可以看到它们是否处于正常运行状态。
8 tasks(tid-pid)
{'lastUpdateTime': '2023-07-18 07:01:07.589000', 'progressPath': '/tmp/sync_task_progress/7/0.progress', 'tid': 7, 'pid': 0, 'mode': 'kFullAndContinuous', 'startTs': '0', 'syncPoint': {'type': 'kBINLOG', 'offset': '1'}, 'tabletEndpoint': 'localhost:10922', 'desEndpoint': '0.0.0.0:8848', 'token': '3e8e9997-5608-4106-bfc3-6923ac0b6939', 'dest': '/tmp/hdfs-dest', 'dataCollector': 'localhost:8888', 'count': '0', 'status': 'RUNNING'}
... // other 7 tasks
table scope
running tasks:
tid 7 task is running, pid parts: dict_keys([0, 1, 2, 3, 4, 5, 6, 7])
all tasks are running
此时HADOOP上还没有数据,仅创建了目录,可以通过以下方式查询。
/work/hadoop-3.2.2/bin/hdfs dfs -ls /tmp/hdfs-dest
在线数据导入
SET @@execute_mode='online';
LOAD DATA INFILE 'file:///work/taxi-trip/data/data.parquet' INTO TABLE demo_table1 options(format='parquet', mode='append');
离线结果检查
可以用dfs的方式检查数据是否同步,可以得到在线数据的所有数据,共10行。
/work/hadoop-3.2.2/bin/hdfs dfs -cat /tmp/hdfs-dest/* | wc -l
更常见的方式,可以将此地址作为离线数据软链接,使离线端可以使用数据。
USE demo_db;
LOAD DATA INFILE 'hdfs:///tmp/hdfs-dest' INTO TABLE demo_table1 options(format='csv', header=false, deep_copy=false, mode='append');
DESC demo_table1;
SET @@sync_job=true;
SELECT * FROM demo_table1;
因为同步任务是持续的,再进行在线LOAD DATA或INSERT,数据将持续同步到离线地址,直到同步任务被删除。注意,磁盘表如果索引相同,会进行覆盖(更多信息参考磁盘表),不会增加数据行数,所以不要重复导入同样的数据进行测试,同步工具将追加数据到离线,不会进行覆盖。
关注 OpenMLDB
OpenMLDB 官网:
https://openmldb.ai/
OpenMLDB GitHub 主页:
https://github.com/4paradigm/OpenMLDB
OpenMLDB 文档:
https://openmldb.ai/docs/zh/
OpenMLDB 微信交流群


 浙公网安备 33010602011771号
浙公网安备 33010602011771号